一种图像处理方法、装置和显示器与流程
本发明实施例涉及图像处理,尤其涉及一种图像处理方法、装置和显示器。
背景技术:
1、为了更好地认识这个纷繁复杂的世界,人类进化出了一套独特的视觉系统——中央凹成像系统,即当我们看东西时,眼睛聚焦的地方会看得更加清晰,而对于周围区域只能看个大概,这种成像方式既能让我们看清关键物体的细节,又能具有较大的视野。
2、现阶段为了用户在观看图像时能够更加清晰,通常会对图像的全局进行增强,这就使得图像全局增强与人眼局部集中观察的特点不匹配,因此存在全局增强算力浪费、交互体验不足的问题。
技术实现思路
1、本发明实施例提供一种图像处理方法、装置和显示器,解决了现有技术中对图像全局进行增强与人眼局部集中观察的特点不匹配所带来的全局算力浪费、用于交互体验感较差的技术问题。
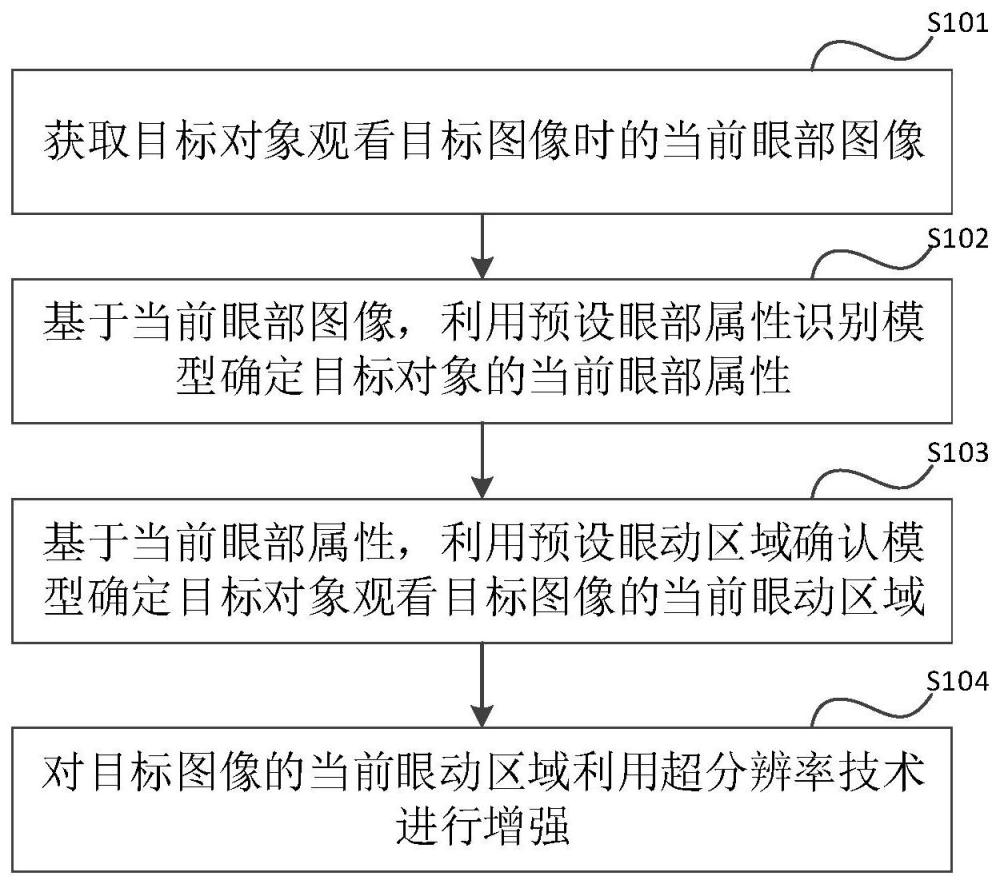
2、本发明实施例提供了一种图像处理方法,所述图像处理方法包括:
3、获取目标对象观看目标图像时的当前眼部图像;
4、基于所述当前眼部图像,利用预设眼部属性识别模型确定所述目标对象的当前眼部属性,其中,所述当前眼部属性包括所述目标对象的看图主眼、瞳孔尺寸、瞳孔占比、瞳距中的至少一项,所述预设眼部属性识别模型为利用深度学习算法训练得到的用于确定眼部图像与眼部属性之间关系的模型;
5、基于所述当前眼部属性,利用预设眼动区域确认模型确定所述目标对象观看所述目标图像的当前眼动区域,其中,所述当前眼动区域指所述目标对象的眼部当前聚焦所述目标图像的区域,所述预设眼动区域确认模型为为利用深度学习算法训练得到的用于确定眼部属性与眼动区域之间关系的模型;
6、对所述目标图像的所述当前眼动区域利用超分辨率技术进行增强。
7、进一步地,对所述目标图像的所述当前眼动区域利用超分辨率技术进行增强包括:
8、利用以下算法之一对所述当前眼动区域进行超分辨率增强:生成对抗网络、自动编码算法、稀疏编码算法。
9、进一步地,所述预设眼部属性识别模型的建立方法包括:
10、获取第一预设数量个观察者观看预设图像时的眼部图像;
11、确定每个所述眼部图像的眼部区域,并基于所述眼部区域建立眼动中心坐标;
12、基于所述眼部区域确定眼部属性,其中,所述眼部属性包括看图主眼、瞳孔尺寸、瞳孔占比、瞳距中的至少一项;
13、基于所述眼动中心坐标以及所述眼部属性,利用深度学习算法训练得到所述预设眼部属性识别模型。
14、进一步地,所述预设眼动区域确认模型的建立方法包括:
15、在获取第一预设数量个观察者观看预设图像时的眼部图像的同时,获取观察者在每次观看预设图像时的眼动区域,其中,所述眼动区域为所述观察者在观看所述预设图像时标注出的区域;
16、基于所述眼动中心坐标、所述眼部属性以及所述眼动区域,利用深度学习算法训练得到所述预设眼动区域确认模型。
17、进一步地,获取目标对象观看目标图像时的当前眼部图像包括:
18、利用具有红外成像功能的图像获取设备获取所述目标对象观看所述目标图像时的所述当前眼部图像。
19、进一步地,在对所述目标图像的所述当前眼动区域利用超分辨率技术进行增强之后,所述图像处理方法还包括:
20、将对所述当前眼动区域进行增强后的所述目标图像传送给显示器进行显示。
21、本发明实施例还提供了一种图像处理装置,所述图像处理装置包括:
22、图像获取单元,用于获取目标对象观看目标图像时的当前眼部图像;
23、属性确定单元,用于基于所述当前眼部图像,利用预设眼部属性识别模型确定所述目标对象的当前眼部属性,其中,所述当前眼部属性包括所述目标对象的看图主眼、瞳孔尺寸、瞳孔占比、瞳距中的至少一项,所述预设眼部属性识别模型为利用深度学习算法训练得到的用于确定眼部图像与眼部属性之间关系的模型;
24、区域确定单元,用于基于所述当前眼部属性,利用预设眼动区域确认模型确定所述目标对象观看所述目标图像的当前眼动区域,其中,所述当前眼动区域指所述目标对象的眼部当前聚焦所述目标图像的区域,所述预设眼动区域确认模型为为利用深度学习算法训练得到的用于确定眼部属性与眼动区域之间关系的模型;
25、图像局部增强单元,用于对所述目标图像的所述当前眼动区域利用超分辨率技术进行增强。
26、本发明实施例还提供了一种显示器,所述显示器包括上述任意实施例所述的图像处理装置。
27、本发明实施例公开了一种图像处理方法、装置和显示器,方法包括:获取目标对象观看目标图像时的当前眼部图像;基于当前眼部图像,利用预设眼部属性识别模型确定目标对象的当前眼部属性;基于当前眼部属性,利用预设眼动区域确认模型确定目标对象观看目标图像的当前眼动区域;对目标图像的当前眼动区域利用超分辨率技术进行增强。本申请通过建立目标对象的关注区域与其眼部属性的深度学习模型,并对深度学习检测出的目标对象的关注区域进行局部图像超分辨增强,解决了现有技术中对图像全局进行增强与人眼局部集中观察的特点不匹配所带来的全局算力浪费、用于交互体验感较差的技术问题,实现了节约非必要算力、提升用户的显示交互体验的技术效果。
技术特征:
1.一种图像处理方法,其特征在于,所述图像处理方法包括:
2.根据权利要求1所述的图像处理方法,其特征在于,对所述目标图像的所述当前眼动区域利用超分辨率技术进行增强包括:
3.根据权利要求1所述的图像处理方法,其特征在于,所述预设眼部属性识别模型的建立方法包括:
4.根据权利要求3所述的图像处理方法,其特征在于,所述预设眼动区域确认模型的建立方法包括:
5.根据权利要求1所述的图像处理方法,其特征在于,获取目标对象观看目标图像时的当前眼部图像包括:
6.根据权利要求1所述的图像处理方法,其特征在于,在对所述目标图像的所述当前眼动区域利用超分辨率技术进行增强之后,所述图像处理方法还包括:
7.一种图像处理装置,其特征在于,所述图像处理装置包括:
8.一种显示器,其特征在于,所述显示器包括上述权利要求7所述的图像处理装置。
技术总结
本发明实施例公开了一种图像处理方法、装置和显示器,方法包括:获取目标对象观看目标图像时的当前眼部图像;基于当前眼部图像,利用预设眼部属性识别模型确定目标对象的当前眼部属性;基于当前眼部属性,利用预设眼动区域确认模型确定目标对象观看目标图像的当前眼动区域;对目标图像的当前眼动区域利用超分辨率技术进行增强。通过建立目标对象的关注区域与其眼部属性的深度学习模型,并对深度学习检测出的目标对象的关注区域进行局部图像超分辨增强,解决了现有技术中对图像全局进行增强与人眼局部集中观察的特点不匹配所带来的全局算力浪费、用于交互体验感较差的技术问题,实现了节约非必要算力、提升用户的显示交互体验的技术效果。
技术研发人员:宋思远,穆欣炬,马中生,高裕弟,刘宏俊
受保护的技术使用者:义乌清越光电技术研究院有限公司
技术研发日:
技术公布日:2024/3/4
- 还没有人留言评论。精彩留言会获得点赞!