面向大语言模型的PDF文件处理方法、装置、设备和介质与流程
本发明涉及pdf文件处理,具体涉及一种面向大语言模型的pdf文件处理方法、装置、设备和介质。
背景技术:
1、不管是构建大语言模型还是应用大语言模型,都需要给模型投喂足够多的文本数据。但有很多pdf电子书是基于图片存储的,需要进行ocr及后续处理。本专利主要是为了解决这个问题,即:将需要ocr的pdf文件转成大语言模型可以使用的文本。目前已经有一些对pdf文件进行ocr的技术。输入一篇需要ocr的pdf文档,可以将文档转成word格式。生成的word文档不能直接应用于大模型训练或让大模型去理解,主要有以下几点原因:大模型需要的连续的文档正文,不需要页眉、页脚、目录页、参考文献页等干扰信息;文档中的表格、图片信息不能正确的处理;文档中的公式信息,现有技术不能很好地理解。
技术实现思路
1、本发明提供面向大语言模型的pdf文件处理方法、装置、设备和介质,能够解决上述技术问题。
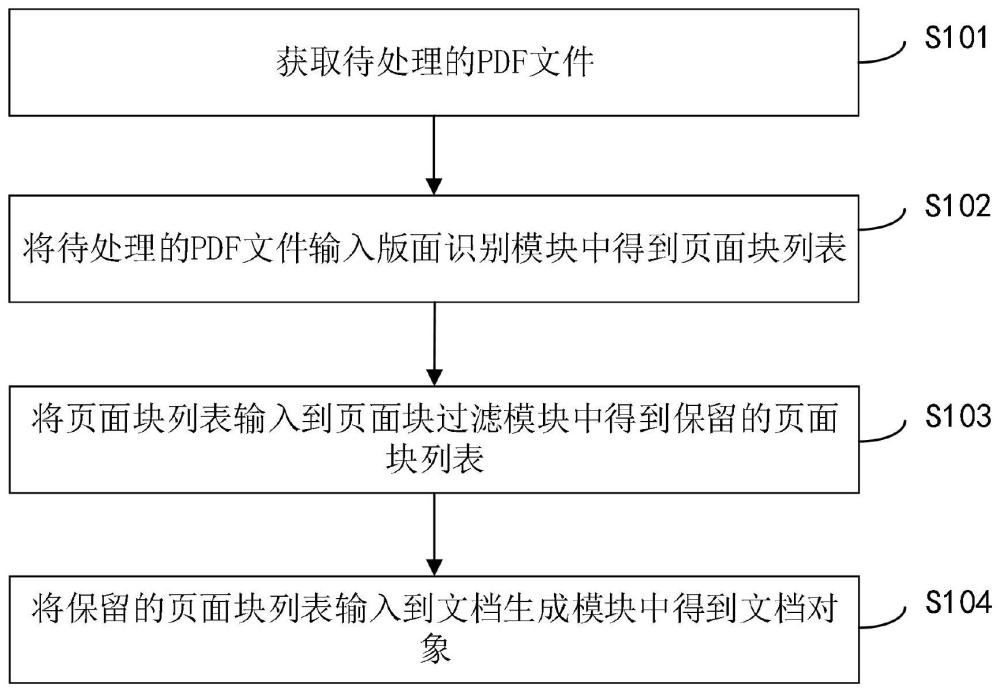
2、第一方面,本发明实施例提供一种面向大语言模型的pdf文件处理方法,包括:
3、获取待处理的pdf文件;
4、将待处理的pdf文件输入版面识别模块中得到页面块列表;
5、将页面块列表输入到页面块过滤模块中得到保留的页面块列表;
6、将保留的页面块列表输入到文档生成模块中得到文档对象。
7、进一步地,上述一种面向大语言模型的pdf文件处理方法中,将待处理的pdf文件输入版面识别模块中得到页面块列表,包括:
8、将pdf文件的页面转成图片;
9、使用faster rcnn方法对所述图片进行区域检测得到多个页面块;
10、将多个页面块中的每个页面块均转成页面块列表;
11、其中,页面块至少包括:页眉区域、页脚区域、侧边栏区域、标题区域和正文区域;
12、页面块列表的数据结构至少包括:字段名称、字段解释和字段示例。
13、进一步地,上述一种面向大语言模型的pdf文件处理方法中,将所述页面块列表输入到页面块过滤模块中得到保留的页面块列表,包括:
14、将页面块列表中的页面块按照页面块过滤模块中设定的保留规则进行保留,过滤掉不需要保留的页面块得到保留的页面块列表;
15、其中,设定的保留规则是以列表形式设定的,设定的保留规则的内容至少包括:类型编号、类型名称和是否保留。
16、进一步地,上述一种面向大语言模型的pdf文件处理方法,还包括:
17、判断页面块列表中是否包括图片、表格和公式;
18、若判断结果为页面块列表中包括图片、表格和公式,将图片、表格和公式转成图片,存入文件服务器中;
19、将文件服务器中对应的文件访问地址存入到所述保留的页面块列表的ref字段中。
20、进一步地,上述一种面向大语言模型的pdf文件处理方法中,将保留的页面块列表输入到文档生成模块中得到文档对象,包括:
21、对保留的页面块列表中跨页文本类型的页面块进行拼接;
22、从拼接后的第一个页面块开始扫描直到扫描到最后一个页面块得到文档对象;
23、文档对象包括:标题和段落列表。
24、进一步地,上述一种面向大语言模型的pdf文件处理方法中,对保留的页面块列表中跨页文本类型的页面块进行拼接,包括:
25、对保留的页面块列表中的每一个页面块,若第n页的最后一个页面块类型是段落正文,且第n+1页的第一个页面块的类型也是段落正文;
26、则将最后一个页面块和第一个页面块合并成一个页面块。
27、进一步地,上述一种面向大语言模型的pdf文件处理方法中,从拼接后的第一个页面块开始扫描直到扫描到最后一个页面块得到文档对象,包括:
28、若扫描到段落正文、图片、表格、公式中的一种,则将其加入到对应标题的段落正文块列表中;
29、若扫描到段落标题,则停止继续向后扫描;
30、若扫描到下文没有页面块,退出向后扫描。
31、第二方面,本发明实施例还提供一种面向大语言模型的pdf文件处理装置,包括:
32、获取模块:用于获取待处理的pdf文件;
33、第一输入模块:用于将待处理的pdf文件输入版面识别模块中得到页面块列表;
34、第二输入模块:用于将页面块列表输入到页面块过滤模块中得到保留的页面块列表;
35、第三输入模块:用于将保留的页面块列表输入到文档生成模块中得到文档对象。
36、第三方面,本发明实施例还提供了一种电子设备,包括:处理器和存储器;
37、处理器通过调用存储器存储的程序或指令,用于执行如上任一项一种面向大语言模型的pdf文件处理方法。
38、第四方面,本发明实施例还提供了一种计算机可读存储介质,计算机可读存储介质存储程序或指令,程序或指令使计算机执行如上任一项一种面向大语言模型的pdf文件处理方法。
39、本发明的有益效果是:本发明通过将待处理的pdf文件输入版面识别模块中得到页面块列表,将页面块列表输入到页面块过滤模块中得到保留的页面块列表,将保留的页面块列表输入到文档生成模块中得到文档对象实现了将pdf文件从机器不容易理解的图片转化成了容易理解的文档对象,为构建大语言模型或应用大语言模型提供了文本数据支撑。
技术特征:
1.一种面向大语言模型的pdf文件处理方法,其特征在于,包括:
2.根据权利要求1所述的一种面向大语言模型的pdf文件处理方法,其特征在于,所述将所述待处理的pdf文件输入版面识别模块中得到页面块列表,包括:
3.根据权利要求1所述的一种面向大语言模型的pdf文件处理方法,其特征在于,所述将所述页面块列表输入到页面块过滤模块中得到保留的页面块列表,包括:
4.根据权利要求3所述的一种面向大语言模型的pdf文件处理方法,其特征在于,所述方法,还包括:
5.根据权利要求1所述的一种面向大语言模型的pdf文件处理方法,其特征在于,所述将所述保留的页面块列表输入到文档生成模块中得到文档对象,包括:
6.根据权利要求5所述的一种面向大语言模型的pdf文件处理方法,其特征在于,所述对保留的页面块列表中跨页文本类型的页面块进行拼接,包括:
7.根据权利要求5所述的一种面向大语言模型的pdf文件处理方法,其特征在于,所述从拼接后的第一个页面块开始扫描直到扫描到最后一个页面块得到文档对象,包括:
8.一种面向大语言模型的pdf文件处理装置,其特征在于,包括:
9.一种电子设备,其特征在于,包括:处理器和存储器;
10.一种计算机可读存储介质,其特征在于,所述计算机可读存储介质存储程序或指令,所述程序或指令使计算机执行如权利要求1至7任一项所述一种面向大语言模型的pdf文件处理方法。
技术总结
本发明涉及面向大语言模型的PDF文件处理方法、装置、设备和介质,该方法包括:获取待处理的PDF文件;将待处理的PDF文件输入版面识别模块中得到页面块列表;将页面块列表输入到页面块过滤模块中得到保留的页面块列表;将保留的页面块列表输入到文档生成模块中得到文档对象。本发明通过将待处理的PDF文件输入版面识别模块中得到页面块列表,将页面块列表输入到页面块过滤模块中得到保留的页面块列表,将保留的页面块列表输入到文档生成模块中得到文档对象实现了将PDF文件从机器不容易理解的图片转化成了容易理解的文档对象,为构建大语言模型或应用大语言模型提供了文本数据支撑。
技术研发人员:任禾,刘升平,梁家恩
受保护的技术使用者:云知声智能科技股份有限公司
技术研发日:
技术公布日:2024/4/17
- 还没有人留言评论。精彩留言会获得点赞!