一种结合学术文本结构的文本检测方法
本发明实施例涉及数据处理,尤其涉及一种结合学术文本结构的文本检测方法。
背景技术:
1、人工智能文本检测通过对人工智能生成的自然语言文本进行检测,以此判断其真实性的概率。人工智能文本检测的意义在于确保文本信息的真实性、减少虚假信息的传播,以及防止信息泄露和侵权等问题。通过人工智能文本检测,可以对文本信息进行自动化验证,以确保其真实性和合法性。人工智能生成学术文本的检测常采用两种方法。第一种是使用自然语言模型训练识别并进行检测,常用的训练模型有rnn、lstm和bert。该种方法通过大量输入已标记的人类文本、人工智能生成文本、人类-人工智能混合文本进行训练,对文本生成来源进行判断。第二种是利用统计学的方法对文本进行检测,常用的方法有gptzero和detectgpt。前者是通过计算困惑度和突发度来判断文本是否由人工智能生成。后者是利用生成文本自身的预训练神经网络,将原始检测文本的对数概率与多个经过扰动(将原始文本中的词进行替换、增加、删除操作)后的检测文本进行比较,计算平均对数比,从而判断文本的生成。现有技术存在的缺点包括:在构建文本特征向量时缺乏对学术文本不同部分的生成可能性划分;在文本特征向量转换方面,没有考虑到语言特征的区分手段。
2、可见,亟需一种适应性和检测精准度高的结合学术文本结构的文本检测方法。
技术实现思路
1、本发明实施例提供一种结合学术文本结构的文本检测方法,至少部分解决现有技术中存在适应性和精准度较差的问题。
2、本发明实施例提供了一种结合学术文本结构的文本检测方法,包括:
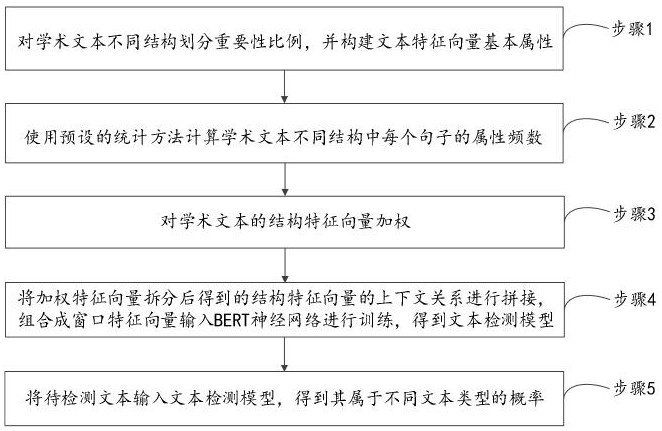
3、步骤1,对学术文本不同结构划分重要性比例,并构建文本特征向量基本属性;
4、步骤2,使用预设的统计方法计算学术文本不同结构中每个句子的属性频数;
5、所述步骤2具体包括:
6、步骤2.1,对学术文本中所划分的不同结构进行向量转换;
7、步骤2.2,遍历每个结构中的所有句子,并标注出每个句子的文本特征向量基本属性值,其中,文本特征向量基本属性值包括词性、命名实体、句法和情感极性分数;
8、步骤2.3,根据文本特征向量基本属性值,计算出词性、命名实体和句法的特征cf-sidf值,其中,特征cf-sidf值为cf值与sidf值的乘积,cf值表示一种特征在一句话中出现的总次数除以当前文本属性特征总数,sidf值表示一种特征的总数在所有文本个数的占比除以一种特征在一句话中出现的总次数与文本结构个数的占比;
9、步骤2.4,计算情感极性的平均值并据此计算平均情感极性分数;
10、步骤2.5,根据cf-sidf值和平均情感极性分数计算每个结构中单个句子的句子特征向量;
11、步骤3,对学术文本的结构特征向量加权;
12、所述步骤3具体包括:
13、步骤3.1,将每个结构的句子特征向量重新组成结构特征向量;
14、步骤3.2,利用结构权重对结构特征向量进行加权,得到学术文本的加权特征向量;
15、步骤4,将加权特征向量拆分后得到的结构特征向量的上下文关系进行拼接,组合成窗口特征向量输入bert神经网络进行训练,得到文本检测模型;
16、步骤5,将待检测文本输入文本检测模型,得到其属于不同文本类型的概率。
17、根据本发明实施例的一种具体实现方式,所述步骤1具体包括:
18、按照学术文本不同部分结构重要性进行比例划分,划分为n个结构并对每个结构设定不同结构权重,其中,n为正整数;
19、根据语言特点构建文本特征向量基本属性。
20、根据本发明实施例的一种具体实现方式,所述cf值的计算公式为
21、
22、其中,表示特征的位序,表示该句子中特征i出现的次数;
23、所述sidf值的计算公式为
24、
25、其中,表示为文本结构个数,表示文本总数,表示该段落中出现特征i的次数。
26、根据本发明实施例的一种具体实现方式,所述平均情感极性分数的计算公式为
27、
28、其中,表示该句子中第i个词的情感极性分数。
29、根据本发明实施例的一种具体实现方式,所述步骤4具体包括:
30、步骤4.1,将文本加权特征向量拆分为n个结构特征向量;
31、步骤4.2,将每个结构特征向量进行上下邻近拼接得到窗口特征向量;
32、步骤4.3,利用窗口特征向量训练bert神经网络,得到文本检测模型。
33、根据本发明实施例的一种具体实现方式,所述步骤5具体包括:
34、步骤5.1,将待检测文本划分为多个结构并将每个结构中的所有句子转换成结构特征向量;
35、步骤5.2,将每个结构特征向量依照结构进行上下邻近拼接、填充并输入到文本检测模型,得到其属于不同文本类型的概率。
36、本发明实施例中的结合学术文本结构的文本检测方案,包括:步骤1,对学术文本不同结构划分重要性比例,并构建文本特征向量基本属性;步骤2,使用预设的统计方法计算学术文本不同结构中每个句子的属性频数;步骤3,对学术文本的结构特征向量加权;步骤4,将加权特征向量拆分后得到的结构特征向量的上下文关系进行拼接,组合成窗口特征向量输入bert神经网络进行训练,得到文本检测模型;步骤5,将待检测文本输入文本检测模型,得到其属于不同文本类型的概率。
37、本发明实施例的有益效果为:通过本发明的方案,根据人工智能学术文本生成的语言特征对文本进行向量转换,在检测模型中加入结构性分析,依照文本中不同部分所占整体的重要性,对特征向量进行权重分配,以实现学术文本特征向量的构建,提高了文本检测的适应性、可解释性和精准度。
技术特征:
1.一种结合学术文本结构的文本检测方法,其特征在于,包括:
2.根据权利要求1所述的方法,其特征在于,所述步骤1具体包括:
3.根据权利要求2所述的方法,其特征在于,所述cf值的计算公式为
4.根据权利要求3所述的方法,其特征在于,所述平均情感极性分数的计算公式为
5.根据权利要求4所述的方法,其特征在于,所述步骤4具体包括:
6.根据权利要求5所述的方法,其特征在于,所述步骤5具体包括:
技术总结
本发明实施例中提供了一种结合学术文本结构的文本检测方法,属于数据处理技术领域,具体包括:步骤1,对学术文本不同结构划分重要性比例,并构建文本特征向量基本属性;步骤2,使用预设的统计方法计算学术文本不同结构中每个句子的属性频数;步骤3,对学术文本的结构特征向量加权;步骤4,将加权特征向量拆分后得到的结构特征向量的上下文关系进行拼接,组合成窗口特征向量输入BERT神经网络进行训练,得到文本检测模型;步骤5,将待检测文本输入文本检测模型,得到其属于不同文本类型的概率。通过本发明的方案,提高了文本检测的适应性、可解释性和精准度。
技术研发人员:曹文治,刘杉,余海航,曾阳艳,易国栋
受保护的技术使用者:湖南工商大学
技术研发日:
技术公布日:2024/2/8
- 还没有人留言评论。精彩留言会获得点赞!