一种应用于自动驾驶的目标检测方法及系统
本发明属于自动驾驶,具体涉及一种应用于自动驾驶的目标检测方法及系统。
背景技术:
1、随着计算机视觉和硬件设备的飞速发展,深度学习领域下的道路目标检测算法正成为自动驾驶技术的重要组成部分。然而,目前的道路目标检测算法虽然在大目标的检测方面取得了显著进展,但对于道路中的小目标,检测过程中仍然存在一系列挑战。小目标之所以成为目标检测算法的难题,是因为小目标的信息量有限,很难通过传统的卷积操作提取足够的特征信息,并且随着网络深度的增加,小目标的浅层信息往往会逐渐丢失,甚至完全消失,这导致小目标会出现比大目标更严重的漏检和误检问题。
2、因此,亟需研发一种针对小目标检测的方法。
技术实现思路
1、本发明的目的在于克服现有技术之缺陷,本发明提供了一种应用于自动驾驶的目标检测方法及系统,本发明通过增强小目标的浅层信息的提取能力、保留能力以及小目标的定位能力,从而改善自动驾驶的道路场景中小目标存在的严重漏检和误检问题。
2、为了实现预期效果,本发明采用了以下技术方案:
3、本发明公开了一种应用于自动驾驶的目标检测方法,该方法包括:
4、采集自动驾驶过程中识别到的原始目标图像;
5、将原始目标图像输入改进的yolov5s算法中检测目标得到最终检测目标图像;
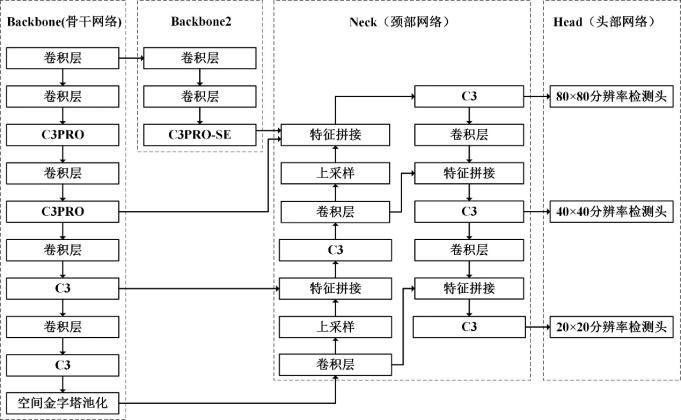
6、所述改进的yolov5s算法包括第一骨干网络、第二骨干网络;
7、所述第一骨干网络包括至少一个c3pro模块;所述c3pro模块用于提取原始目标图像的浅层特征得到第一特征图,并将第一特征图发送至第二骨干网络或者颈部网络;
8、所述第二骨干网络为所述第一骨干网络与所述颈部网络中间的独立的分支通道;所述第二骨干网络包括至少一个c3pro-se模块;所述c3pro-se模块用于对所述第一骨干网络发送来的特征图进行特征提取得到第二特征图,并将第二特征图发送至所述颈部网络。
9、进一步地,所述c3pro模块包括若干个1×1卷积层、若干个3×3卷积层、若干个瓶颈层。
10、进一步地,将第一目标图像输入所述c3pro模块后,所述第一目标图像经过若干个1×1卷积层、若干个3×3卷积层、若干个瓶颈层的特征拼接后,得到1×1卷积层的第二目标图像并由所述c3pro模块输出。
11、进一步地,所述c3pro-se模块由所述c3pro模块和se通道注意力模型组合而成。
12、进一步地,将第三目标图像输入所述c3pro-se模块后,所述第三目标图像首先在c3pro模块中经过若干个1×1卷积层、若干个3×3卷积层、若干个瓶颈层的特征拼接后,得到1×1卷积层的第四目标图像,再将该第四目标图像送入se通道注意力模型进行通道注意力向量映射得到第五目标图像,最后将第五目标图像和第四目标图像进行逐通道相乘得到第六目标图像并由所述c3pro-se模块输出。
13、进一步地,所述改进的yolov5s算法还包括siou损失函数,所述siou损失函数为:
14、;
15、式中,iou为真实框与预测框的交并比,为距离损失,为形状损失。
16、进一步地,所述距离损失为:
17、;
18、式中,由角度损失函数计算得到,和由检测框中心坐标结合最小外接矩形的宽和高计算得到。
19、进一步地,所述角度损失函数为:
20、;
21、式中,为预测框和真实框中心点的高度差,为预测框和真实框中心点的距离。
22、进一步地,所述形状损失为:
23、;
24、式中,和分别通过预测框和真实框的宽和高计算得到,θ为对形状的关注程度。
25、本发明还公开了一种应用于自动驾驶的目标检测系统,所述系统能够实现上述任一所述方法,所述系统包括:
26、采集模块,用于采集自动驾驶过程中识别到的原始目标图像;
27、检测模块,用于将原始目标图像输入改进的yolov5s算法中检测目标得到最终检测目标图像;所述改进的yolov5s算法包括第一骨干网络、第二骨干网络;所述第一骨干网络包括至少一个c3pro模块;所述c3pro模块用于提取原始目标图像的浅层特征得到第一特征图,并将第一特征图发送至第二骨干网络或者颈部网络;所述第二骨干网络为所述第一骨干网络与所述颈部网络中间的独立的分支通道;所述第二骨干网络包括至少一个c3pro-se模块;所述c3pro-se模块用于对所述第一骨干网络发送来的特征图进行特征提取得到第二特征图,并将第二特征图发送至所述颈部网络。
28、与现有技术相比,本发明的有益效果是:本发明提供了一种应用于自动驾驶的目标检测方法及系统,首先,本发明提出一种基于提取分流思想设计的c3pro模块,将其应用于网络的浅层部分,该模块通过更多并行的梯度流分支,以及更多的卷积运算和可以用来学习的参数,增强网络对于小目标的浅层特征的提取能力;其次,本发明增加一条特征提取分支通道,该通道独立于原算法的骨干网络,层数更少,解决了在前向传播过程中因为网络过深,导致的小目标浅层信息丢失问题,并在通道末端加入通道注意力,避免了特征冗余;最后,本发明针对yolov5s定位损失函数惩罚不全面的问题,引入更先进的siou损失函数,以更精确的定位小目标。本发明通过增强小目标的浅层信息的提取能力、保留能力以及小目标的定位能力,从而改善自动驾驶的道路场景中小目标存在的严重漏检和误检问题。
技术特征:
1.一种应用于自动驾驶的目标检测方法,其特征在于,该方法包括:
2.如权利要求1所述一种应用于自动驾驶的目标检测方法,其特征在于,将第一目标图像输入所述c3pro模块后,所述第一目标图像经过若干个1×1卷积层、若干个3×3卷积层、若干个瓶颈层的特征拼接后,得到1×1卷积层的第二目标图像并由所述c3pro模块输出。
3.如权利要求1-2任一所述一种应用于自动驾驶的目标检测方法,其特征在于,将第三目标图像输入所述c3pro-se模块后,所述第三目标图像首先在c3pro模块中经过若干个1×1卷积层、若干个3×3卷积层、若干个瓶颈层的特征拼接后,得到1×1卷积层的第四目标图像,再将该第四目标图像送入se通道注意力模型进行通道注意力向量映射得到第五目标图像,最后将第五目标图像和第四目标图像进行逐通道相乘得到第六目标图像并由所述c3pro-se模块输出。
4.如权利要求1所述一种应用于自动驾驶的目标检测方法,其特征在于,所述改进的yolov5s算法还包括siou损失函数,所述siou损失函数为:
5.如权利要求4所述一种应用于自动驾驶的目标检测方法,其特征在于,所述距离损失为:
6.如权利要求5所述一种应用于自动驾驶的目标检测方法,其特征在于,所述角度损失函数为:
7.如权利要求4所述一种应用于自动驾驶的目标检测方法,其特征在于,所述形状损失为:
8.一种应用于自动驾驶的目标检测系统,其特征在于,所述系统能够实现权利要求1-7任一所述方法,所述系统包括:
技术总结
本发明公开了一种应用于自动驾驶的目标检测方法及系统,本发明将基于提取分流思想设计的C3PRO模块应用于网络的浅层部分,通过更多并行的梯度流分支以及更多的卷积运算和可以用来学习的参数,增强网络对于小目标的浅层特征的提取能力;本发明还增加了一条特征提取分支通道,该通道独立于原算法的骨干网络,层数更少,解决了在前向传播过程中因网络过深导致的小目标浅层信息丢失问题,并在通道末端加入通道注意力机制,避免了特征冗余;本发明针对YOLOv5s定位损失函数惩罚不全面的问题,引入更先进的SIoU损失函数,以更精确的定位小目标。本发明增强了自动驾驶的道路场景中小目标的浅层信息的提取能力、保留能力以及小目标的定位能力。
技术研发人员:李维刚,俞航
受保护的技术使用者:武汉科技大学
技术研发日:
技术公布日:2024/2/6
- 还没有人留言评论。精彩留言会获得点赞!