多机器人协同搜索任务自适应角色选择方法及系统
本发明涉及多机器人协同序列决策,尤其涉及一种多机器人协同搜索任务自适应角色选择方法及系统。
背景技术:
1、本部分的陈述仅仅是提供了与本发明相关的背景技术信息,不必然构成在先技术。
2、多机器人协同区域搜索由于其广泛的应用是机器人领域一个较为基础的研究问题,例如火星探索、灾难响应、或城市搜索与救援等。不同于单机器人系统,多机器人系统因为其能在多机器人之间达成协同决策从而提高任务完成效率且能保持弹性决策等优势使其在时间较为紧迫的任务中有更大的优势。
3、在多机器人协同区域搜索任务决策的过程中,要求机器人执行协同构图(探索)的同时搜索更多的目标(覆盖)。在决策过程中,机器人需1)感知环境以收集更多关于目标的信息;2)营救目标;3)与其余机器人协同在较短时间内完成在已探索区域内营救更多目标。
4、处理复杂任务最有效的方式是分解为较小且较为简单的子任务。因此,过去很多研究集中将区域搜索任务分解为两个不同的子任务:探索和覆盖,并在不同的两个阶段完成。在分解的方法中,机器人首先选择一个由例如泰森多边形分解算法的细胞分解算法生成的子区域,其次机器人沿着由覆盖规划算法计算出的规划路径扫描整个子区域完成覆盖任务。然而,完全分开处理探索与覆盖任务会有次优解和计算成本的增加,从而限制整体任务完成效率。因此一个统一处理子任务的方法被期望研究以最大化资源利用率,提高效率并且得到最优解。
5、目前有统一的方法将同时覆盖与探索任务建模为组合优化问题。他们将探索与覆盖问题离散化到一个图结构的环境中,通过在图结构上学习所有子任务与机器人之间的空间位置关系从而实现子任务的同时执行。完全统一的方法能动态的提升机器人的决策能力,但其任务规划和任务执行的耦合造成难训练的问题。为了降低训练复杂度并且实现机器人之间显式的合作,从高层的角度将任务规划和任务执行解藕开是较为有效的方案,并且对复杂任务更深入的理解是需要解藕。有的研究已开始展开对同时覆盖与探索任务进行解藕处理,但是该方法对于收益计算和子任务的分配方式很启发式,其算法计算复杂度在环境规模变大时会超越计算机的承受范围。
技术实现思路
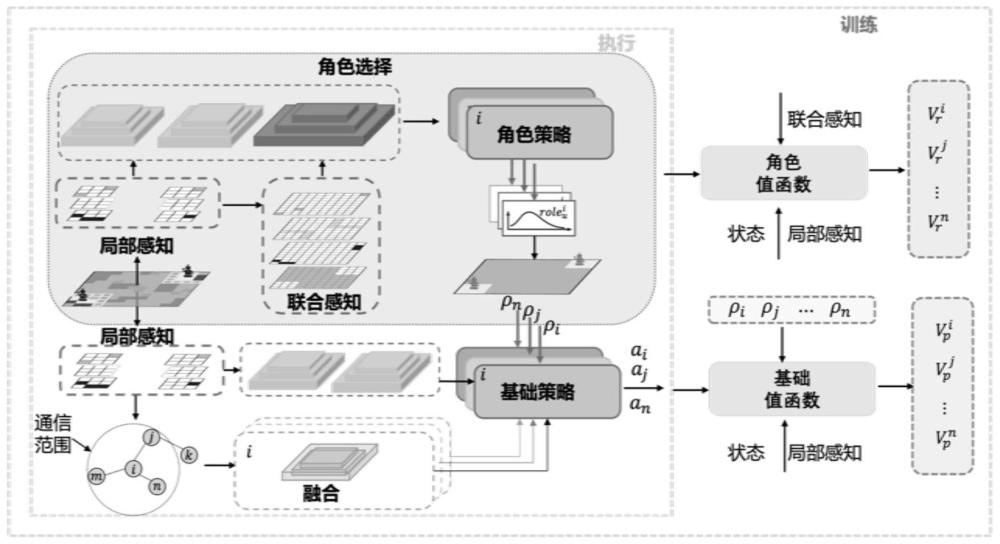
1、为了解决上述问题,本发明提出了一种多机器人协同搜索任务自适应角色选择方法及系统,构建角色选择模块将任务规划从任务执行的上层角度解藕开,基于深度强化学习训练了分布式的角色策略完成角色选择,引导机器人在子任务之间进行选择;在引导机器人基于角色执行相应的子任务时,基于评论-演说家框架训练了基础策略。
2、在一些实施方式中,采用如下技术方案:
3、一种多机器人协同搜索任务自适应角色选择方法,包括:
4、定义角色动作空间为2个离散值:[探索,覆盖];
5、获取局部感知信息和联合感知信息获取的信息输入至角色选择网络,输出角色动作其中,所述局部感知信息包括障碍物地图、已探索地图、已覆盖地图和位置地图;所述联合感知信息包括联合探索地图和联合覆盖地图;
6、将局部感知信息以及输出的角色动作输入至基础动作网络,输出机器人基础动作at与环境交互。
7、当机器人接受探索角色动作时,则期望机器人朝着局部感受野内离自己最近的边界点移动;当机器人接受覆盖角色时,则期望机器人朝着局部感受野内离自己最近的目标点移动。
8、在另一些实施方式中,采用如下技术方案:
9、一种多机器人协同搜索任务自适应角色选择系统,包括:
10、动作空间模块,用于定义角色动作空间为2个离散值:[探索,覆盖];
11、角色选择模块,用于获取局部感知信息和联合感知信息获取的信息输入至角色选择网络,输出角色动作其中,所述局部感知信息包括障碍物地图、已探索地图、已覆盖地图和位置地图;所述联合感知信息包括联合探索地图和联合覆盖地图;
12、基础动作输出模块,用于将局部感知信息以及输出的角色动作输入至基础动作网络,输出机器人基础动作at与环境交互。
13、在另一些实施方式中,采用如下技术方案:
14、一种终端设备,其包括处理器和存储器,处理器用于实现指令;存储器用于存储多条指令,所述指令适于由处理器加载并执行上述的多机器人协同搜索任务自适应角色选择方法。
15、与现有技术相比,本发明的有益效果是:
16、(1)本发明提出了一个统一的方法来完成协同构图以感知更多的区域(探索)的同时搜索与定位目标(覆盖),避免了独立完成子任务时面临的算法次优解与高复杂度计算成本。分层强化学习算法的执行将任务规划与任务执行解藕开,这极大降低了算法训练的复杂度。首先,“角色”的概念被嵌入到任务规划层完成角色选择,这使得机器人能从上层的角度基于环境状态学习到自身的角色。除此之外,决策切换机制使两个时间步之间的角色切换得到保障,使得探索与覆盖任务两个子任务相互促进。其次,任务执行由基础策略完成,使机器人在上层角色网络的输出角色和局部观测信息的条件下学会如何规划。
17、(2)本发明针对多机器人协同搜索的基于强化学习的自主且自适应的角色选择方法。其高层的任务规划通过角色选择框架完成,其由多智能体强化学习训练的角色选择网络(角色策略)组成,这能引导机器人自主选择当前状态下的角色实现其自身技能的最大化。在序列角色规划的过程中,智能的角色切换机制使不同角色之间相互促进以动态的提高性能。另外,本方法中多机器人的任务执行通过基础动作网络(基础策略)完成,是以上层角色策略输出的角色为条件,基于局部感知信息进行决策,使得基础策略的能力表征了探索或覆盖能力。
18、(3)本发明引入角色选择模块进行任务规划,并基于此角色动作完成任务执行。以联合观测为依据的所有机器人的角色动作是对动态区域搜索环境的高级理解。此设计促进本发明对应的多机器人系统适应于不同规模环境或包含更多机器人的高复杂度环境中。
19、本发明的其他特征和附加方面的优点将在下面的描述中部分给出,部分将从下面的描述中变得明显,或通过本方面的实践了解到。
技术特征:
1.一种多机器人协同搜索任务自适应角色选择方法,其特征在于,包括:
2.如权利要求1所述的一种多机器人协同搜索任务自适应角色选择方法,其特征在于,当机器人接受探索角色动作时,则期望机器人朝着局部感受野内离自己最近的边界点移动;当机器人接受覆盖角色时,则期望机器人朝着局部感受野内离自己最近的目标点移动。
3.如权利要求1所述的一种多机器人协同搜索任务自适应角色选择方法,其特征在于,机器人基于局部感知信息识别边界点或目标点,同时利用联合感知信息在探索与覆盖之间评估期望回报;具体的期望计算如下:
4.如权利要求1所述的一种多机器人协同搜索任务自适应角色选择方法,其特征在于,为每个机器人定义探索奖励re和覆盖奖励rc,角色选择网络的奖励函数为rt=αre+βrc,α和β分别是探索和覆盖角色的奖励权重系数。
5.如权利要求1所述的一种多机器人协同搜索任务自适应角色选择方法,其特征在于,所述角色选择网络使用基于评论-演说家(actor-critic)r结构的集中式训练分布式执行架构,使用多智能体强化学习算法训练角色选择网络;在集中式训练阶段,actorr网络用于输出角色动作,criticr网络计算状态值函数vr(s),并得到优势函数ar(s,ρ),用于评判由actorr网络计算的角色动作的合理性。
6.如权利要求5所述的一种多机器人协同搜索任务自适应角色选择方法,其特征在于,所述优势函数ar(s,ρ)具体为:
7.如权利要求1所述的一种多机器人协同搜索任务自适应角色选择方法,其特征在于,采纳卷积神经网络作为编码器,对局部感知信息进行编码,生成一个编码向量;所述编码向量在所有机器人之间共享;将输出角色动作与局部感知信息的编码向量进行拼接,作为基础动作网络的输入;
8.如权利要求1所述的一种多机器人协同搜索任务自适应角色选择方法,其特征在于,在基础动作网络的训练阶段,设置了两个不同的奖励:探索奖励re和覆盖奖励rc;得到每个时间t基础动作网络的奖励函数为:
9.一种多机器人协同搜索任务自适应角色选择系统,其特征在于,包括:
10.一种终端设备,其包括处理器和存储器,处理器用于实现指令;存储器用于存储多条指令,其特征在于,所述指令适于由处理器加载并执行权利要求1-7任一项所述的多机器人协同搜索任务自适应角色选择方法。
技术总结
本发明公开了一种多机器人协同搜索任务自适应角色选择方法及系统,包括:定义角色动作空间为2个离散值:[探索,覆盖];获取局部感知信息和联合感知信息获取的信息输入至角色选择网络,输出角色动作其中,所述局部感知信息包括障碍物地图、已探索地图、已覆盖地图和位置地图;所述联合感知信息包括联合探索地图和联合覆盖地图;将局部感知信息以及输出的角色动作输入至基础动作网络,输出机器人基础动作a<subgt;t</subgt;与环境交互。本发明中多机器人的任务执行通过基础动作网络(基础策略)完成,是以上层角色策略输出的角色为条件,基于局部感知信息进行决策,使得基础策略的能力表征了探索或覆盖能力。
技术研发人员:程吉禹,朱莉娜,刘跃虎,张伟,张浩
受保护的技术使用者:山东大学
技术研发日:
技术公布日:2024/4/24
- 还没有人留言评论。精彩留言会获得点赞!