一种基于知识和数据协同推理的视觉关系识别方法及装置
本发明涉及视觉关系检测领域,尤其涉及一种基于知识和数据协同推理的视觉关系识别方法及装置。
背景技术:
1、场景图生成任务是将图像解析为一种基于图结构形式的任务,在这个图结构中的节点被定义为场景中的物体类别,而连接节点的边表示成对物体之间的关系。与传统的目标检测任务[1]相比,场景图生成任务能够分析视觉场景图更加全面的结构化语义信息,这种结构化语义可以通过作为一种中间模态的信息来实现高级视觉理解的相关任务,例如:图像字幕生成[2],视觉问答[3]和图像生成[4]等。因此,场景图生成任务一直是多模态领域的研究重点,并且在自动驾驶和智能安防等领域有很大的应用价值。
2、最近,将常识知识与场景图生成任务相关联的思路已经引起了研究人员大量的关注[5][6]。不同于数据库中标注的具体场景中物体类别和关系,常识知识是独立于视觉场景之外的信息,反映出的是真实世界的规则与模式,这些在知识库中描述的视觉关系通常被用来整合到场景图生成的模型中来提高其对视觉场景的理解。例如:自动驾驶系统检测“马路上的汽车”与“街道”的关系,如果引入常识知识“汽车用于驾驶”和“驾驶可以在街上”有助于系统识别出复杂语义关系“驾驶”而不是简单的位置关系“在……之上”。通常使用的常识知识库可以为现有的常识知识图谱,例如:concept net[7],也可以为自主构建的结构化知识库。
3、目前,将常识知识引入场景图生成任务中的相关方法都遵循一个隐式的假设,即视觉场景中的每个物体对之间都需要关联常识知识进行识别,因此已有的场景图生成模型需要拟合更多的语义类别,极大地增加模型负担的同时并没有获得很高的性能增益。这类方法其实忽略了对于识别场景中不同物体对之间的关系时,对常识知识的需求是不同的。例如:在识别图2中“女孩”与“长凳”之间的关系时,仅通过视觉上的信息已经能够实现“坐在”这一准确的关系预测,但是相比于识别“人”与“飞盘”之间的关系时,视觉信息预测的关系类别会存在语义的不确定性,这时结合常识知识“飞盘-用来-扔”后,能够提高模型对这一关系的预测准确性,但是现有方法所设计的模型缺少通过对视觉上识别物体对关系的难易程度评估,导致模型无法实现自适应引入常识知识进行关系预测。例如:将现有方法设计的模型应用到自动驾驶系统中,系统会关联常识知识识别当前路况下每个物体对之间的关系,极大增加了系统的负担和复杂性,使系统运行缓慢,并且对于一些简单的关系“人走在街上”仅通过视觉上的信息就能实现准确的预测,引入过多无关的常识知识反而会干扰系统做出正确的识别。
技术实现思路
1、本发明提供了一种基于知识和数据协同推理的视觉关系识别方法,本发明避免了在融合知识和数据识别视觉关系时,建立的模型缺少对视觉上识别物体对关系的难易程度评估,从而过多引入外部信息导致识别困难的问题,通过为视觉关系表征引入独立的置信度评估分支,并且设计互信息最大化约束机制,使得模型能够根据视觉信息的复杂程度自适应的引入常识知识进行识别,从而实现视觉关系检测精度的提升,详见下文描述:
2、一种基于知识和数据协同推理的视觉关系识别方法,所述方法包括:
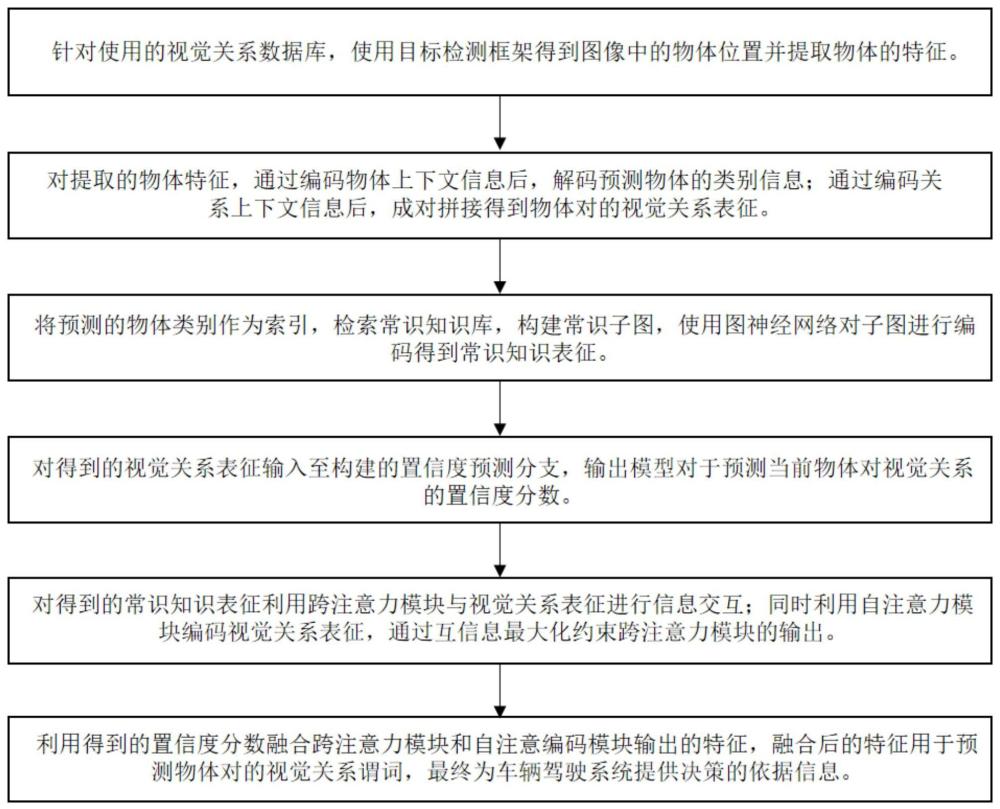
3、对输出的视觉关系表征和常识知识表征通过跨注意力模块进行信息交互,利用视觉关系表征经过自注意力编码输出的特征对其进行互信息最大化约束;
4、对输出的物体预测标签成对组合作为索引,在所使用的常识知识库中检索相关路径构成子图,经过图嵌入和图神经网络编码上下文信息后,将其平均池化输出的视觉关系表征输入至独立的多个全连接层构成的置信度估计分支,输出模型对预测当前物体对视觉关系的评估分数;
5、基于输出的置信度分数对输出的特征进行融合,输出的融合特征用于最终推理物体对的视觉关系谓词;
6、根据输出的视觉关系类别,车辆驾驶系统使用决策函数来计算最佳行动路径,控制系统接收决策指令并执行相应的物理操作。
7、其中,所述互信息最大化约束为:
8、
9、其中,表示以θt为可学习参数的全连接层网络,表示两者的互信息并且使其在网络优化过程中最大化。
10、其中,所述评估分数为:将输出的视觉关系表征输入至由多个全连接层构成的置信度估计分支中:
11、
12、其中,fconf(.)表示置信度估计分支,由θp为参数的多个全连接层构成,p表示模型对预测当前物体对视觉关系的评估分数。
13、其中,所述融合后的特征为:
14、
15、其中,r'i,j表示用于预测第i个和第j个物体之间关系的表征,将输出输入到softmax函数中,输出的最大概率分布数值即为识别出的类别为i和j的物体对之间的视觉关系类别。
16、其中,所述最佳行动路径为:
17、将预测的视觉关系类别输入到决策函数d({li,r'i,j,lj})中计算最佳行动路径:
18、d({li,r'i,j,lj})=w1s+w2v+w3e
19、其中,s代表与前车的安全距离分数,v代表与前车的相对速度分数,e代表环境因素分数,w1,w2,w3代表权重参数,反映不同因素的重要性,由{li,r'i,j,lj}分别经过参数矩阵w1,w2,w3映射得到。
20、一种基于知识和数据协同推理的视觉关系识别装置,所述装置包括:处理器和存储器,所述存储器中存储有程序指令,所述处理器调用存储器中存储的程序指令以使装置执行任一项所述的方法。
21、一种计算机可读存储介质,所述计算机可读存储介质存储有计算机程序,所述计算机程序包括程序指令,所述程序指令被处理器执行时使所述处理器执行任一项所述的方法。
22、本发明提供的技术方案的有益效果是:
23、1、本发明在融合知识与数据进行识别时,利用常识表征与视觉关系表征之间的互信息最大化进行约束,减少了视觉与常识信息交互后得到表征的语义模糊性;
24、2、本发明通过设计独立的置信度评估分支,显式地表示了模型基于视觉信息预测不同物体对关系的难易程度,从而实现自适应的常识知识引入来辅助数据进行关系识别;
25、3、将本发明的生成结果应用于自动驾驶系统中,有助于无人车更加准确理解道路上的交通状况、车辆和行人的位置以及它们之间的复杂关系,从而提高车辆的智能决策能力,规划更优的行驶路线,降低交通事故发生的概率。
技术特征:
1.一种基于知识和数据协同推理的视觉关系识别方法,其特征在于,所述方法包括:
2.根据权利要求1所述的一种基于知识和数据协同推理的视觉关系识别方法,其特征在于,所述互信息最大化约束为:
3.根据权利要求1所述的一种基于知识和数据协同推理的视觉关系识别方法,其特征在于,所述评估分数为:将输出的视觉关系表征输入至由多个全连接层构成的置信度估计分支中:
4.根据权利要求1所述的一种基于知识和数据协同推理的视觉关系识别方法,其特征在于,所述融合后的特征为:
5.根据权利要求1所述的一种基于知识和数据协同推理的视觉关系识别方法,其特征在于,所述最佳行动路径为:
6.一种基于知识和数据协同推理的视觉关系识别装置,其特征在于,所述装置包括:处理器和存储器,所述存储器中存储有程序指令,所述处理器调用存储器中存储的程序指令以使装置执行权利要求1-5中的任一项所述的方法。
7.一种计算机可读存储介质,其特征在于,所述计算机可读存储介质存储有计算机程序,所述计算机程序包括程序指令,所述程序指令被处理器执行时使所述处理器执行权利要求1-5中的任一项所述的方法。
技术总结
本发明公开了一种基于知识和数据协同推理的视觉关系识别方法及装置,包括:对输出的视觉关系表征和常识知识表征通过跨注意力模块进行信息交互,利用视觉关系表征经过自注意力编码输出的特征对其进行互信息最大化约束;对输出的物体预测标签成对组合作为索引,在所使用的常识知识库中检索相关路径构成子图,经过图嵌入和图神经网络编码上下文信息后,将其平均池化输出的视觉关系表征输入至独立的多个全连接层构成的置信度估计分支,输出模型对预测当前物体对视觉关系的评估分数;基于输出的置信度分数对输出的特征进行融合,输出的融合特征用于最终推理物体对的视觉关系谓词;根据输出的视觉关系类别,车辆驾驶系统使用决策函数来计算最佳行动路径,控制系统接收决策指令并执行相应的物理操作。
技术研发人员:刘安安,田宏硕,徐宁,张勇东
受保护的技术使用者:天津大学
技术研发日:
技术公布日:2024/4/17
- 还没有人留言评论。精彩留言会获得点赞!