一种数据处理的方法、装置、电子设备及存储介质与流程
本申请涉及大数据,特别涉及一种数据处理的方法、装置、电子设备及存储介质。
背景技术:
1、随着社会的发展,大模型的使用变得越来越普遍,在对大模型进行学习优化时,一般采用通过人为设计的问答内容,将问答内容作为大模型的输入数据以及输出数据的参照,如此来实现对于大模型的训练。但是这样会导致人工成本较高,同时也无法使得模型具备自我学习的能力。
技术实现思路
1、有鉴于此,本申请实施例提供了一种数据处理方法、装置、电子设备及存储介质,旨在避免人力资源的浪费,实现大模型的自我优化。
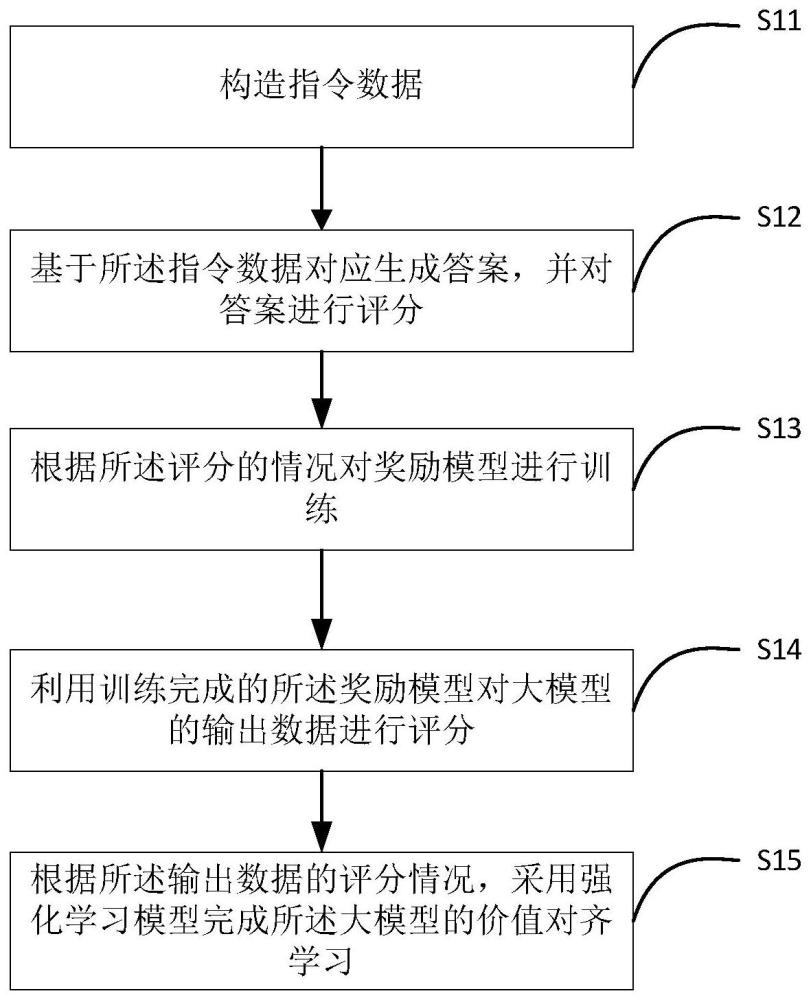
2、第一方面,本申请实施例提供了一种数据处理的方法,所述方法包括:
3、构造指令数据;
4、基于所述指令数据对应生成答案,并对答案进行评分;
5、根据所述评分的情况对奖励模型进行训练;
6、利用训练完成的所述奖励模型对大模型的输出数据进行评分;
7、根据所述输出数据的评分情况,采用强化学习模型完成所述大模型的价值对齐学习。
8、可选的,所述根据所述输出数据的评分情况,采用强化学习模型完成所述大模型的价值对齐学习之前,所述方法还包括:
9、对所述输出数据的评分情况进行归一化处理;
10、所述根据所述输出数据的评分情况,采用强化学习模型完成所述大模型的价值对齐学习,包括:
11、根据所述输出数据的评分情况,使用近端策略算法结合gae(广义优势估计)算法的方式进行所述大模型的处理;
12、对处理完成的所述大模型采用强化学习模型完成所述大模型的价值对齐学习。
13、可选的,所述根据所述评分的情况对奖励模型进行训练,包括:
14、获取所述评分的结果;
15、对所述评分的结果进行排序;
16、将所述评分的结果和所述排序的结果作为所述评分情况,根据所述评分情况对奖励模型进行训练。
17、可选的,所述根据所述评分的情况对奖励模型进行训练之前,所述方法还包括:
18、确定第一类型数据和第二类型数据,所述第一类数据与所述第二类数据所属类型不同;
19、根据所述第一类型数据构造第一奖励模型;
20、根据所述第二类型数据构造第二奖励模型;
21、所述评分的情况包括所述第一类型数据对应的评分的第一情况和所述第二类型数据对应的评分的第二情况,所述根据所述评分的情况对奖励模型进行训练,包括:
22、基于所述第一情况对所述第一奖励模型进行训练;
23、基于所述第二情况对所述第二奖励模型进行训练。
24、可选的,所述近端策略算法中包括动作模型和状态模型,所述使用近端策略算法结合gae(广义优势估计)算法的方式进行所述大模型的处理,包括:
25、确定所述动作模型的第一学习率以及所述状态模型的第二学习率;
26、基于所述第一学习率及所述第二学习率对所述近端策略算法进行优化;
27、基于完成优化的所述近端策略算法结合gae(广义优势估计)算法进行所述大模型的处理。
28、可选的,所述根据所述评分的情况对奖励模型进行训练,包括:
29、基于第一损失函数对所述奖励模型进行训练。
30、可选的,所述采用强化学习模型完成所述大模型的价值对齐学习,包括:
31、采用所述强化学习模型及模仿学习模型,基于第二损失函数完成所述大模型的价值对齐学习。
32、第二方面,本申请实施例提供了一种数据处理的装置,所述装置包括:构造模块、生成模块、训练模块、评分模块及学习模块;
33、所述构造模块,用于构造指令数据;
34、所述生成模块,用于基于所述指令数据对应生成答案,并对答案进行评分;
35、所述训练模块,用于根据所述评分的情况对奖励模型进行训练;
36、所述评分模块,用于利用训练完成的所述奖励模型对大模型的输出数据进行评分;所述学习模块,用于根据所述输出数据的评分情况,采用强化学习模型完成所述大模型的价值对齐学习。
37、第三方面,本申请提供了一种电子设备,所述设备包括:处理器、存储器、系统总线;
38、所述处理器以及所述存储器通过所述系统总线相连;
39、所述存储器用于存储一个或多个程序,所述一个或多个程序包括指令,所述指令当被所述处理器执行时使所述处理器执行实现第一方面所述方法。
40、第四方面,本申请实施例提供了一种计算机存储介质,所述计算机存储介质中存储有代码,当所述代码被运行时,运行所述代码的设备实现前述第一方面任一项所述方法。
41、本申请提供了一种数据处理方法、装置、电子设备及存储介质,在执行所述方法时,首先构造指令数据,然后基于所述指令数据对应生成答案,并对答案进行评分,根据所述评分的情况对奖励模型进行训练,利用训练完成的所述奖励模型对大模型的输出数据进行评分。最后根据所述输出数据的评分情况,采用强化学习模型完成所述大模型的价值对齐学习。如此,通过利用评分情况对奖励模型进行训练能够使得训练完成的奖励模型具有精度,利用训练完成的奖励模型对大模型的输出数据进行评分,能够保证对大模型输出数据的准确性进行正确判断,进而根据对大模型输出数据的准确性,利用强化学习模型对大模型进行价值对齐学习。使得大模型通过强化学习自我优化,增强评分高的答案输出概率,降低评分低的答案输出概率,不需要人工构造大量标准输出答案。让大模型与环境不断交互实现优化。
技术特征:
1.一种数据处理的方法,其特征在于,所述方法包括:
2.根据权利要求1所述的方法,其特征在于,所述根据所述输出数据的评分情况,采用强化学习模型完成所述大模型的价值对齐学习之前,所述方法还包括:
3.根据权利要求1所述的方法,其特征在于,所述根据所述评分的情况对奖励模型进行训练,包括:
4.根据权利要求1所述的方法,其特征在于,所述根据所述评分的情况对奖励模型进行训练之前,所述方法还包括:
5.根据权利要求2所述的方法,其特征在于,所述近端策略算法中包括动作模型和状态模型,所述使用近端策略算法结合gae(广义优势估计)算法的方式进行所述大模型的处理,包括:
6.根据权利要求1所述的方法,其特征在于,所述根据所述评分的情况对奖励模型进行训练,包括:
7.根据权利要求1所述的方法,其特征在于,所述采用强化学习模型完成所述大模型的价值对齐学习,包括:
8.一种数据处理的装置,其特征在于,所述装置包括:构造模块、生成模块、训练模块、评分模块及学习模块;
9.一种电子设备,其特征在于,所述设备包括:处理器、存储器、系统总线;
10.一种计算机可读存储介质,其特征在于,所述计算机可读存储介质上存储有实现数据处理的方法的实现程序,所述实现数据处理的方法的实现程序被处理器执行时实现如权利要求1-7任意一项所述方法的步骤。
技术总结
本申请公开了一种数据处理的方法、装置、电子设备及存储介质,应用于大数据领域。在本申请中,首先构造指令数据,然后基于所述指令数据对应生成答案,并对答案进行评分,根据所述评分的情况对奖励模型进行训练,利用训练完成的所述奖励模型对大模型的输出数据进行评分。最后根据所述输出数据的评分情况,采用强化学习模型完成所述大模型的价值对齐学习。本申请实现了避免人力资源的浪费,实现大模型的自我优化。
技术研发人员:杨小猛
受保护的技术使用者:太保科技有限公司
技术研发日:
技术公布日:2024/2/21
- 还没有人留言评论。精彩留言会获得点赞!