提升集群可用性的方法、机器可读存储介质及计算机设备与流程
本发明涉及数据库,特别是涉及一种提升集群可用性的方法、机器可读存储介质及计算机设备。
背景技术:
1、在使用数据库读写分离集群时,客户端通常要设置一个监测线程来检测集群的状态,以确定集群的可用性。其实现通常为:在建立连接前,首先会自动建立一个全局唯一的监测线程用来定时监测集群状态,并定时更新在线的主、备机信息。其它连接可以据此提前判断连接是否可用,避免使用已经失效的连接造成网络等待。具体的实现方式主要有以下两个方面:
2、第一,在建立连接前通过判断主、备机是否在线来决定是否建立连接,避免因机器不在线造成失败连接的等待时间;第二,在与服务器通信过程中,等待服务器返回消息时,通过判断当前连接是否在线,来决定等待服务器信息返回还是直接返回错误信息,避免无限等待。
3、监测线程通常会设置一个端口超时时间,来保证如果遇到拔网线等场景时,监测线程可以在端口超时时间内监测到异常。在网络不稳定的情况下,监测线程的结构化查询语言(structured query language,简称sql)返回经常性会遇到套接字超时异常,导致监测线程清空在线主备机信息,应用线程检测到对应情况,就会停止等待。因此,在网络不稳定状态下,会出现监测线程频繁清空在线节点信息,导致应用线程退出,应用频繁收到异常信息的情况。
4、但是sql并非一直返回慢,而是偶发性的,有时候延长等待时间,可以得到正确的返回结果。为了解决这个问题,一种方法是可以增加监测线程端口超时的超时时间。但是这种方法的缺点是网络不稳定状态下,无法确认网络的最大延时,从而没有办法确定端口超时时间的合适的设置值。
技术实现思路
1、本发明的一个目的是要提供一种能够解决上述任一问题的提升集群可用性的方法、机器可读存储介质及计算机设备。
2、本发明一个进一步的目的是在监测线程遇到套接字超时异常以外的异常原因时及时通知应用线程停止等待,避免出现无限等待的情况。
3、本发明一个进一步的目的是在监测线程遇到套接字超时异常时延长监测线程的监测时间,从而延长应用线程的等待时间,避免监测线程频繁清空在线节点信息,导致应用线程退出、客户端频繁收到异常信息。
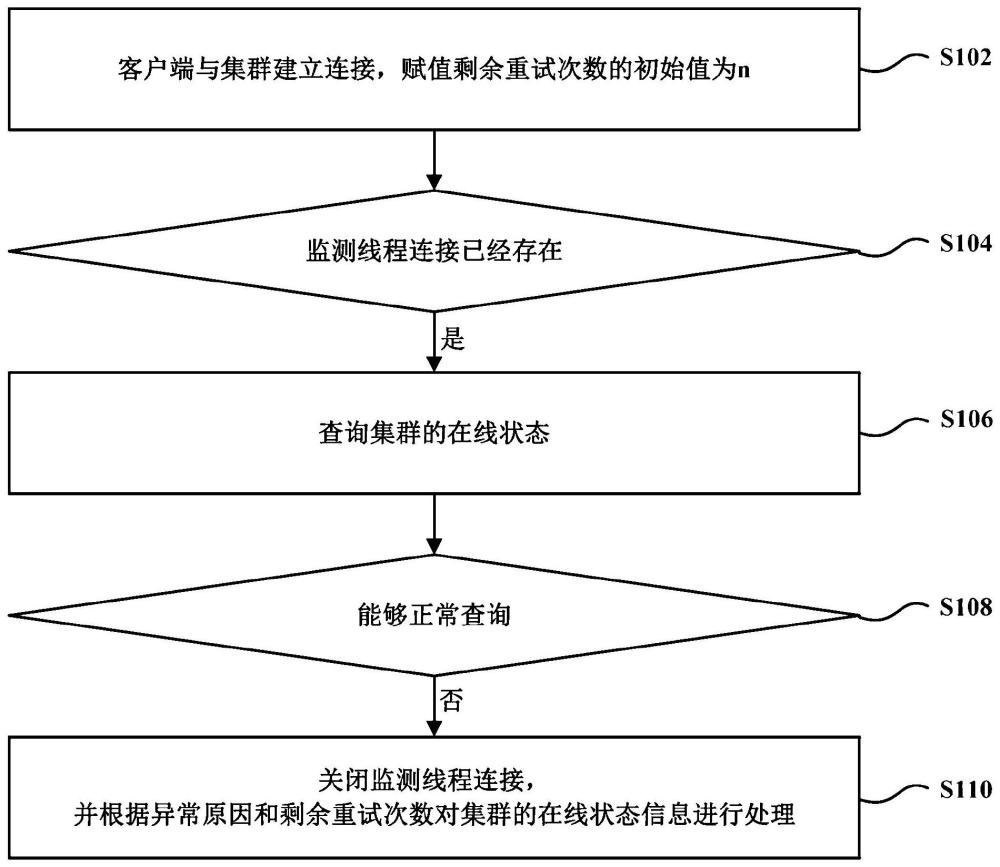
4、特别地,本发明提供了一种提升集群可用性的方法,包括:
5、客户端与集群建立连接,赋值剩余重试次数的初始值为n;
6、判断监测线程连接是否已经存在;
7、若是,查询集群的在线状态;
8、判断是否能够正常查询;以及
9、若否,关闭监测线程连接,并根据异常原因和剩余重试次数对集群的在线状态信息进行处理,其中异常原因包括套接字超时异常以及其他异常。
10、可选地,根据异常原因和剩余重试次数对集群的在线状态信息进行处理的步骤包括:
11、判断异常原因是否为套接字超时异常;以及
12、若否,清空集群的在线状态信息。
13、可选地,在异常原因为套接字超时异常的情况下,判断剩余重试次数是否为0;以及
14、若是,执行清空集群的在线状态信息的步骤。
15、可选地,在异常原因为套接字超时异常且剩余重试次数不为0的情况下,将剩余重试次数减去1;以及
16、等待间隔时间后执行判断监测线程连接是否已经存在的步骤。
17、可选地,在监测线程连接不存在的情况下,判断剩余重试次数是否为n;以及
18、若否,新建监测线程连接。
19、可选地,在监测线程连接不存在且剩余重试次数为n的情况下,更新连接版本,并执行新建监测线程连接的步骤。
20、可选地,在新建监测线程连接的步骤之后还包括:
21、判断连接是否成功;以及
22、若否,执行判断异常原因是否为套接字超时异常的步骤,
23、若是,执行查询集群的在线状态的步骤。
24、可选地,在监测线程连接已经存在且集群的在线状态能够正常查询的情况下,更新集群的在线状态信息;并且
25、在清空或更新集群的在线状态信息的步骤之后还包括:赋值剩余重试次数的初始值为n并执行等待间隔时间的步骤。
26、根据本发明的另一个方面,还提供了一种机器可读存储介质,其上存储有机器可执行程序,机器可执行程序被处理器执行时实现上述任一项的提升集群可用性的方法。
27、根据本发明的又一个方面,还提供了一种计算机设备,包括存储器、处理器及存储在存储器上并在处理器上运行的机器可执行程序,并且处理器执行机器可执行程序时实现上述任一项的提升集群可用性的方法。
28、本发明的提升集群可用性的方法,通过客户端与集群建立连接,赋值剩余重试次数的初始值为n,判断监测线程连接是否已经存在,在判断结果为是的情况下,查询集群的在线状态,判断是否能够正常查询,在判断结果为否的情况下,关闭监测线程连接,并根据异常原因和剩余重试次数对集群的在线状态信息进行处理,其中异常原因包括套接字超时异常以及其他异常,也就是说,通过执行检测数据库状态的sql,在不能够正常执行的情况下,根据异常原因和剩余重试次数对集群的在线状态信息进行清空或者增加监测线程的重试次数,既能够在集群异常等场景下,及时通知应用线程停止等待,避免出现无限等待的情况,又可以在网络不稳定等场景下,通过延长等待时间,避免应用频繁收到异常信息。
29、进一步地,本发明的提升集群可用性的方法,在异常原因为套接字超时异常且剩余重试次数不为0的情况下,将剩余重试次数减去1,等待间隔时间后执行判断监测线程连接是否已经存在的步骤,能够增加监测线程的重试次数,监测线程重试期间不清空集群的在线状态信息,重建连接时不更新连接版本,直到达到最大重试次数后依旧失败,再清空集群的在线状态信息,应用线程停止等待,进入异常处理流程,能够通过增加监测线程的重试次数延长监测线程的监测时间,从而延长应用线程的等待时间,避免在网络不稳定的状态下监测线程频繁清空在线节点信息,导致应用线程退出、客户端频繁收到异常信息的情况发生。
30、根据下文结合附图对本发明具体实施例的详细描述,本领域技术人员将会更加明了本发明的上述以及其他目的、优点和特征。
技术特征:
1.一种提升集群可用性的方法,包括:
2.根据权利要求1的提升集群可用性的方法,其中根据异常原因和所述剩余重试次数对所述集群的在线状态信息进行处理的步骤包括:
3.根据权利要求2的提升集群可用性的方法,其中,
4.根据权利要求3的提升集群可用性的方法,其中,
5.根据权利要求4的提升集群可用性的方法,其中,
6.根据权利要求5的提升集群可用性的方法,其中,
7.根据权利要求6的提升集群可用性的方法,其中在新建所述监测线程连接的步骤之后还包括:
8.根据权利要求4的提升集群可用性的方法,其中,
9.一种机器可读存储介质,其上存储有机器可执行程序,机器可执行程序被处理器执行时实现根据权利要求1至8任一项的提升集群可用性的方法。
10.一种计算机设备,包括存储器、处理器及存储在存储器上并在处理器上运行的机器可执行程序,并且处理器执行机器可执行程序时实现根据权利要求1至8任一项的提升集群可用性的方法。
技术总结
本发明提供了一种提升集群可用性的方法、机器可读存储介质及计算机设备。其中,提升集群可用性的方法包括:客户端与集群建立连接,赋值剩余重试次数的初始值为n;判断监测线程连接是否已经存在;若是,查询集群的在线状态;判断是否能够正常查询;以及若否,关闭监测线程连接,并根据异常原因和剩余重试次数对集群的在线状态信息进行处理,通过执行检测数据库状态的SQL,在不能够正常执行的情况下,根据异常原因和剩余重试次数对集群的在线状态信息进行清空或者增加监测线程的重试次数,既能够在集群异常等场景下,及时通知应用线程停止等待,避免出现无限等待的情况,又可以在网络不稳定等场景下,通过延长等待时间,避免应用频繁收到异常信息。
技术研发人员:韩慧敏,毛宇,李楠
受保护的技术使用者:北京人大金仓信息技术股份有限公司
技术研发日:
技术公布日:2024/5/16
- 还没有人留言评论。精彩留言会获得点赞!