智能体行为策略确定方法、装置、设备和存储介质
本公开的实施例涉及信息处理以及相关,具体地,涉及适用于一种智能体行为策略确定方法、装置、设备和存储介质。
背景技术:
1、在传统的强化学习问题中,智能体通过探索环境以学习最优策略,而无需考虑安全约束问题,智能体在探索环境时,通过任意的短期损失换取更大的长期收益是可以被接受的。
2、然而,在许多现实问题中,智能体通过探索环境以学习最优策略中安全性也尤其关键,此外,尽管智能体可以先在模拟器中进行训练,但在没有足够逼真度的模拟器的情况下,仍然存在许多现实问题。因此,构建用于现实环境的安全强化学习算法非常具有挑战性。
技术实现思路
1、本文中描述的实施例提供了一种智能体行为策略确定方法、装置、设备和存储介质,解决现有技术存在的问题。
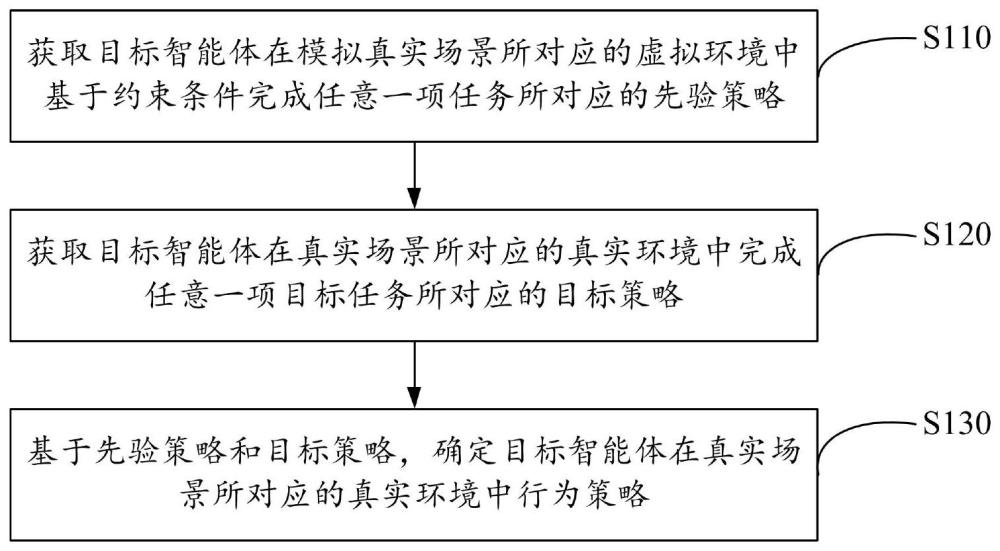
2、第一方面,根据本公开的内容,提供了一种智能体行为策略确定方法,包括:
3、获取目标智能体在模拟真实场景所对应的虚拟环境中基于约束条件完成任意一项任务所对应的先验策略;
4、获取目标智能体在真实场景所对应的真实环境中完成任意一项目标任务所对应的目标策略,其中,所述目标任务为所述任务中的任意一项;
5、基于所述先验策略和所述目标策略,确定所述目标智能体在真实场景所对应的真实环境中行为策略。
6、在本公开的一些实施例中,所述获取目标智能体在模拟真实场景所对应的虚拟环境中基于约束条件完成任意一项任务所对应的先验策略,包括:
7、构建状态转移概率函数和安全成本函数;
8、基于所述状态转移概率函数和所述安全成本函数,确定所述目标智能体完成任意一项任务所对应的执行动作;
9、基于所述目标智能体完成任意一项任务所对应的执行动作确定先验策略。
10、在本公开的一些实施例中,所述基于所述状态转移概率函数和所述安全成本函数,确定所述目标智能体完成任意一项任务所对应的执行动作,包括:
11、基于所述状态转移概率,确定所述目标智能体在完成任务时每一步所对应的状态信息;
12、基于所述安全成本函数信息和所述目标智能体在完成任务时每一步所对应的状态信息,确定所述目标智能体在完成任务时每一步所对应的安全成本信息;
13、根据所述目标智能体在完成任务时每一步所对应的安全成本信息确定执行动作。
14、在本公开的一些实施例中,所述获取目标智能体在真实场景所对应的真实环境中完成任意一项目标任务所对应的目标策略,包括:
15、获取所述真实环境与所述虚拟环境的关联关系;
16、根据所述真实环境与所述虚拟环境的关联关系,确定目标智能体在真实场景所对应的真实环境中完成任意一项目标任务所对应的目标策略。
17、在本公开的一些实施例中,所述根据所述真实环境与所述虚拟环境的关联关系,确定目标智能体在真实场景所对应的真实环境中完成任意一项目标任务所对应的目标策略之前,还包括:
18、构建奖励函数;
19、所述根据所述真实环境与所述虚拟环境的关联关系,确定目标智能体在真实场景所对应的真实环境中完成任意一项目标任务所对应的目标策略,包括:
20、根据所述真实环境与所述虚拟环境的关联关系以及奖励函数,确定所述目标智能体完成目标任务所对应的执行动作。
21、在本公开的一些实施例中,所述基于所述先验策略和所述目标策略,确定所述目标智能体在真实场景所对应的真实环境中行为策略,包括:
22、基于所述目标智能体完成目标任务的探索次数,确定所述先验策略和所述目标策略的比值信息;
23、根据所述先验策略、所述目标策略和所述先验策略和所述目标策略的比值信息,确定所述目标智能体在真实场景所对应的真实环境中行为策略。
24、在本公开的一些实施例中,所述基于所述先验策略和所述目标策略,确定所述目标智能体在真实场景所对应的真实环境中行为策略,包括:
25、基于所述先验策略,获取所述目标智能体在真实场景所对应的真实环境中完成目标任务时每一步所对应的安全成本;
26、当所述目标智能体在真实场景所对应的真实环境中完成目标任务时,某一步所对应的安全成本大于预设值时,切换所述目标智能体在真实场景所对应的真实环境中行为策略至目标策略。
27、第二方面,根据本公开的内容,提供了一种智能体行为策略确定装置,包括:
28、先验策略获取模块,用于获取目标智能体在模拟真实场景所对应的虚拟环境中基于约束条件完成任意一项任务所对应的先验策略;
29、目标策略获取模块,用于获取目标智能体在真实场景所对应的真实环境中完成任意一项目标任务所对应的目标策略,其中,所述目标任务为所述任务中的任意一项;
30、行为策略确定模块,用于基于所述先验策略和所述目标策略,确定所述目标智能体在真实场景所对应的真实环境中行为策略。
31、第三方面,根据本公开的内容,提供了一种计算机设备,包括存储器和处理器,存储器中存储有计算机程序,处理器执行计算机程序时实现如以上任意一个实施例中方法的步骤。
32、第四方面,根据本公开的内容,提供了一种计算机可读存储介质,计算机可读存储介质上存储有计算机程序,计算机程序被处理器执行时实现如以上任意一个实施例中方法的步骤。
33、本公开实施例提供的智能体行为策略确定方法、装置、设备和存储介质,首先获取目标智能体在模拟真实场景所对应的虚拟环境中基于约束条件完成任意一项任务所对应的先验策略;然后获取目标智能体在真实场景所对应的真实环境中完成任意一项目标任务所对应的目标策略;最后基于先验策略和目标策略,确定目标智能体在真实场景所对应的真实环境中行为策略。由于先验策略使智能体快速学习如何在约束满足的情况下行动,目标策略使智能体快速学习如何完成目标任务,因此基于先验策略和目标策略确定的行为策略可以在保证智能体在满足约束的情况下安全高效的完成目标任务。
34、上述说明仅是本申请实施例技术方案的概述,为了能够更清楚了解本申请实施例的技术手段,而可依照说明书的内容予以实施,并且为了让本申请实施例的上述和其它目的、特征和优点能够更明显易懂,以下特举本申请的具体实施方式。
技术特征:
1.一种智能体行为策略确定方法,其特征在于,包括:
2.根据权利要求1所述的方法,其特征在于,所述获取目标智能体在模拟真实场景所对应的虚拟环境中基于约束条件完成任意一项任务所对应的先验策略,包括:
3.根据权利要求2所述的方法,其特征在于,所述基于所述状态转移概率函数和所述安全成本函数,确定所述目标智能体完成任意一项任务所对应的执行动作,包括:
4.根据权利要求1所述的方法,其特征在于,所述获取目标智能体在真实场景所对应的真实环境中完成任意一项目标任务所对应的目标策略,包括:
5.根据权利要求4所述的方法,其特征在于,所述根据所述真实环境与所述虚拟环境的关联关系,确定目标智能体在真实场景所对应的真实环境中完成任意一项目标任务所对应的目标策略之前,还包括:
6.根据权利要求1所述的方法,其特征在于,所述基于所述先验策略和所述目标策略,确定所述目标智能体在真实场景所对应的真实环境中行为策略,包括:
7.根据权利要求1所述的方法,其特征在于,所述基于所述先验策略和所述目标策略,确定所述目标智能体在真实场景所对应的真实环境中行为策略,包括:
8.一种智能体行为策略确定装置,其特征在于,包括:
9.一种计算机设备,其特征在于,包括:
10.一种计算机可读存储介质,其上存储有计算机程序,其特征在于,该程序被处理器执行时实现如权利要求1~7中任一所述的方法。
技术总结
本公开的实施例提供的智能体行为策略确定方法、装置、设备和存储介质,包括:获取目标智能体在模拟真实场景所对应的虚拟环境中基于约束条件完成任意一项任务所对应的先验策略;获取目标智能体在真实场景所对应的真实环境中完成任意一项目标任务所对应的目标策略;基于先验策略和目标策略,确定目标智能体在真实场景所对应的真实环境中行为策略。由于先验策略使智能体快速学习如何在约束满足的情况下行动,目标策略使智能体快速学习如何完成目标任务,因此基于先验策略和目标策略确定的行为策略可以在保证智能体在满足约束的情况下安全高效的完成目标任务。
技术研发人员:杨奇松,武健,李雪瑞,常燕,李邦杰,赵久奋,朱昱,张大巧
受保护的技术使用者:中国人民解放军火箭军工程大学
技术研发日:
技术公布日:2024/4/29
- 还没有人留言评论。精彩留言会获得点赞!