基于多粒度卷积特征融合的中文情感分析方法及系统与流程
本发明属于自然语言处理领域,尤其涉及基于多粒度卷积特征融合的中文情感分析方法及系统。
背景技术:
1、本部分的陈述仅仅是提供了与本发明相关的背景技术信息,不必然构成在先技术。
2、情感分析是一种计算方法,用于分析和处理文本中表达的情感、情绪、评价和态度,主要应用于社交媒体上的用户评论、反馈和建议等数据,这些数据对于商业和社会有很高的价值和意义,因此,情感分析是自然语言处理领域的一个热门研究方向,涉及数据挖掘、web挖掘、文本挖掘和信息检索等多个领域。
3、情感分析的任务可以分为监督和无监督两种类型;监督任务使用标注好的数据和机器学习算法,如支持向量机、最大熵、朴素贝叶斯等,来训练分类器或回归器;无监督任务使用情感词典、语法分析和句法模式等方法,基于规则或启发式地分析文本的情感倾向。
4、深度学习是一种强大的机器学习技术,在多个应用领域取得最优的效果,如计算机视觉、语音识别、nlp等;深度学习也被应用于情感分析,使用神经网络来自动地学习文本的情感特征,而不需要人工地设计特征或规则;其中,bilstm(双向长长短期记忆网络)是一种情感分析常用的深度学习模型,可以有效地捕捉文本序列中的长期依赖关系和上下文信息。然而,bilstm只能输出固定长度或固定维度的序列,不能输出动态变化或自适应调整的输出序列,导致无法适应不同长度或不同复杂度的输入序列,例如长篇文章、多段话、多个问题等;这些问题导致现有的中文情感分析方案对情感特征的捕捉能力不足,进而影响分析的准确性。
技术实现思路
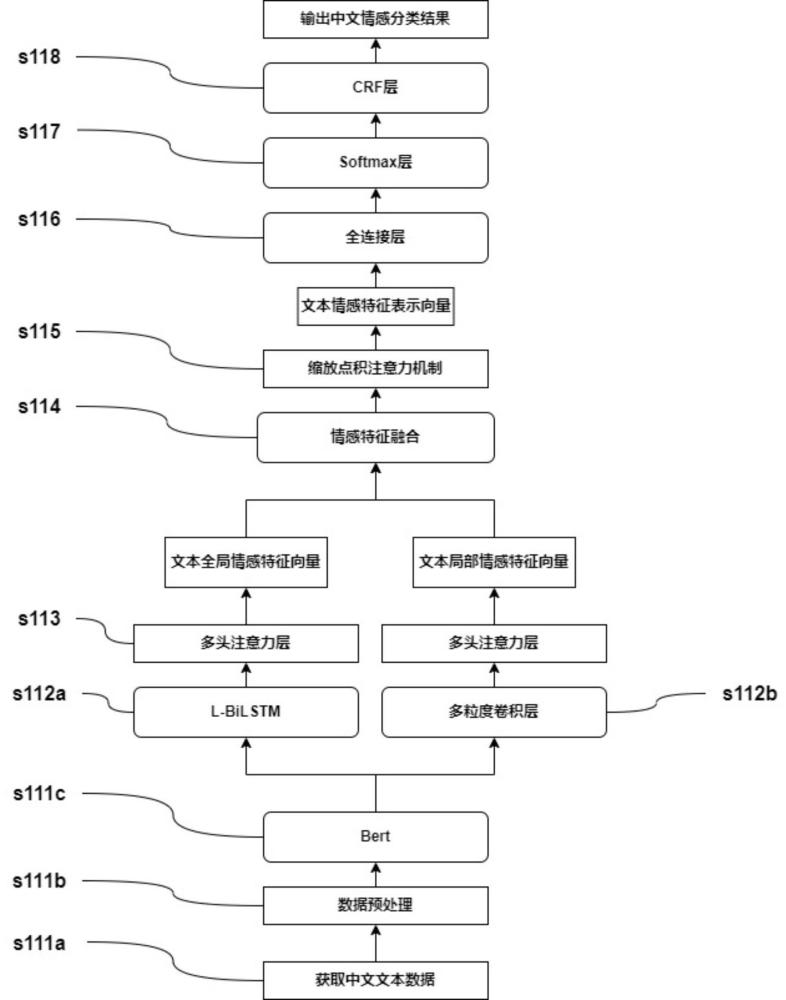
1、为克服上述现有技术的不足,本发明提供了基于多粒度卷积特征融合的中文情感分析方法及系统,在传统bilstm网络中引入长度门,动态地调整输出序列的长度,得到l-bilstm网络,综合bert模型和多粒度卷积网络,实现对文本情感特征的高效保留和高效提取,显著提高了中文情感分析的准确性。
2、为实现上述目的,本发明的一个或多个实施例提供了如下技术方案:
3、本发明第一方面提供了基于多粒度卷积特征融合的中文情感分析方法。
4、基于多粒度卷积特征融合的中文情感分析方法,包括:
5、对待分析的中文文本数据进行分词处理,得到词向量;
6、将所述词向量分别输入到多粒度卷积层和l-bilstm层,得到局部情感特征和全局情感特征;
7、所述局部情感特征和全局情感特征经过特征融合层和缩放点积自注意力层后,得到文本情感特征;
8、基于文本情感特征,通过寻找情感标签转移概率优化情感标签,得到最优的情感分类结果;
9、其中,所述l-bilstm层是在bilstm上增加长度门,用于根据输入序列的长度,动态地调整输出序列的长度,使其与输入序列的长度相匹配。
10、进一步的,所述分词处理前,进行清理异常数据的预处理。
11、进一步的,所述分词处理,是通过bert模型将中文文本数据转换为词向量。
12、进一步的,所述全局情感特征,具体提取过程为:
13、将词向量输入l-bilstm层提取文本的全局情感特征信息;
14、利用多头自注意力层,计算和分配所述全局情感特征信息的注意力权重,得到全局情感特征。
15、进一步的,所述l-bilstm层,具体处理流程为:
16、使用正向lstm计算特征正向lstm序列;
17、使用反向lstm计算特征反向lstm序列;
18、拼接特征正向lstm序列和特征反向lstm序列,得到全局情感特征信息隐层输出;
19、将所述全局情感特征信息隐层输出输入到长度门,得到全局情感特征信息。
20、进一步的,所述长度门,是根据输入序列的长度,生成一个长度向量,用于对全局情感特征信息隐层输出进行逐元素乘积,得到全局情感特征信息。
21、进一步的,所述局部情感特征,具体提取过程为:
22、将词向量输入多粒度卷积层提取文本的局部情感特征信息;
23、利用多头自注意力层,计算和分配所述局部情感特征信息的注意力权重,得到局部情感特征。
24、进一步的,所述特征融合层,是对全局情感特征和局部情感特征进行加权融合;
25、所述缩放点积自注意力层,是为融合后的情感特征计算和分配每个词的注意力权重,加强重要特征的权重,得到文本情感特征。
26、进一步的,所述情感分类结果,具体计算过程为:
27、将文本情感特征输入全连接层,对文本情感特征进行整合压缩;
28、将整合压缩后的文本情感特征输入softmax层进行分类,得到softmax输出;
29、将softmax输出输入crf层,通过寻找情感标签转移概率优化情感标签,得到最优的情感分类结果。
30、本发明第二方面提供了基于多粒度卷积特征融合的中文情感分析系统。
31、基于多粒度卷积特征融合的中文情感分析系统,包括文本分词模块、特征提取模块、特征融合模块和特征分类模块:
32、文本分词模块,被配置为:对待分析的中文文本数据进行分词处理,得到词向量;
33、特征提取模块,被配置为:将所述词向量分别输入到多粒度卷积层和l-bilstm层,得到局部情感特征和全局情感特征;
34、特征融合模块,被配置为:所述局部情感特征和全局情感特征经过特征融合层和缩放点积自注意力层后,得到文本情感特征;
35、特征分类模块,被配置为:基于文本情感特征,通过寻找情感标签转移概率优化情感标签,得到最优的情感分类结果;
36、其中,所述l-bilstm层是在bilstm上增加长度门,用于根据输入序列的长度,动态地调整输出序列的长度,使其与输入序列的长度相匹配。
37、以上一个或多个技术方案存在以下有益效果:
38、本发明对传统bilstm网络做出改进,引入“长度门”机制,根据输入序列的长度,动态地调整输出序列的长度,使其与输入序列的长度相匹配,而不是固定为一个预设的最大长度,避免输出序列中出现一些无关的或冗余的信息,提高模型中文情感分析的效率和准确性。
39、本发明附加方面的优点将在下面的描述中部分给出,部分将从下面的描述中变得明显,或通过本发明的实践了解到。
技术特征:
1.基于多粒度卷积特征融合的中文情感分析方法,其特征在于,包括:
2.如权利要求1所述的基于多粒度卷积特征融合的中文情感分析方法,其特征在于,所述分词处理前,进行清理异常数据的预处理。
3.如权利要求1所述的基于多粒度卷积特征融合的中文情感分析方法,其特征在于,所述分词处理,是通过bert模型将中文文本数据转换为词向量。
4.如权利要求1所述的基于多粒度卷积特征融合的中文情感分析方法,其特征在于,所述全局情感特征,具体提取过程为:
5.如权利要求4所述的基于多粒度卷积特征融合的中文情感分析方法,其特征在于,所述l-bilstm层,具体处理流程为:
6.如权利要求5所述的基于多粒度卷积特征融合的中文情感分析方法,其特征在于,所述长度门,是根据输入序列的长度,生成一个长度向量,用于对全局情感特征信息隐层输出进行逐元素乘积,得到全局情感特征信息。
7.如权利要求1所述的基于多粒度卷积特征融合的中文情感分析方法,其特征在于,所述局部情感特征,具体提取过程为:
8.如权利要求1所述的基于多粒度卷积特征融合的中文情感分析方法,其特征在于,所述特征融合层,是对全局情感特征和局部情感特征进行加权融合;
9.如权利要求1所述的基于多粒度卷积特征融合的中文情感分析方法,其特征在于,所述情感分类结果,具体计算过程为:
10.基于多粒度卷积特征融合的中文情感分析系统,其特征在于,包括文本分词模块、特征提取模块、特征融合模块和特征分类模块:
技术总结
本发明提出了基于多粒度卷积特征融合的中文情感分析方法及系统,涉及自然语言处理领域,具体方案包括:对待分析的中文文本数据进行分词处理,得到词向量;将所述词向量分别输入到多粒度卷积层和L‑BiLSTM层,得到局部情感特征和全局情感特征;所述局部情感特征和全局情感特征经过特征融合层和缩放点积自注意力层后,得到文本情感特征;基于文本情感特征,通过寻找情感标签转移概率优化情感标签,得到最优的情感分类结果;本发明在传统的BiLSTM网络中引入长度门,动态地调整输出序列的长度,得到L‑BiLSTM网络,综合Bert模型和多粒度卷积网络,实现对文本情感特征的高效保留和高效提取,显著提高了中文情感分析的准确性。
技术研发人员:王继彬,张鑫硕,郭莹,吴晓明
受保护的技术使用者:山东省计算中心(国家超级计算济南中心)
技术研发日:
技术公布日:2024/3/12
- 还没有人留言评论。精彩留言会获得点赞!