一种意图理解系统及其训练方法与流程
本发明涉及机器学习,特别是涉及一种意图理解系统及其训练方法。
背景技术:
1、在人机交互场景下,通常采用自然语言进行交互。在交互过程中,机器准确理解用户的真实意图是系统的关键功能。只有当机器能够快速、准确地理解用户的意图时,才能带来较佳的用户使用体验,进而可以进行持续的交互。在人机交互的意图理解领域中,目前存在着两种主要技术:预先训练型人机交互系统和增量适应型人机交互系统。
2、预先训练型人机交互系统是指在系统部署前,对其进行离线训练,以学习并固化预定义的指令和意图模式。这些模型通常基于大规模的语料库进行训练,例如用于语音识别和自然语言理解的深度学习模型。系统一旦部署后无法在实时交互中学习,也不能适应用户新增意图和纠正理解错误意图。预先训练型人机交互系统的训练阶段是固定的,无法动态更新。因此,这些系统无法对用户新增意图进行识别,也无法快速纠正长期无法精准识别的意图,导致用户体验的下降。
3、增量适应型人机交互系统是指一些尝试在系统部署后,通过增量学习和更新模型来适应用户新增及纠正意图的系统。该类系统采用增量学习的技术,根据实时交互数据来调整模型。虽然这些方法能够适应用户新增、纠正意图,但由于增量学习的复杂性和训练数据的限制,很难实现实时的更新,导致系统无法快速适应用户的新需求。
4、针对上述现有技术的问题,本申请提出了一种在自然语言场景下识别用户新增意图、纠正错误意图的意图理解系统及其训练方法,其结合了预先训练和增量学习两种技术的优势,在充分学习现有意图样本的基础上,能够快速学习用户的新意图。
技术实现思路
1、(一)发明目的
2、本申请的目的是在现有系统的基础上,研发出一种能够实现在预先训练模型的基础上,支持快速增量学习的意图理解系统及其训练方法。
3、(二)技术方案
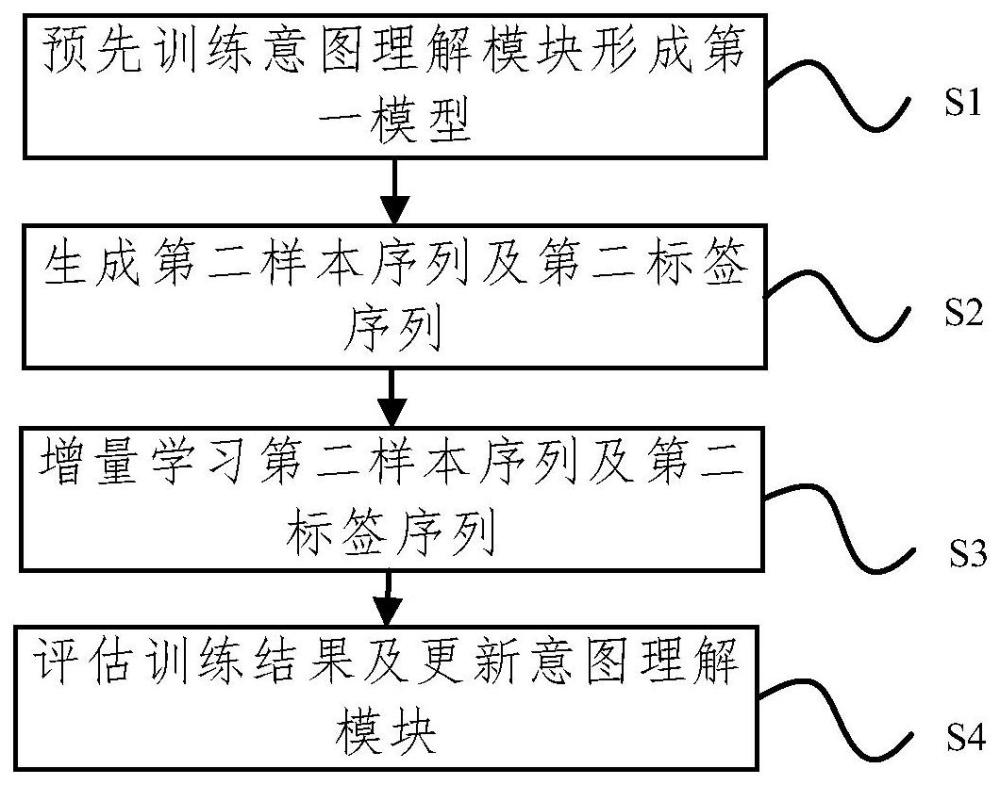
4、根据一些实施例,本发明的第一方面提供了一种意图理解系统训练方法,包括:将第一样本及第一标签送入意图识别模块进行训练形成第一模型;将第二样本及第二标签通过大规模语言模型生成第二样本序列及第二标签序列,第二样本序列为包含第二样本的样本集合,第二标签序列为包含第二标签的标签集合;对第二样本序列及第二标签序列进行增量学习输出第二模型和模型评估结果;根据模型评估结果,将第二模型应用于意图识别模块。。
5、在一个实施例中,将第二样本及第二标签通过大规模语言模型生成第二样本序列及第二标签序列之前,包括:将第二样本及第二标签送入消息队列;从消息队列中按照顺序取出第二样本及第二标签用于生成第二样本序列及第二标签序列。
6、在一个实施例中,将第二样本及第二标签送入消息队列之前,还包括:将输入信息进行模式识别产生文本形式的第二样本及第二标签。
7、在一个实施例中,第二样本及第二标签通过大规模语言模型生成第二样本序列及第二标签序列的步骤,包括:通过提示工程预置提示,以生成不同表达方式的第二样本序列及第二标签序列。
8、在一个实施例中,预置提示包括以下中的至少一种:语法提示,修改第二样本的表达语法;口语化提示,将第二样本的表达内容口语化;实体替代提示,将第二样本中的实体词泛化替代;行为提示,将第二样本的表达内容转换为行为描述;逻辑提示,将第二样本的表达内容生成逻辑对话。
9、在一个实施例中,对第二样本序列及第二标签序列进行增量学习输出第二模型和模型评估结果之前,包括:将第三样本插入第二样本序列,第三标签插入第二标签序列,其中,第三样本和第三标签为意图识别模块的历史训练数据。
10、在一个实施例中,对第二样本序列及第二标签序列进行增量学习输出第二模型和模型评估结果的步骤,包括:采用联合训练的深度模型,在前一个版本的模型基础上冻结词、句信息层,调整语义表达层进行增量学习。
11、根据一些实施例,本发明的第二方面提供了一种意图理解系统,包括:意图识别模块,其通过第一样本及第一标签训练形成第一模型;数据生成模块,其用于将第二样本及第二标签通过大规模语言模型生成第二样本序列及第二标签序列,第二样本序列为包含第二样本的样本集合,第二标签序列为包含第二标签的标签集合;增量训练模块,其用于对第二样本序列及第二标签序列进行增量学习输出第二模型和模型评估结果;评估应用模块,其用于根据模型评估结果,将第二模型应用于意图识别模块。。
12、在一个实施例中,数据生成模块被进一步配置为:将第二样本及第二标签送入消息队列;从消息队列中按照顺序取出第二样本及第二标签用于生成第二样本序列及第二标签序列。
13、在一个实施例中,系统还包括:识别模块,其用于将输入信息进行模式识别产生文本形式的第二样本及第二标签。
14、在一个实施例中,数据生成模块被进一步配置为:通过提示工程预置提示,以生成不同表达方式的第二样本序列及第二标签序列。
15、在一个实施例中,数据生成模块中的提示工程包括以下至少一种:语法提示,修改第二样本的表达语法;口语化提示,将第二样本的表达内容口语化;实体替代提示,将第二样本中的实体词泛化替代;行为提示,将第二样本的表达内容转换为行为描述;逻辑提示,将第二样本的表达内容生成逻辑对话。
16、在一个实施例中,数据生成模块被进一步配置为:将第三样本插入第二样本序列,第三标签插入第二标签序列,其中,第三样本和第三标签为意图识别模块的历史训练数据。
17、在一个实施例中,增量训练模块被进一步配置为:采用联合训练的深度模型,在前一个版本的模型基础上冻结词、句信息层,调整语义表达层进行增量学习。
18、根据一些实施例,本发明的第三方面提供了一种电子设备,包括:存储器,其上存储有计算机程序;处理器,用于执行存储器中的计算机程序,以实现本发明第一方面方法的步骤。
19、根据一些实施例,本发明的第四方面提供了一种存储介质,其上存储有计算机程序指令,该程序指令被处理器执行时实现本发明第一方面方法的步骤。
20、(三)有益效果
21、本发明的上述技术方案具有如下有益的技术效果:通过第一样本对系统的意图识别模块进行预先训练;通过大规模语言模型扩充第二样本,在预先训练的基础上,实时进行第二样本的增量学习;缓解了现有系统无法快速学习新意图的技术问题,实现了单一样本的增量学习。
22、应当理解的是,以上的一般描述和后文的细节描述仅是示例性和解释性的,并不能限制本公开。
技术特征:
1.一种意图理解系统训练方法,其特征在于,包括:
2.根据权利要求1所述的方法,其特征在于,将所述第二样本及第二标签通过大规模语言模型生成第二样本序列及第二标签序列之前,包括:
3.根据权利要求2所述的方法,其特征在于,将所述第二样本及第二标签送入消息队列之前,还包括:
4.根据权利要求1所述的方法,其特征在于,所述第二样本及第二标签通过大规模语言模型生成第二样本序列及第二标签序列的步骤,包括:
5.根据权利要求4所述的方法,其特征在于,所述的预置提示,包括以下中的至少一种:
6.根据权利要求1所述的方法,其特征在于,对所述第二样本序列及第二标签序列进行增量学习输出第二模型和模型评估结果之前,包括:
7.根据权利要求1所述的方法,其特征在于,对所述第二样本序列及第二标签序列进行增量学习输出第二模型和模型评估结果的步骤包括:
8.一种意图理解系统,其特征在于,包括:
9.根据权利要求8所述的系统,其特征在于,所述数据生成模块被进一步配置为:
10.根据权利要求8所述的系统,其特征在于,还包括:
11.根据权利要求8所述的系统,其特征在于,所述数据生成模块被进一步配置为:
12.根据权利要求11所述的系统,其特征在于,所述数据生成模块中的提示工程包括以下至少一种:
13.根据权利要求8所述的系统,其特征在于,所述数据生成模块被进一步配置为:
14.根据权利要求8所述的系统,其特征在于,所述增量训练模块被进一步配置为:
15.一种电子设备,其特征在于,包括:
16.一种计算机可读存储介质,其上存储有计算机程序指令,其特征在于,该程序指令被处理器执行时实现权利要求1~7中任一项所述方法的步骤。
技术总结
本申请公开了一种意图理解系统及其训练方法,该训练方法包括:将第一样本及第一标签送入意图识别模块进行训练形成第一模型;将第二样本及第二标签通过大规模语言模型生成第二样本序列及第二标签序列;对第二样本序列及第二标签序列进行增量学习输出第二模型和模型评估结果;根据模型评估结果,将第二模型应用于意图识别模块。本申请提出的技术方案,通过第一样本对系统的意图识别模块进行预先训练;通过大规模语言模型扩充第二样本,在预先训练的基础上,实时进行第二样本的增量学习;缓解了现有系统无法快速学习新意图的技术问题,实现了单一样本的增量学习。
技术研发人员:史元春,汪贤龙,陶品,兴军亮,张晓川
受保护的技术使用者:启元实验室
技术研发日:
技术公布日:2024/3/27
- 还没有人留言评论。精彩留言会获得点赞!