大气污染物多模式融合核算模型后处理方法与流程
本发明涉及环境监测分析,具体为大气污染物多模式融合核算模型后处理方法。
背景技术:
1、工业园区是工业生产的集中地,对地方经济发展起着至关重要的作用,同时也是污染物排放的大户。
2、在生态文明建设过程中,控制工业园区大气污染物排放的强度和总量是地方空气环境水平稳定提高的关键点。准确核算工业园区污染物排放量是为园区制定合理排放指标、科学制定减排计划的基础。
3、目前尽管工业园区重点企业的有组织排污口大部分已经安装在线监测仪器,但仍然有无组织排放等排放形式难以通过在线监测手段进行监管。因此,在监测过程中存在数据缺失、仪器误差等问题。
4、已开发的大气污染物多模式融合核算模型虽然能够对园区实际排放量进行在线核算,但难以避免因监测仪器误差、数据缺失、核算模型误差等因素造成的核算结果无效或误差过大等问题。这也直接影响针对园区制定的合理排放指标、合理减排等计划。
5、有鉴于此,急需设计开发一套通过异常值识别和插值与外推数据进行大气污染物多模式融合核算模型后处理的方法。
技术实现思路
1、基于此,有必要针对现有大气污染物多模式融合核算模型因监测仪器误差、数据缺失、核算模型误差等因素造成的核算结果无效或误差过大等问题,提供一种大气污染物多模式融合核算模型后处理方法。
2、为实现上述目的,本发明采用了以下技术方案:
3、大气污染物多模式融合核算模型后处理方法,其包括以下步骤:
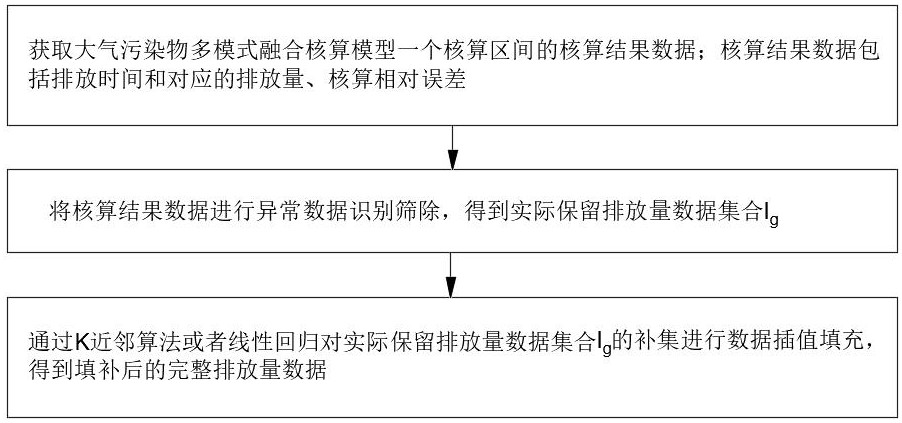
4、s1.获取大气污染物多模式融合核算模型一个核算区间的核算结果数据;核算结果数据包括排放时间和对应的排放量、核算相对误差;
5、s2.将核算结果数据进行异常数据识别筛除,得到实际保留排放量数据集合ig;其中,异常数据筛除的具体步骤如下:
6、s21.将核算结果数据中核算相对误差小于一个预设误差值c的数据筛选出,得到初步筛选数据;
7、s22.通过图基检验法和/或3σ原则迭代法计算出初步筛选数据中排放量的最大值阈值ymax和全部许可值yallow,将初步筛选数据中排放量位于二者区间内的数据筛选出,得到二次筛选数据;
8、s23.依据二次筛选数据中的排放时间时序,通过最大近邻差值法计算出相邻排放量的近邻差值序列di,并通过图基检验法和3σ原则迭代法计算出最大近邻差值阈值dmax,进而得出实际阈值d’max:;
9、s24.计算出实际保留排放量数据集合ig:
10、;其中,i表示数据编号,yi表示核算结果数据中的排放量绝对值序列,relerri表示核算结果数据中的核算相对误差序列;
11、s3.通过k近邻算法或者线性回归对实际保留排放量数据集合ig的补集进行数据插值填充,得到填补后的完整排放量数据。
12、进一步的,图基检验法计算初步筛选数据中排放量的最大值阈值ymax和全部许可值yallow的具体步骤如下:
13、s201.计算最大值阈值ymax:;其中,q3为初步筛选数据中排放量四分之三分位数,q1为初步筛选数据中排放量四分之一分位数;
14、s202.将最大值阈值ymax进行一次迭代,得到一次迭代后的异常高值阈值new_thres:;其中,new_q3为小于或等于最大值阈值ymax的初步筛选数据中排放量的四分之三分位数,new_q1为小于或等于最大值阈值ymax的初步筛选数据中排放量的四分之一分位数;
15、s203.重复步骤s202进行迭代,直到排放量平均值容差小于或等于0.001,或排放量中小于最大值阈值ymax的排放量数据量小于或等于总数据量的30%,此时迭代后的异常高值阈值为全部许可值yallow。
16、进一步的,在图基检验法不具备收敛性时,则替换使用3σ原则迭代法;3σ原则迭代法计算出初步筛选数据中排放量的最大值阈值ymax和全部许可值yallow的具体步骤如下:
17、s211.计算最大值阈值ymax:;其中,为排放量平均值,std(y)为排放量的标准差;
18、s212.将最大值阈值ymax进行一次迭代,得到一次迭代后的异常高值阈值new_thres:;其中,为小于或等于最大值阈值ymax的排放量平均值,为小于或等于最大值阈值ymax的排放量的标准差;
19、s213.重复步骤s212进行迭代,直到排放量平均值容差小于或等于0.001,或排放量中小于最大值阈值ymax的排放量数据量小于或等于总数据量的30%,此时迭代后的异常高值阈值为全部许可值yallow。
20、进一步的,对实际保留排放量数据集合ig的补集进行数据插值填充前,先获取实际保留排放量数据集合ig的元素个数,并与一个预设值b进行比较,根据比较结果作出如下决策:
21、(1)若;则判定采用k近邻算法对实际保留排放量数据集合ig的补集进行数据插值填充;
22、(2)若;则判定采用线性回归对实际保留排放量数据集合ig的补集进行数据插值填充。
23、进一步的,将核算结果数据进行异常数据识别筛除前,先判断核算区间内排放量的数据量n是否满足n>a;是则进行异常数据识别筛除;其中,a是预设常数。
24、进一步的,核算结果数据中的排放量为每小时污染物排放量;根据填补后的完整排放量数据计算预估污染物年排放总量annual_discharge:。
25、进一步的,大气污染物包括no2、pm2.5、vocs和so2。
26、进一步的,当以大气污染物no2、pm2.5、vocs作为核算因子时,采用图基检验法和3σ原则迭代法结合方式计算全部许可值yallow;
27、当以大气污染物so2作为核算因子时,单独采用3σ原则迭代法计算全部许可值yallow。
28、与现有技术相比,本发明的有益效果包括:
29、1、本发明通过对大气污染物多模式融合核算模型的核算结果数据进行多种异常值识别,有效移除异常值,并对缺失数据通过插值和外推方式填补,相对准确地复原缺失数据,提高了核算结果的准确度和稳定度;
30、2、本发明针对不同的大气污染物即不同的核算因子采用准确度更高的异常值识别方式,进一步有效移除异常值,提高核算结果的稳定度和准确度。
技术特征:
1.大气污染物多模式融合核算模型后处理方法,其用于对大气污染物多模式融合核算模型的核算异常数据进行处理;其特征在于,其包括以下步骤:
2.根据权利要求1所述的大气污染物多模式融合核算模型后处理方法,其特征在于,图基检验法计算所述初步筛选数据中排放量的最大值阈值ymax和全部许可值yallow的具体步骤如下:
3.根据权利要求2所述的大气污染物多模式融合核算模型后处理方法,其特征在于,在图基检验法不具备收敛性时,则替换使用3σ原则迭代法;3σ原则迭代法计算出所述初步筛选数据中排放量的最大值阈值ymax和全部许可值yallow的具体步骤如下:
4.根据权利要求1所述的大气污染物多模式融合核算模型后处理方法,其特征在于,对实际保留排放量数据集合ig的补集进行数据插值填充前,先获取实际保留排放量数据集合ig的元素个数,并与一个预设值b进行比较,根据比较结果作出如下决策:
5.根据权利要求1所述的大气污染物多模式融合核算模型后处理方法,其特征在于,将所述核算结果数据进行异常数据识别筛除前,先判断所述核算区间内排放量的数据量n是否满足n>a;是则进行异常数据识别筛除;其中,a是预设常数。
6.根据权利要求1所述的大气污染物多模式融合核算模型后处理方法,其特征在于,所述核算结果数据中的排放量为每小时污染物排放量;根据填补后的完整排放量数据计算预估污染物年排放总量annual_discharge:
7.根据权利要求6所述的大气污染物多模式融合核算模型后处理方法,其特征在于,大气污染物包括no2、pm2.5、vocs和so2。
8.根据权利要求7所述的大气污染物多模式融合核算模型后处理方法,其特征在于,当以大气污染物no2、pm2.5、vocs作为核算因子时,采用图基检验法和3σ原则迭代法结合方式计算全部许可值yallow;
9.一种计算机终端,其包括存储器、处理器以及存储在所述存储器上并可在所述处理器上运行的计算机程序,其特征在于,所述处理器执行所述程序时实现如权利要求1至8中任意一项所述的大气污染物多模式融合核算模型后处理方法的步骤。
10.一种计算机可读存储介质,其上存储有计算机程序,其特征在于,所述程序被处理器执行时,实现如权利要求1至8中任意一项所述的大气污染物多模式融合核算模型后处理方法的步骤。
技术总结
本发明提供大气污染物多模式融合核算模型后处理方法。该后处理方法包括以下步骤:S1.获取大气污染物多模式融合核算模型一个核算区间的核算结果数据;核算结果数据包括排放时间和对应的排放量、核算相对误差;S2.将核算结果数据进行异常数据识别筛除,得到实际保留排放量数据集合I<subgt;g</subgt;;S3.通过K近邻算法或者线性回归对实际保留排放量数据集合I<subgt;g</subgt;的补集进行数据插值填充,得到填补后的完整排放量数据。本发明通过对核算结果数据进行多种异常值识别,有效移除异常值,并对缺失数据通过插值和外推方式填补,相对准确地复原缺失数据,提高了核算结果的准确度和稳定度。
技术研发人员:王经顺,牛志春,赵瀚森,陈高,周进,郇洪江,刘峰均,陆晓波,吴柏莹,徐向凯
受保护的技术使用者:江苏省生态环境大数据有限公司
技术研发日:
技术公布日:2024/2/19
- 还没有人留言评论。精彩留言会获得点赞!