一种用于大模型问答的内容召回智能重排方法与流程
本发明涉及计算机,具体涉及一种用于大模型问答的内容召回智能重排方法。
背景技术:
1、基于大语言模型在实现问答功能时,由于大语言模型存在知识局限性,往往在回答用户问题时,会存在严重的知识幻觉问题。通常解决知识幻觉我们会使用rag(检索增强生成)技术来为大模型补充缺失的知识信息并限定回答范围,以此来杜绝大模型的知识幻觉。传统的rag实现方式通过将长文本按照一定的策略进行切分,然后按照片段进行检索,这种处理方式丢失了全文整体的语意信息,也忽略了片段之间的内在关联,因此检索的质量普遍偏低,准确率一般不超过50%。
技术实现思路
1、本发明的目的在于提供一种用于大模型问答的内容召回智能重排方法用于解决上述问题。
2、为实现上述目的,本发明采用以下技术方案:
3、一种用于大模型问答的内容召回智能重排方法,包括以下步骤:
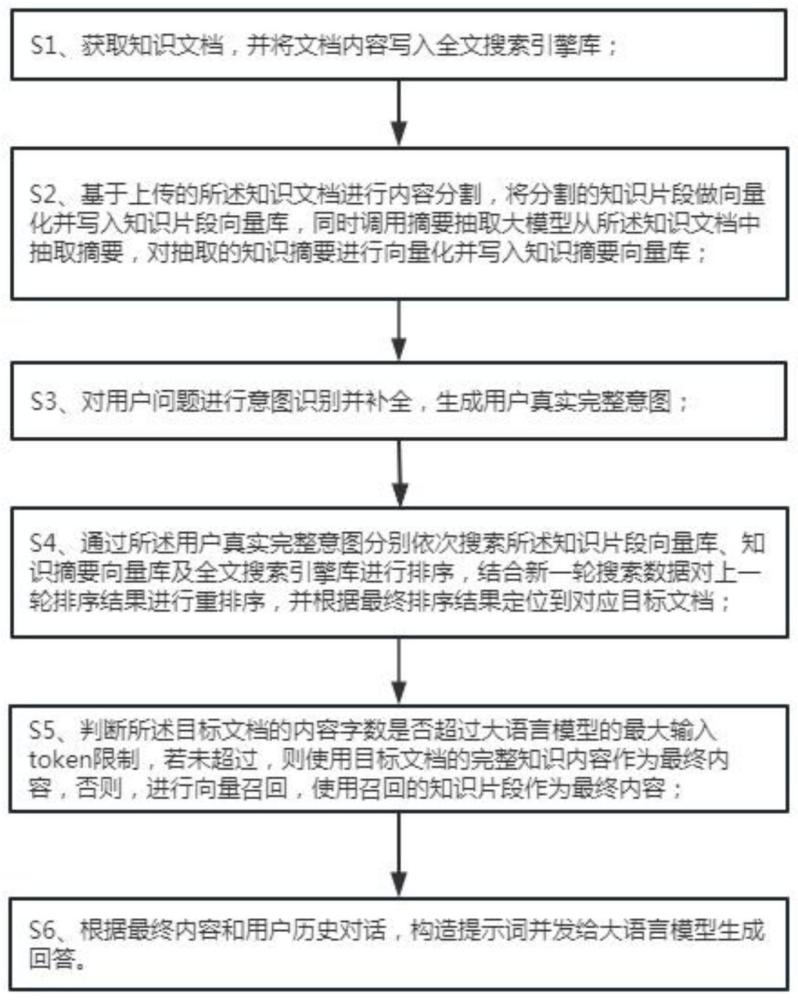
4、s1、获取知识文档,并将文档内容写入全文搜索引擎库;
5、s2、基于上传的所述知识文档进行内容分割,将分割的知识片段做向量化并写入知识片段向量库,同时调用摘要抽取大模型从所述知识文档中抽取摘要,对抽取的知识摘要进行向量化并写入知识摘要向量库;
6、s3、对用户问题进行意图识别并补全,生成用户真实完整意图;
7、s4、通过所述用户真实完整意图分别依次搜索所述知识片段向量库、知识摘要向量库及全文搜索引擎库进行排序,结合新一轮搜索数据对上一轮排序结果进行重排序,并根据最终排序结果定位到对应目标文档;
8、s5、判断所述目标文档的内容字数是否超过大语言模型的最大输入token限制,若未超过,则使用目标文档的完整知识内容作为最终内容,否则,进行向量召回,使用召回的知识片段作为最终内容;
9、s6、根据最终内容和用户历史对话,构造提示词并发给大语言模型生成回答。
10、优选地,步骤s3具体为:通过意图补全大模型对用户输入的问题进行意图识别,并根据用户历史对话补全用户意图,生成用户真实完整意图。
11、优选地,步骤s4具体为:
12、s41、通过用户真实完整意图从知识片段向量库进行向量召回,选取片段数据,进行归一化换算处理,然后根据知识文档id进行分组,加权汇总计算每个分组的总分,然后进行初步排序;
13、s42、通过用户真实完整意图从知识摘要向量库进行向量召回,选取摘要数据,进行归一化换算处理,合并知识片段和知识摘要的文档列表,并根据两种向量召回结果的文档分数重新计算文档二次汇总分数,然后进行重排序;
14、s43、通过用户真实完整意图对全文搜索引擎库进行分词搜索,并将返回的全文搜索数据进行归一化换算处理,合并向量召回和全文搜索的文档列表,并根据向量召回结果和全文搜索结果的文档分数重新计算文档最终汇总分数,然后进行最终排序,生成最终排序结果,得出分数最高的前n篇目标文档,并对目标文档位置进行定位。
15、优选地,所述归一化换算处理具体为:对相似度进行最大最小归一化换算,把原始的相似库浮点数据转换成百分制数据。
16、优选地,步骤s41具体为:
17、s411、通过用户真实完整意图从知识片段向量库进行向量召回,选取指定相似度以上及指定条数的片段数据;
18、s412、对片段数据的相似度进行最大最小归一化换算,把原始的相似库浮点数据转换成百分制数据;
19、s413、将片段数据根据知识文档id进行分组,每组取topk个片段进行衰减加权分数计算,计算出每个分组的加权总分然后进行初步排序。
20、采用上述技术方案后,本发明与背景技术相比,具有如下有益效果:
21、本发明提供一种用于大模型问答的内容召回智能重排方法,通过意图识别结合用户对话历史,提高用于召回文档文本的准确性,同时结合多种召回方式通过多次的权重计算和重排序,最终缩小了向量召回范围,提高了召回相关内容的精准度,解决简单召回逻辑的局限性,提高通过向量查找定位文档的全面性。
技术特征:
1.一种用于大模型问答的内容召回智能重排方法,其特征在于:包括以下步骤:
2.如权利要求1所述的一种用于大模型问答的内容召回智能重排方法,其特征在于:步骤s3具体为:通过意图补全大模型对用户输入的问题进行意图识别,并根据用户历史对话补全用户意图,生成用户真实完整意图。
3.如权利要求1所述的一种用于大模型问答的内容召回智能重排方法,其特征在于:步骤s4具体为:
4.如权利要求3所述的一种用于大模型问答的内容召回智能重排方法,其特征在于:所述归一化换算处理具体为:对相似度进行最大最小归一化换算,把原始的相似库浮点数据转换成百分制数据。
5.如权利要求4所述的一种用于大模型问答的内容召回智能重排方法,其特征在于:步骤s41具体为:
技术总结
本发明公开了一种用于大模型问答的内容召回智能重排方法,包括以下步骤:S1、获取知识文档,并将文档内容写入全文搜索引擎库;S2、基于上传的所述知识文档进行内容分割,将分割的知识片段做向量化并写入知识片段向量库,同时调用摘要抽取大模型从所述知识文档中抽取摘要,对抽取的知识摘要进行向量化并写入知识摘要向量库;S3、对用户问题进行意图识别并补全,生成用户真实完整意图;S4、通过所述用户真实完整意图分别依次搜索所述知识片段向量库、知识摘要向量库及全文搜索引擎库进行排序,结合新一轮搜索数据对上一轮排序结果进行重排序,并根据最终排序结果定位到对应目标文档。
技术研发人员:吴炳坤,姚锋,黄世勇,王鹏程
受保护的技术使用者:众数(厦门)信息科技有限公司
技术研发日:
技术公布日:2024/4/17
- 还没有人留言评论。精彩留言会获得点赞!