一种基于多模态模型的属性标注方法及装置与流程
本申请属于属性识别多模态预标注,特别涉及一种基于多模态模型的属性标注方法及装置。
背景技术:
1、在当今的计算机视觉应用中,准确获取和利用行人的属性信息具有极大的重要性。行人属性识别是计算机视觉领域中的一项关键任务,它的目标是从行人的图像或视频中识别和描述不同的属性或特征,如性别、年龄、服装风格等,这些属性信息可以帮助计算机更好地理解和描述图像中的人物,对于行人追踪、行人重识别、行为分析、特定特征行人搜索等安防监控场景非常重要。
2、然而,传统的行人属性识别方法存在一些挑战。首先,属性的标注工作需要耗费大量人力和时间,因为属性种类繁多且标注过程困难。例如,年龄可以分为幼儿、青少年、青年、中年和老年,衣服颜色可以包括红、橙、黄、绿、紫、粉、黑、白、灰和棕十种选项,这使得标注工作繁重且容易出错。其次,传统方法通常依赖于预先训练好的属性模型,这些模型的属性是固定的,如果要在不同场景中新增或修改属性,需要重新训练模型,成本高且不易扩展。
3、因此,希望有一种技术方案来克服或至少减轻现有技术的至少一个上述缺陷。
技术实现思路
1、本申请的目的是提供了一种基于多模态模型的属性标注方法及装置,以解决现有技术存在的属性标注效率低、质量差等问题。
2、本申请的技术方案是:
3、本申请的第一个方面提供了一种基于多模态模型的属性标注方法,包括:
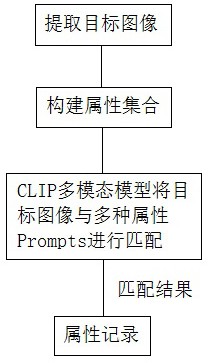
4、步骤一、获取视频,并从所述视频中提取目标图像;
5、步骤二、构建属性集合,所述属性集合中包含不同属性信息的文本描述;
6、步骤三、将所述目标图像以及所述属性集合输入到多模态模型中,得到所述目标图像与各个属性信息的文本描述的匹配值,并根据所述匹配值确定所述目标图像中包含的属性信息。
7、在本申请的至少一个实施例中,步骤一中,所述获取视频,并从所述视频中提取目标图像,包括:
8、s11、获取视频,并对所述视频进行间隔采样,得到多帧图像;
9、s12、采用目标检测网络分别对每一帧图像进行目标检测,识别出所述图像中的各个目标,并生成各个所述目标的目标检测框,所述目标包括行人和/或车辆;
10、s13、根据所述目标检测框对所述图像进行裁剪,得到目标图像。
11、在本申请的至少一个实施例中,所述属性集合包括多个属性子集合,每个所述属性子集合中包含同一属性下的多个属性信息的文本描述,且每个所述属性信息具有多个文本描述。
12、在本申请的至少一个实施例中,步骤三中,所述将所述目标图像以及所述属性集合输入到多模态模型中,得到所述目标图像与各个属性信息的文本描述的匹配值,并根据所述匹配值确定所述目标图像中包含的属性信息,包括:
13、s31、将所述目标图像以及所述属性集合输入到多模态模型中;
14、s32、确定一个待识别的属性,所述多模态模型将所述目标图像与该属性对应的属性子集合进行匹配,得到匹配值最高的文本描述,并从所述文本描述提取出该属性的属性信息;
15、s33、循环s32识别出所有待识别的属性的属性信息。
16、在本申请的至少一个实施例中,s32中,通过所述多模态模型将所述目标图像与该属性对应的属性子集合进行匹配,得到匹配值最高的文本描述的过程包括:
17、s321、通过所述多模态模型的图像编码器对所述目标图像进行编码,通过所述多模态模型的文本编码器对所述属性子集合进行编码,并采用线性投影将每个编码器的特征映射为嵌入空间的向量表示:
18、
19、
20、其中,eimg 为目标图像i的编码,维度为[1,d_e], etext为属性子集合d的编码,维度为[n,d_e];
21、s322、通过内积计算目标图像的编码与属性子集合中每个文本描述的编码之间的相似性分数,得到维度为[1,n]的分数矩阵;
22、s323、通过softmax函数将所述分数矩阵归一化为0到1之间的概率分布:
23、
24、其中,概率分布中的各个概率值分别表示目标图像与对应文本描述的匹配概率,获取匹配概率最高的文本描述。
25、在本申请的至少一个实施例中,所述多模态模型为clip多模态模型、blip多模态模型、imagebind多模态模型、chatgpt4多模态模型中的一种。
26、在本申请的至少一个实施例中,还包括步骤四、将所述目标图像中包含的属性信息记录在标签文件或数据库中。
27、本申请的第二个方面提供了一种基于多模态模型的属性标注装置,包括:
28、目标图像提取模块,用于获取视频,并从所述视频中提取目标图像;
29、属性集合构建模块,用于构建属性集合,所述属性集合中包含不同属性信息的文本描述;
30、属性标注模块,用于将所述目标图像以及所述属性集合输入到多模态模型中,得到所述目标图像与各个属性信息的文本描述的匹配值,并根据所述匹配值确定所述目标图像中包含的属性信息;
31、属性记录模块,用于将所述目标图像中包含的属性信息记录在标签文件或数据库中。
32、本申请的第三个方面提供了一种电子设备,包括存储器、处理器以及存储在所述存储器中并能够在所述处理器上运行的计算机程序,所述处理器执行所述计算机程序时实现如上所述的基于多模态模型的属性标注方法。
33、本申请的第四个方面提供了一种计算机可读存储介质,所述计算机可读存储介质存储有计算机程序,所述计算机程序被处理器执行时能够实现如上所述的基于多模态模型的属性标注方法。
34、发明至少存在以下有益技术效果:
35、本申请的基于多模态模型的属性标注方法,可以实现对目标属性的准确识别和预标注,减轻了手动标注工作负担,提高了计算机视觉应用中目标属性信息的获取效率和精确性;允许用户自定义属性集合,无需受限于固定的属性模型,这使得标注目标属性更加灵活,适应不同的应用需求。
技术特征:
1.一种基于多模态模型的属性标注方法,其特征在于,包括:
2.根据权利要求1所述的基于多模态模型的属性标注方法,其特征在于,步骤一中,所述获取视频,并从所述视频中提取目标图像,包括:
3.根据权利要求1所述的基于多模态模型的属性标注方法,其特征在于,所述属性集合包括多个属性子集合,每个所述属性子集合中包含同一属性下的多个属性信息的文本描述,且每个所述属性信息具有多个文本描述。
4.根据权利要求3所述的基于多模态模型的属性标注方法,其特征在于,步骤三中,所述将所述目标图像以及所述属性集合输入到多模态模型中,得到所述目标图像与各个属性信息的文本描述的匹配值,并根据所述匹配值确定所述目标图像中包含的属性信息,包括:
5.根据权利要求4所述的基于多模态模型的属性标注方法,其特征在于,s32中,通过所述多模态模型将所述目标图像与该属性对应的属性子集合进行匹配,得到匹配值最高的文本描述的过程包括:
6.根据权利要求5所述的基于多模态模型的属性标注方法,其特征在于,所述多模态模型为clip多模态模型、blip多模态模型、imagebind多模态模型、chatgpt4多模态模型中的一种。
7.根据权利要求1所述的基于多模态模型的属性标注方法,其特征在于,还包括步骤四、将所述目标图像中包含的属性信息记录在标签文件或数据库中。
8.一种基于多模态模型的属性标注装置,其特征在于,包括:
9.一种电子设备,包括存储器、处理器以及存储在所述存储器中并能够在所述处理器上运行的计算机程序,其特征在于,所述处理器执行所述计算机程序时实现如权利要求1至7中任意一项所述的基于多模态模型的属性标注方法。
10.一种计算机可读存储介质,所述计算机可读存储介质存储有计算机程序,其特征在于,所述计算机程序被处理器执行时能够实现如权利要求1至7中任意一项所述的基于多模态模型的属性标注方法。
技术总结
本申请属于属性识别多模态预标注技术领域,特别涉及一种基于多模态模型的属性标注方法及装置。方法包括:步骤一、获取视频,并从所述视频中提取目标图像;步骤二、构建属性集合,所述属性集合中包含不同属性信息的文本描述;步骤三、将所述目标图像以及所述属性集合输入到多模态模型中,得到所述目标图像与各个属性信息的文本描述的匹配值,并根据所述匹配值确定所述目标图像中包含的属性信息。本申请可以实现对目标属性的准确识别和预标注,减轻了手动标注工作负担,提高了计算机视觉应用中目标属性信息的获取效率和精确性;允许用户自定义属性集合,无需受限于固定的属性模型,这使得标注目标属性更加灵活,适应不同的应用需求。
技术研发人员:贾哲恒,唐矗,蒲立
受保护的技术使用者:北京积加科技有限公司
技术研发日:
技术公布日:2024/3/24
- 还没有人留言评论。精彩留言会获得点赞!