一种基于湖仓一体的数据编目方法及系统与流程
本发明涉及数据管理领域,尤其涉及一种基于湖仓一体的数据编目方法及系统。
背景技术:
1、数据仓库在企业决策支持中扮演着重要角色,但传统数据仓库也存在一些局限性。数据仓库的主要特点是只能处理结构化数据,并且数据仓库的建设和维护成本较高,需要预先定义数据模型和结构,对于快速变化的数据需求和数据类型可能不够灵活。随着数据湖技术的发展和成熟,越来越多地将注意力放在原始和原生数据的收集、存储和分析上。数据湖提供了一种灵活的方式来存储各种类型和格式的数据,以满足不断增长的数据需求,但是数据湖缺乏一些关键特性,如不支持事务、数据缺乏一致性、缺乏隔离性、无法保证数据质量等,导致数据湖管理复杂,如果管理不善,数据湖将会退化成数据沼泽。湖仓一体则是将数据湖和数据仓库的概念结合起来的方法。它借鉴了数据湖的灵活性和数据仓库的结构化和性能优势。湖仓一体的思想是在数据湖中建立一个有组织的、结构化的数据层,使数据能够更好地用于分析和决策支持。这种方法使用数据湖作为数据的存储和处理平台,并在其之上构建一层类似于数据仓库的结构,包括数据模型、数据集成和数据管理的元素。湖仓一体旨在兼顾数据湖的灵活性和数据仓库的可靠性,以提供高质量的数据分析和洞察力。
2、但基于湖仓一体的系统架构存在一定的实时性问题,特别是在处理大规模数据集时。由于数据湖中的数据通常以原始形式存储,没有预定义的索引或优化结构,因此查询需要更多的计算和扫描操作,导致查询的响应时间增长。其次,湖仓一体的数据处理通常涉及大规模数据的提取、转换和加载(etl)操作。处理大规模数据集需要更长的时间,尤其是在数据湖中存在大量的原始数据时。数据处理性能受到系统架构、硬件资源和数据处理算法的影响。湖仓一体同时包含批量数据和实时数据。当数据源更新时,确保数据湖中的数据与源数据的一致性也是一个挑战。特别是在具有高速数据流的实时情况下,确保数据的同步和一致性可能需要采取适当的数据复制和同步机制。
技术实现思路
1、本发明的目的在于克服现有湖仓一体架构在面对大规模数据管理时存在的问题,提供了一种基于湖仓一体的数据编目方法及系统。旨在实现数据的集成、整合和编目,以提供更方便、可靠和高效的并发数据访问和分析。
2、本发明的目的是通过以下技术方案来实现的:
3、第一方面,提供一种基于湖仓一体的数据编目方法,包括:
4、建设数据湖,并将外部数据源中的数据提取到数据湖中;
5、清洗数据湖中的原始数据;
6、为清洗后的数据添加元数据信息并采用多级编目架构进行编目;其中,所述多级编目架构中每个目录针对特定的数据领域进行配置和管理,当外部数据源更新时,通过后台线程定时刷新拉取最新的数据并更新元数据。
7、优选地,所述清洗数据湖中的原始数据,包括:
8、使用etl工具结合数据处理语言对原始数据进行转换、整合和规范化;应用数据清洗技术和规则去除重复数据、处理缺失值以及纠正数据错误。
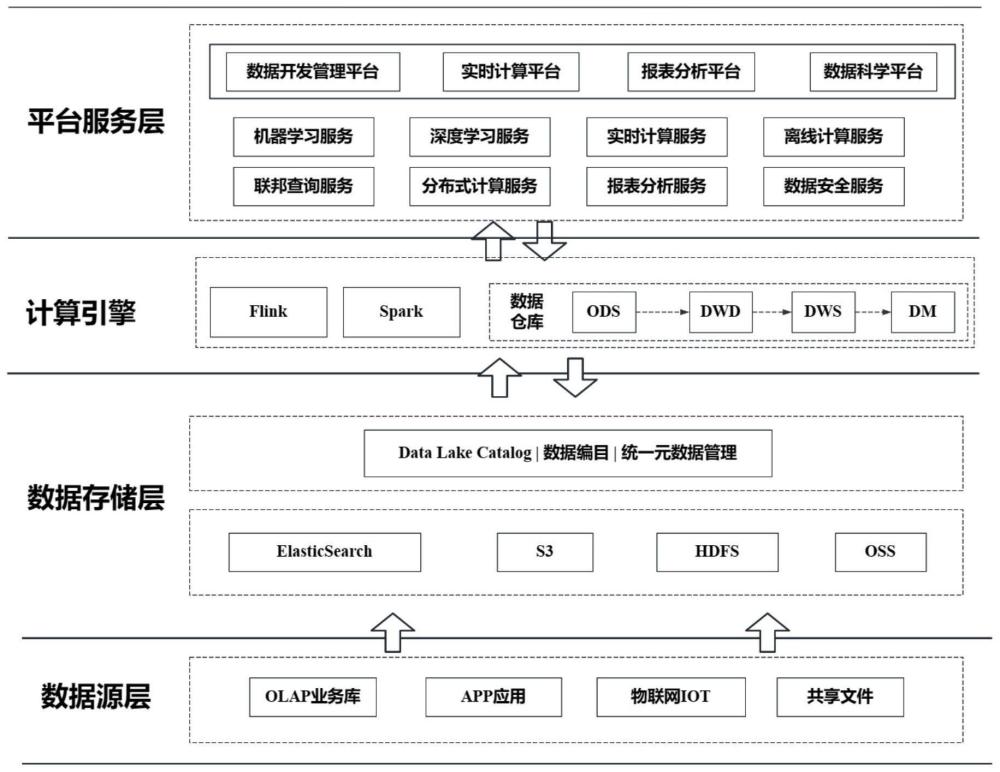
9、优选地,所述多级编目架构包括数据源层、数据存储层、计算引擎层和平台服务层。
10、优选地,所述元数据信息包括数据结构、字段定义、数据质量指标以及数据源信息。
11、优选地,所述方法还包括:
12、基于缓存技术对数据湖的原始数据进行缓存,并将原始数据根据大小切分成固定的块,存储每个块的元数据信息;
13、当从数据湖读取相同的数据时,先访问本地缓存,通过块的大小与块偏移读取数据,若未击中,再从远端拉去数据;当缓存区满时,淘汰长期未访问的区块。
14、优选地,所述当缓存区满时,淘汰长期未访问的区块,包括:
15、基于lru淘汰算法引入每个编目数据的权值,删除缓存列表中权值最小的编目数据。
16、优选地,所述方法还包括:
17、引入外部存储特性,采用计算节点与存储节点分离的方式,使用户直接从远端数据湖中查询数据。
18、优选地,所述计算节点与存储节点分离的方式,包括:
19、将热数据存储在数据仓库中,冷数据存储在数据湖中。
20、优选地,所述方法还包括:
21、临时扩展计算节点满足冷数据的计算需求。
22、第二方面,提供一种基于湖仓一体的数据编目系统,包括:
23、数据湖建设模块,用于建设数据湖,并将外部数据源中的数据提取到数据湖中;
24、数据清洗模块,用于清洗数据湖中的原始数据;
25、数据编目模块,用于为清洗后的数据添加元数据信息并采用多级编目架构进行编目;其中,所述多级编目架构中每个目录针对特定的数据领域进行配置和管理,当外部数据源更新时,通过后台线程定时刷新拉取最新的数据并更新元数据信息。
26、需要进一步说明的是,上述各选项对应的技术特征在不冲突的情况下可以相互组合或替换构成新的技术方案。
27、与现有技术相比,本发明有益效果是:
28、(1)本发明在传统的数据库设计思想中再多添加一层,通过添加元数据信息并采用多级编目架构进行编目,使得每个目录针对特定的数据领域进行配置和管理,每个目录可以专注于特定的领域的数据,以有效解决不同数据源的多样性,更好地适配了不同数据库的模式差异以及同一数据库下的模式变更,保证数据湖与数据仓库数据的一致性。
29、(2)在一个示例中,本发明考虑到数据仓库对不同数据源的数据使用频率的差异,在基础的lru淘汰算法上引入每个编目数据的权值,根据编目数据权值的变化,对缓存区中的数据进行优化更新。
30、(3)在一个示例中,本发明引入外部存储特性,采用计算节点与存储节点分离的方式,使用户直接从远端数据湖中查询数据,避免了数据复制和同步的繁琐过程,提高提供快速的数据访问和计算能力,同时节省了存储资源和维护成本。
技术特征:
1.一种基于湖仓一体的数据编目方法,其特征在于,包括:
2.根据权利要求1所述的数据编目方法,其特征在于,所述清洗数据湖中的原始数据,包括:
3.根据权利要求1所述的数据编目方法,其特征在于,所述多级编目架构包括数据源层、数据存储层、计算引擎层和平台服务层。
4.根据权利要求1所述的数据编目方法,其特征在于,所述元数据信息包括数据结构、字段定义、数据质量指标以及数据源信息。
5.根据权利要求1所述的数据编目方法,其特征在于,所述方法还包括:
6.根据权利要求5所述的数据编目方法,其特征在于,所述当缓存区满时,淘汰长期未访问的区块,包括:
7.根据权利要求1所述的数据编目方法,其特征在于,所述方法还包括:
8.根据权利要求7所述的数据编目方法,其特征在于,所述计算节点与存储节点分离的方式,包括:
9.根据权利要求7所述的数据编目方法,其特征在于,所述方法还包括:
10.一种基于湖仓一体的数据编目系统,其特征在于,包括:
技术总结
本发明公开了一种基于湖仓一体的数据编目方法及系统,属于数据管理领域,包括:建设数据湖,并将外部数据源中的数据提取到数据湖中;清洗数据湖中的原始数据;为清洗后的数据添加元数据信息并采用多级编目架构进行编目;其中,所述多级编目架构中每个目录针对特定的数据领域进行配置和管理,当外部数据源更新时,通过后台线程定时刷新拉取最新数据并更新元数据。本发明实现多源异构数据的集成、整合和编目,以提供更方便、可靠和高效的并发数据访问和分析。
技术研发人员:李晓瑜,严忆,钱星宇,尚小磊,文鹏,吴昊
受保护的技术使用者:喀什地区电子信息产业技术研究院
技术研发日:
技术公布日:2024/4/17
- 还没有人留言评论。精彩留言会获得点赞!