一种采用AI算力加速图形流水线中混合过程的方法与流程
本发明属于图形处理,具体为一种采用ai算力加速图形流水线中混合过程的方法。
背景技术:
1、图形处理器(graphics processing unit,gpu)是计算机中专门用于处理图形相关计算任务的部件,相比于cpu,gpu将计算资源更多的分配在计算部分而非控制部分上,并且尽可能的利用了图形计算处理任务中的并行性,因此,在图形处理任务上能具有比cpu快很多的计算能力,因此也被广泛地运用于人工智能相关的计算中。随着ai的兴起,gpu除了原有的用于通用计算和图形处理的处理单元外,还通常会集成专门用于ai相关计算的神经处理器(neural processing unit,npu)或者张量核(tensor core)等,因为它们都是为了ai相关计算加速而设计的,本发明中将它们统一称为ai算力单元。
2、但是目前通常采用专门的rop单元来进行颜色混合,这无疑带来了额外的芯片面积和数据传输成本,而仅进行图形相关的计算时,ai算力单元处于闲置状态,这也是对其巨大性能的浪费。
技术实现思路
1、本发明的目的在于:为了解决上述提出的问题,提供一种采用ai算力加速图形流水线中混合过程的方法。
2、本发明采用的技术方案如下:一种采用ai算力加速图形流水线中混合过程的方法,所述采用ai算力加速图形流水线中混合过程的方法包括以下步骤:
3、s1:按照s2-s4所述步骤进行数据结构的分块,将片元直接保存在片上内存中,直到达到一定的批数n;
4、s2:将整个屏幕空间切分为若干个块,当有片元落在块中的时候,将n个批次的该块的片元数据按照图2的要求保存到内存中,对于块中没有片元的区域,将其颜色分量全部设为0;
5、s3:块的大小是与应用场景相关的经验值;对于没有任何片元落入的块,则不进行计算;
6、s4:如果某个批次片元中没有任何片元落入到某个块中,则在该块保存的数据中,可以去除该批次片元对应的一层;
7、s5:进行权重计算,先计算每一批次中每个片元的权重,即在颜色混合中相应片元颜色的占比;可以直接将混合公式中的减法视作权重的一部分,相当于权重为负数;
8、s6:采用ai算力单元完成相应的计算;在计算过程中,将每一个块中每个批次中所有片元对应的各个颜色分量数据按照一个矩阵处理,用表示第n批次的四个矩阵;
9、s7:首先,计算所有批次的源和目的混合因子f,除混合函数src_alpha_saturate外,其他混合函数都可以使用ai算力单元进行逐元素加操作完成;
10、s8:src_alpha_saturate可以使用ai算力单元进行逐元素加操作后再进行逐元素比较操作完成;然后,对除深度最小的层外的所有层的混合因子,通过ai算力单元进行逐元素加操作计算(1-f);最后,使用ai算力单元进行逐元素乘操作,计算所有批次使用的权重矩阵,以源混合函数为src_alpha,目标混合函数为one_minus_src_alpha的情况为例:
11、
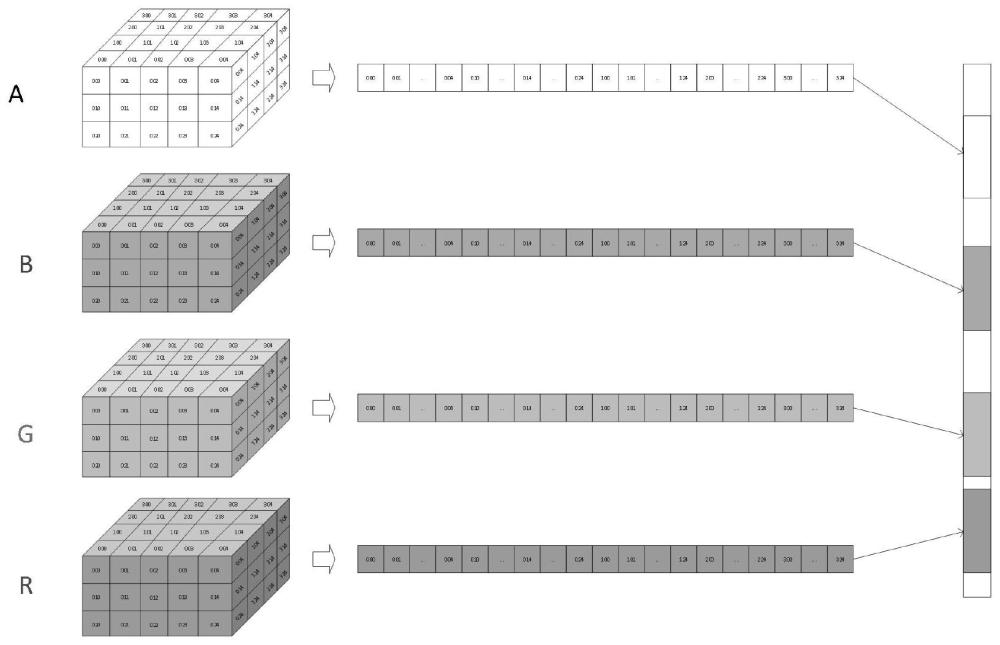
12、
13、其中wn表示权重矩阵,n表示所对应的批次,表示对应批次的源不透明度矩阵,所有操作都为逐元素操作;
14、s9:完成权重计算后,进行混合计算;
15、s10:最后,使用逐元素比较操作,将结果钳位到0到1的范围内,即完成了颜色混合,之后即可结束整个采用ai算力加速图形流水线中混合过程。
16、在一优选的实施方式中,所述步骤s1中,能够让颜色混合过程具有足够的计算并行性,虽然这需要占用更多的片上内存空间,但是前述的共享的片上内存容量完全可以满足需求。
17、在一优选的实施方式中,所述步骤s2中,片元数据在片上内存空间的数据结构如图2所示;其中,标识一个元素的三个数字从左到右分别为所在的批次z(由于经过深度测试,各个批次间片元的深度关系是一定的,本发明中,按批次z越小,相应片元的深度越小来组织),屏幕坐标系下的纵坐标y,屏幕坐标系下的横坐标x;每个元素为一个片元的颜色的一个分量,可以是红色r、绿色g、蓝色b、不透明度a之一。
18、在一优选的实施方式中,所述步骤s4中,在内存中,n批次的全部片元的同一颜色分量连续的保存为一个数组,坐标顺序为先在x上增加,其次为y,最后为z;不同颜色分量的数组不要求连续;
19、如图3所示,一个批次中,图元形状可能是不规则的,其所产生的片元并不一定可以像图2所示的一样规则的保存。
20、在一优选的实施方式中,所述步骤s5中,对于混合函数为zero、one、constant_color、one_minus_constant_color、constant_alpha、one_minus_constant_alpha的情况,同一批次的所有片元的权重都是一致的,因此,只需要迭代计算权重就可以;例如,对源混合因子采用constant_alpha,目标混合因子采用one_minus_constant_alpha的情况,有
21、
22、
23、其中wn表示权重,n表示所对应的批次,表示对应批次采用的常量不透明度,由混合函数决定;
24、这种情况下,由于运算量很小且可以预先确定,可以预先完成计算。
25、在一优选的实施方式中,所述步骤s5中,对于混合函数为src_color、one_minus_src_color、dst_color、one_minus_dst_color、src_alpha、one_minus_src_alpha、dst_alpha、one_minus_dst_alpha、src_alpha_saturate的情况,同一批次每个片元的权重都是不同的,有:
26、
27、
28、其中,x和y表示某个片元的屏幕坐标。
29、在一优选的实施方式中,所述步骤s9中,进行混合计算的方法为:将颜色分量矩阵视为特征值张量,将对应的权重矩阵视为权值张量,进行一次卷积核大小等于块大小的二维卷积操作。
30、在一优选的实施方式中,所述步骤s9中,进行混合计算的方法为:将颜色分量矩阵和权重矩阵逐批次使用ai算力单元进行逐元素乘,然后是使用ai算力单元逐层将结果进行逐元素加。
31、综上所述,由于采用了上述技术方案,本发明的有益效果是:
32、本发明中,提出了一种利用ai算力单元进行颜色混合计算的方法,以利用ai算力单元来实现颜色混合计算的加速,并减少相关的专用硬件模块,降低gpu芯片的面积成本,利用ai算力单元来实现颜色混合计算的加速,并减少相关的专用硬件模块,降低gpu芯片的面积成本。
技术特征:
1.一种采用ai算力加速图形流水线中混合过程的方法,其特征在于:所述采用ai算力加速图形流水线中混合过程的方法包括以下步骤:
2.如权利要求1所述的一种采用ai算力加速图形流水线中混合过程的方法,其特征在于:所述步骤s1中,能够让颜色混合过程具有足够的计算并行性。
3.如权利要求1所述的一种采用ai算力加速图形流水线中混合过程的方法,其特征在于:所述步骤s2中,片元数据在片上内存空间的数据结构如图2所示;其中,标识一个元素的三个数字从左到右分别为所在的批次z(由于经过深度测试,各个批次间片元的深度关系是一定的,本发明中,按批次z越小,相应片元的深度越小来组织),屏幕坐标系下的纵坐标y,屏幕坐标系下的横坐标x;每个元素为一个片元的颜色的一个分量,可以是红色r、绿色g、蓝色b、不透明度a之一。
4.如权利要求1所述的一种采用ai算力加速图形流水线中混合过程的方法,其特征在于:所述步骤s4中,在内存中,n批次的全部片元的同一颜色分量连续的保存为一个数组,坐标顺序为先在x上增加,其次为y,最后为z;不同颜色分量的数组不要求连续。
5.如权利要求1所述的一种采用ai算力加速图形流水线中混合过程的方法,其特征在于:所述步骤s5中,对于混合函数为zero、one、constant_color、one_minus_constant_color、constant_alpha、one_minus_constant_alpha的情况,同一批次的所有片元的权重都是一致的,因此,只需要迭代计算权重就可以;对源混合因子采用constant_alpha,目标混合因子采用one_minus_constant_alpha的情况,有
6.如权利要求1所述的一种采用ai算力加速图形流水线中混合过程的方法,其特征在于:所述步骤s5中,对于混合函数为src_color、one_minus_src_color、dst_color、one_minus_dst_color、src_alpha、one_minus_src_alpha、dst_alpha、one_minus_dst_alpha、src_alpha_saturate的情况,同一批次每个片元的权重都是不同的,有:
7.如权利要求1所述的一种采用ai算力加速图形流水线中混合过程的方法,其特征在于:所述步骤s9中,进行混合计算的方法为:将颜色分量矩阵视为特征值张量,将对应的权重矩阵视为权值张量,进行一次卷积核大小等于块大小的二维卷积操作。
8.如权利要求1所述的一种采用ai算力加速图形流水线中混合过程的方法,其特征在于:所述步骤s9中,进行混合计算的方法为:将颜色分量矩阵和权重矩阵逐批次使用ai算力单元进行逐元素乘,然后是使用ai算力单元逐层将结果进行逐元素加。
技术总结
本发明公开了一种采用AI算力加速图形流水线中颜色混合过程的方法。本发明中,先进行数据结构的分块,将片元直接保存在片上内存中,直到达到一定的批数N,然后一次性由AI算力单元完成整个颜色混合过程;将整个屏幕切分为若干个块,当有片元落在块中的时候,将N个批次的该块的片元数据按照图2的要求保存到内存中,对于块中没有片元的区域,将其颜色分量全部设为0;块的大小是与应用场景相关的经验值。以利用AI算力单元来实现颜色混合计算的加速,并减少相关的专用硬件模块,降低GPU芯片的面积成本,利用AI算力单元来实现颜色混合计算的加速,并减少相关的专用硬件模块,降低GPU芯片的面积成本。
技术研发人员:徐瑞,项天
受保护的技术使用者:苏州速显微电子科技有限公司
技术研发日:
技术公布日:2024/4/24
- 还没有人留言评论。精彩留言会获得点赞!