高质量轻量级无监督深度估计网络模型设计方法
本发明涉及计算机视觉领域,尤其涉及一种高质量轻量级无监督深度估计网络模型设计方法。
背景技术:
1、深度估计能够估计图像中每个像素点相对于拍摄源的距离,它在三维重建、虚拟现实、自动驾驶、机器人导航、增强现实等领域中有着广泛的应用。深度估计的方法分为传统方法和基于深度学习方法。传统方法包括三角测量、运动恢复结构(sfm)和3d传感器等。基于深度学习的深度估计分为有监督和无监督两种。
2、传统方法的深度估计在复杂场景下对存在弱纹理、遮挡、反射等情况时,精度就会大打折扣。基于深度学习的有监督深度估计需要大量的真实标签,而现实当中往往很难获取大量的真实标签,这种方法不能广泛应用于实际当中。而现有的无监督的方法存在精度低、伪影严重、推理速度慢等问题。
3、针对上述研究状况,本发明提供了一种高质量轻量级无监督深度估计网络模型。该网络的训练无需真实标签,并且在kitti数据集上的测试精度与对比的无监督深度估计相比,其精度更高、推理速度更快,对于分辨率大小为1152×256的图像,推理速度达到46fps,达到了实际应用的实时速度。
技术实现思路
1、本发明的目的在于提供一种高质量轻量级无监督深度估计网络模型设计方法,无需真实标签训练网络,并且能够快速获得物体轮廓清晰的深度图。
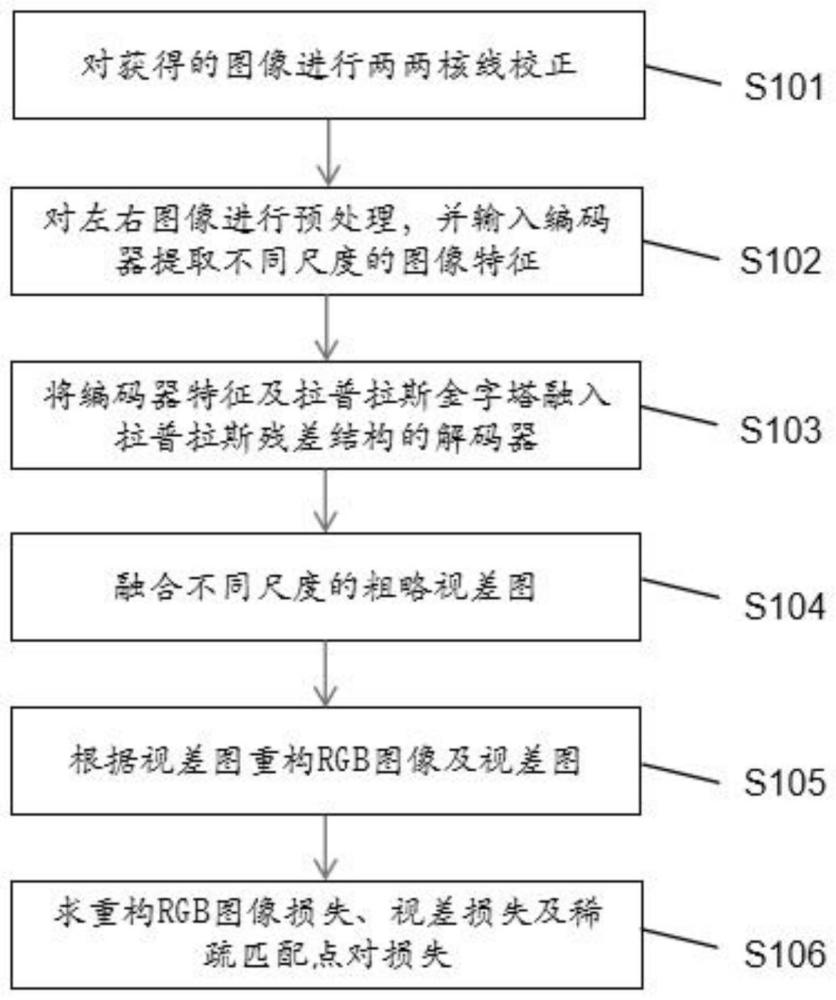
2、为实现上述目的,本发明提供了一种高质量轻量级无监督深度估计网络模型设计方法,包括以下步骤:
3、对获取的图像序列进行两两组合为图像对,然后对图像对进行核线校正,并且采用sift算法对核线影像进行特征提取及特征匹配,利用核线影像同名点在同一水平线上的几何关系对匹配点对进行筛选、剔除误匹配点对,得到准确稀疏匹配点对之间的视差,并将视差值进行保存用于后续深度估计网络的训练;
4、对核线校正后的左右图像经过预处理后输入权值共享的无监督深度估计网络,得到左右图像的视差图;
5、利用得到的左右视差图分别重构左、右图像的rgb图,利用重构的左、右rgb图像分别与输入的rgb图像求损失,rgb图像损失如下:
6、
7、其中i、j表示像素坐标,g表示真实的图像,表示重构的图像,n表示重构图像有效点点数,即剔除超出图像像素坐标范围后的点数;
8、对输出的左、右视差图也进行视差图的重构,并且与输出的左、右视差求一致性损失,一致性损失函数如下:
9、
10、其中i、j表示像素坐标,表示预测视差,d表示真实视差;n为稀疏点总点数;α为超参数,为0.85。
11、将输出的视差图与采用sift匹配得到的稀疏点视差进行求损失,稀疏点损失与视差图的一致性损失相同。
12、所述筛选、剔除误匹配点对主要是利用核线影像同名点在同一水平线上的几何关系,即左匹配点横坐标大于右匹配点横坐标,纵坐标相等。我们利用这两个坐标关系剔除误匹配点,为了保留更多的匹配点对,我们允许纵坐标的误差为±2像素。即我们最终剔除匹配点对纵坐标之差大于2像素,左匹配点横坐标小于右匹配点横坐标的匹配点对,否则保留;
13、所述图像预处理包括对输入图像以0.5的概率进行随机水平翻转,对亮度、颜色和伽马值进行随机调整,调整范围为[0.8,1.2];
14、所述权值共享的无监督深度估计网络由编码器与解码器组成。编码器采用resnext101,解码器采用5层拉普拉斯残差结构组成;
15、所述拉普拉斯残差结构编码器的第n层的结构为:将上n-1层粗略视差图上采样后与第n层编码器特征与第n层拉普拉斯金字塔进行级联后输入m层卷积后得到的视差特征再与第n层拉普拉斯金字塔进行相加得到第n层的粗略深度图。最后将5层不同尺度的粗略深度图进行融合恢复图像的高频细节得到精细深度图。
16、本发明的一种高质量轻量级无监督深度估计网络模型设计方法,对获得的图像序列进行两两组合后进行核线校正,并进行特征提取与特征匹配以得到稀疏匹配点对之间的视差;对获取的图像进行预处理,并将预处理后的图像送入编码器提取不同尺度的图像特征;将提取到的不同尺度的图像特征与拉普拉斯金字塔送入拉普拉斯残差解码器获得不同尺度的粗略视差图;将不同尺度的粗略视差图进行融合得到物体轮廓清晰的精细视差图。利用左右视差图重构左右rgb图像及左右视差图,求重构图像与输入图像的损失、视差图与重构的视差图损失及稀疏匹配点对视差与模型输出的视差求损失以训练网络;在解码器上融入拉普拉斯金字塔以学习图像的物体轮廓信息以得到物体轮廓清晰的视差图;利用核线影像之间的几何关系重构图像训练网络克服有监督深度估计需要大量真实标签的困难,从而能够应用到三维重建等实际工程当中。
技术特征:
1.一种高质量轻量级无监督深度估计网络模型设计方法,其特征在于,包括以下步骤:
2.如权利要求1所述的高质量轻量级无监督深度估计网络模型设计方法,其特征在于,获取多张rgb训练集图像序列,对训练集图像进行两两组合为图像对,然后对图像对进行核线校正,包括:
3.如权利要求1所述的高质量轻量级无监督深度估计网络模型设计方法,其特征在于,对左右核线影像进行预处理,并输入编码器提取不同尺度的图像特征,包括:
4.如权利要求1所述的高质量轻量级无监督深度估计网络模型设计方法,其特征在于,将编码器提取到的图像特征及拉普拉斯金字塔融入拉普拉斯残差结构解码器获得粗略视差图,包括:
5.如权利要求1所述的高质量轻量级无监督深度估计网络模型设计方法,其特征在于,融合不同尺度的粗略视差图,包括:
6.如权利要求1所述的高质量轻量级无监督深度估计网络模型设计方法,其特征在于,根据视差图重构rgb图像及视差图,包括:
7.如权利要求1所述的高质量轻量级无监督深度估计网络模型设计方法,其特征在于,求重构rgb图像损失、视差损失及稀疏匹配点对损失,包括:
技术总结
本发明公开了一种高质量轻量级无监督深度估计网络模型设计方法,通过对图像序列进行核线校正、特征提取与特征匹配获得稀疏匹配点对之间的视差。将影像序列进行两两组合为图像对,然后对图像对进行核线校正及预处理,通过编码器提取不同尺度的图像特征;将图像特征与拉普拉斯金字塔融入拉普拉斯残差解码器获得不同尺度的粗略视差图;将粗略视差图进行融合得到精细视差图;利用左右视差图重构左、右图像及左、右视差图,求重构图像损失、视差损失及稀疏匹配点对视差损失以训练网络。本发明利用核线影像之间的几何关系重构图像训练网络克服有监督深度估计需要大量标签的困难,并达到了实时的推理速度,可广泛应用于三维重建等实际应用当中。
技术研发人员:彭智勇,杨桂旭
受保护的技术使用者:桂林电子科技大学
技术研发日:
技术公布日:2024/4/7
- 还没有人留言评论。精彩留言会获得点赞!