一种基于临床文本树结构的ICD自动编码方法
本发明属于多标签文本分类和自然语言处理领域,具体涉及基于临床文本树结构的icd自动编码技术。
背景技术:
1、icd自动编码是指是指利用自然语言处理、机器学习等方法,将相应的icd编码与输入的临床数据自动匹配转换为国际通用的编码,统一解释患者的诊断和住院过程。近年来,icd自动编码研究受到越来越广泛的关注,不仅因为其重大的医学研究意义,更因为其广泛的临床应用价值。几乎所有的医疗机构(比如医院、诊所、保险公司、卫生部门)都需要使用icd编码系统来记录和管理患者的健康信息。而传统的手工icd编码方法由于临床记录信息量大,书写临床记录时用词不规范,准确率仅为71%,成本也非常高。因此,自动和精确的icd自动编码方法对于医院和其他医疗机构来说非常重要。应用icd自动编码的技术和方法能够帮助我们更好地理解患者的健康状况,并对其进行更好地治疗和预防,也可以快速地提高医疗机构的工作效率。例如,在对一个大型医院的数据分析中,高质量的icd自动编码可以帮助医生快速地找出患者的风险因素和并发症;作为训练输入的临床记录是平均包含1524个单词的长文本,但9000多个icd代码中仅有部分代码被频繁使用。可见高质量的icd自动编码对医疗机构的服务质量和效率有着巨大的影响,icd自动编码的质量和效率提升意义重大。
2、迄今为止,学者们已经提出了一系列经典或新颖的方法来进行icd自动编码。然而,这些现有的方法在不同程度上都存在一些缺陷。例如,cnn(convolutional neuralnetworks)、bi-gru(bidirectional gru)和hypercore都需要大量的标注数据来训练模型,而临床记录本身就存在很多噪声和不一致性;caml(convolutional attention formulti-label classification)难以处理医疗记录中的缩写词、同义词、歧义词等语言现象,导致编码的错误或不准确;multirescnn(multi-filter residual convolutionalneural netwok)对于医疗记录中不同n-gram特征之间的交互关系的捕捉存在困难;laat(label attention model)需要大量的参数来调整自适应注意力树的效果,这可能增加了模型的复杂度和不稳定性。鉴于此,本发明提出一种基于临床文本树结构的icd自动编码方法及系统。
技术实现思路
1、本发明的目的是提供一种基于临床文本树结构的icd自动编码方法。
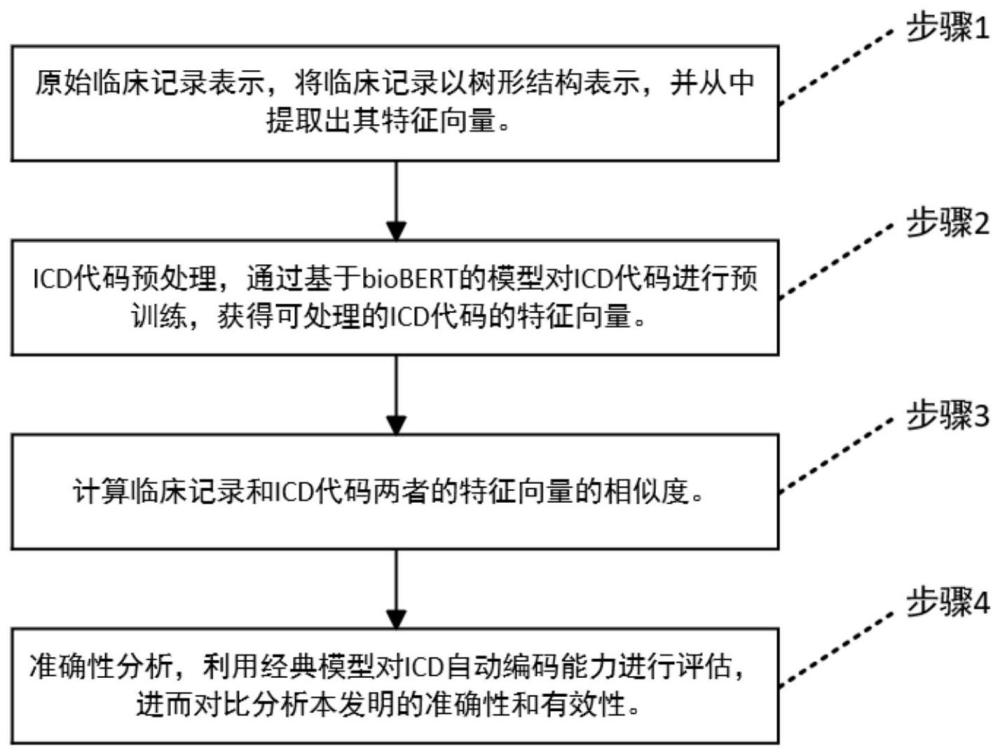
2、本发明是一种基于临床文本树结构的icd自动编码方法,包括以下步骤:
3、s1、原始临床记录的表示,将临床记录的特征提取出来并转换为可处理的形式,在这个过程中,分别需要对临床记录进行清洗分词等预处理操作,并获取到它的文本特征以及结构特征;
4、s2、icd代码预处理,通过基于预训练的模型对icd代码进行预训练,以获得可处理的icd代码的特征向量。定义pij为icdj描述中单词j的向量,则为icdj的向量。由biobert模型得到icd代码的特征向量可用q=(q1,q2,...,qn)来表示;
5、s3、计算s1和s2求得的临床记录的特征向量和icd代码的特征向量的相似度。当临床记录特征与icd代码特征在整个训练阶段呈正相关时,其相似度会增加;当它们呈负相关时,其相似度会降低。预测方法中的相似度用于计算icd代码发生的可能性。之前的计算已经为每个临床记录产生了(2m-1)个向量和icd代码qi的向量。在相似度计算中,通过函数h(·)将其维度从转换为与临床记录特征向量o相同的维度其中n为icd代码的数量,l为icd向量的长度。则临床记录与icd代码的相似度可计算为s=sigmoid[softmax(oqt)o];
6、s4、准确性分析,利用经典模型对icd自动编码能力进行评估,进而对比分析本发明的准确性和有效性。
7、与现有技术相比,本发明具有以下有益效果:
8、1、模型精确度更高:本方法实现了icd自动编码精确度的提高,作为一个多标签分类模型,获得了更高的f1分数(micro-f1和macro-f1)。f1分数通过对整个样本中的每个预测答案进行计数,在大多数情况下指示模型的性能,计算为:其中p是样本的精度,代表模型所有预测结果正确的百分比,计算为r是样本的回归值,表示模型正确识别了所有标准标签答案中的多少个,计算为精度表示模型给出的答案的置信度,而回归率表示模型对整体问题的拟合程度。micro-f1值是精度和回归率的总和平均值;
9、2、不同阈值下的预测能力更好:本方法获得更高的auc值(micro-auc和macro-auc),也即roc产生的曲线下面积占总可能面积的百分比更高。auc的取值范围在0到1之间,值越接近1表示分类器的性能越好,值越接近0.5则表示分类器的性能越差。它说明本方法中的分类器对正例样本和负例样本的正确排序能力更好,它通过将具有标签r的每个数据的置信水平与没有标签(u)的每个数据进行比较来计算:
10、3、前n个结果更精确:本方法在考虑位置的情况下检测给定查询的前n个结果的准确性。一般来说,搜索的前几个结果的准确性更为重要。如果前几个结果与搜索词不相关,即使随后的所有结果都相关,那么信息检索系统也不令人满意。因此p@n是用于测量前几个结果的精度的度量,即在前n个的精度,搜索的前n个结果的精度,例如p@5,p@8。如果yi=0,1分别表示第i个相关或不相关的结果:
技术特征:
1.一种基于临床文本树结构的icd自动编码方法,其特征在于,该方法使用基于transformer的预训练模型对临床文本和icd代码进行特征提取,并获取临床文本的成分分析树以获取更全面的结构信息,通过对多方面信息进行集合,使用tree-lstm模型对临床文本进行训练得到两者的相似度以达到自动编码的目的;所述方法包括设备注册阶段和密钥分发阶段,其步骤为:
2.根据权利要求1所述的基于临床文本树结构的icd自动编码方法,其特征在于,所述步骤s1的具体子步骤如下:
3.根据权利要求1所述的基于临床文本树结构的icd自动编码方法,其特征在于,所述步骤s2的具体子步骤如下:
4.根据权利要求1所述的基于临床文本树结构的icd自动编码方法,其特征在于,所述步骤s4的具体子步骤如下:
技术总结
一种基于临床文本树结构的ICD自动编码方法,包括步骤:原始临床记录的表示,将临床记录的特征提取出来并通过bioBRET模型转换为可处理的形式,同时获取临床记录的成分分析树;ICD代码预处理,通过基于bioBRET模型对ICD代码进行预训练,以获得可处理的ICD代码的特征向量;计算临床记录和ICD代码特征向量的相似度;准确性分析,利用经典模型对ICD自动编码能力进行评估,进而对比分析本发明的准确性和有效性。本发明既考虑了临床记录和ICD代码本身的特征,又考虑了全局特征以及它们相互之间的关系,能有效提高ICD自动编码的准确性;预训练模型的引入也使得临床记录树结构导致的时间复杂度高的问题得以改善,提高ICD编码的有效性。
技术研发人员:卢鹏丽,薛景今,刘文智,高家杰,王悦昊,李玲,董超
受保护的技术使用者:兰州理工大学
技术研发日:
技术公布日:2024/4/8
- 还没有人留言评论。精彩留言会获得点赞!