基于视频识别对激光雷达点云数据中标志牌的标记方法
本发明涉及计算机视觉和自动驾驶领域,特别涉及一种基于视频识别对激光雷达点云数据中标志牌的标记方法。
背景技术:
1、在自动驾驶领域,激光雷达是一种重要的传感器,它可以通过发射和接收激光脉冲,测量周围环境的距离和反射率,生成三维点云数据。点云数据是一种无序的、稀疏的、高维的数据结构,它包含了大量的信息,但也存在很多噪声和不确定性。为了提高自动驾驶中的环境感知能力,需要对点云数据进行语义分割,即将点云数据中的每个点分配到不同的类别,如道路、车辆、行人、建筑物等。语义分割可以帮助自动驾驶系统理解周围环境的结构和状态,从而做出合理的决策和控制。然而,点云数据语义分割是一项具有挑战性的任务,它需要处理点云数据的无序性、稀疏性、高维性等特点,以及不同场景下的多样性和复杂性。为了提高点云数据语义分割的效果和效率,一种常用的方法是利用其他传感器提供的辅助信息,如视频、图像、雷达等。视频是一种常见的传感器,它可以提供丰富的颜色、纹理、形状等信息,以及动态变化的场景。视频识别是一门研究如何从视频中提取有用信息的科学,它涉及图像处理,模式识别,机器学习等多个方面。
技术实现思路
1、为了克服现有技术的上述缺点与不足,本发明的目的在于提供一种基于视频识别对激光雷达点云数据中标志牌的标记方法,本发明主要基于颜色信息和语义信息准确的对标志牌所属点云进行标记。
2、本发明的目的通过以下技术方案实现:
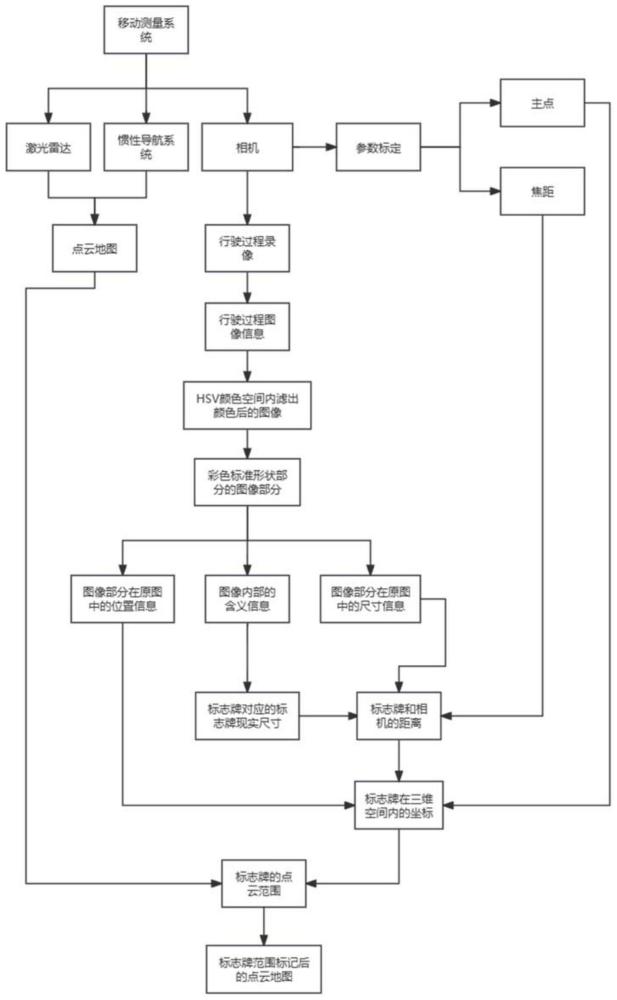
3、一种基于视频识别对激光雷达点云数据中标志牌的标记方法,包括:
4、在试验车上设置激光雷达、惯性导航系统及相机;
5、相机获取试验车行驶过程中的图像视频数据,将视频数据进行分割,每一张图片包括某一时刻的试验车行驶的画面;
6、对每一张图片进行hsv滤色,得到带颜色部分的图像,对图像内带颜色部分的形状进行识别,截取出带颜色的规则图形;
7、对带颜色的规则图形进行识别,得到标志牌在原图中的位置信息、标志牌的含义信息及标志牌在原图中的尺寸信息;
8、根据标志牌在原图中的尺寸信息,利用相机成像原理,得到标志牌和相机的距离;根据含义信息得到标志牌对应的现实尺寸;
9、根据标志牌和相机的距离,以及标志牌在图像中的位置,计算标志牌在以相机为原点的三维坐标系中的坐标;
10、通过三维转换,将标志牌在以相机为原点的三维坐标系中的坐标转换到以激光雷达为原点的三维坐标系中的坐标;
11、根据标志牌在以激光雷达为原点的三维坐标系中的坐标,从云数据中找出与之最近或最匹配的点,并将其作为标志牌所在位置,并给其添加相应的属性信息,完成标记。
12、进一步,所述通过惯性导航系统及激光雷达获得点云数据。
13、进一步,所述激光雷达和相机的位置信息包括在空间中相对车辆的三维坐标,以及相对车辆的偏移角度。
14、进一步,截取出带颜色的规则图形后还包括将高度与宽度不对称的图像进行拉伸形成标准形态。
15、进一步,对带颜色的规则图形进行识别,采用机器学习及深度学习网络。
16、进一步,所述相机成像原理是指将三维空间中物体投影到二维平面上,并根据相似三角形原理建立三维坐标和二维坐标之间的关系。
17、进一步,寻找最近或最匹配的点采用最近邻搜索或最小二乘法。
18、与现有技术相比,本发明具有以下优点和有益效果:
19、(1)本方法可以将激光雷达点云数据和相机图像数据进行配准,并且将图像数据中提取出来的信息添加到点云数据中,从而实现数据融合。
20、(2)通过本方法进行的数据融合,可以更好地对道路环境进行三维重建和分析。
技术特征:
1.一种基于视频识别对激光雷达点云数据中标志牌的标记方法,其特征在于,包括:
2.根据权利要求1所述的标记方法,其特征在于,所述通过惯性导航系统及激光雷达获得点云数据。
3.根据权利要求1所述的标记方法,其特征在于,所述激光雷达和相机的位置信息包括在空间中相对车辆的三维坐标,以及相对车辆的偏移角度。
4.根据权利要求1所述的标记方法,其特征在于,截取出带颜色的规则图形后还包括将高度与宽度不对称的图像进行拉伸形成标准形态。
5.根据权利要求1所述的标记方法,其特征在于,对带颜色的规则图形进行识别,采用机器学习及深度学习网络。
6.根据权利要求1所述的标记方法,其特征在于,所述相机成像原理是指将三维空间中物体投影到二维平面上,并根据相似三角形原理建立三维坐标和二维坐标之间的关系。
7.根据权利要求1-6任一项所述的标记方法,其特征在于,寻找最近或最匹配的点采用最近邻搜索或最小二乘法。
技术总结
本发明公开了一种基于视频识别对激光雷达点云数据中标志牌的标记方法,包括照片滤色、形状分析、拉伸处理、信息识别、照片坐标输出、标志牌对应、深度处理、标志牌在空间中的坐标计算、坐标系的转化、点云标记。本发明为基于道路点云化三维场景下的标志牌识别提供了理论基础和分析计算方法。
技术研发人员:王晓飞,王子旗
受保护的技术使用者:华南理工大学
技术研发日:
技术公布日:2024/4/29
- 还没有人留言评论。精彩留言会获得点赞!