基于关系先验偏置的文档关系抽取方法
本发明涉及深度学习和自然语言处理领域,尤其涉及一种基于关系先验偏置的文档关系抽取方法。
背景技术:
1、文档关系抽取任务是指从给定的文档中,自动识别和提取出文本中存在的实体之间的关系。该任务通常要求模型能够对多种关系类型进行分类,例如“疾病与疾病之间的并发关系”、“疾病与症状之间的表现关系”、“药品与食物之间的辅助关系”等等。文档关系抽取是自然语言处理中的重要任务,可以广泛应用于信息提取、知识图谱构建、问答系统等领域。
2、文档关系抽取中存在着丰富的先验知识,这些知识可以通过实体类型和关系类型之间的统计关联来建模。将这种统计先验知识注入关系抽取模型具有多重价值。首先,它可以为模型提供先验信息,从而降低模型在处理关系时犯下常识性错误的概率,通过利用大规模语料库中的统计数据,模型可以学习到不同实体类型之间的常见关系类型分布,以及关系类型的频率,能够更好地适应数据中的相关分布规律。这样的先验知识可以指导模型更加准确地预测和抽取文档中的关系。其次,利用统计先验知识可以提高关系抽取模型的性能和鲁棒性。通过利用先验知识,模型能够更好地适应不同领域和语境中的关系抽取任务。它可以帮助模型更好地理解文档中的关系,从而提高模型在复杂场景下的表现。此外,统计先验知识还可以帮助模型更准确地预测罕见或少见的关系类型,增强模型的泛化能力。
3、因此,研究如何将统计先验知识注入关系抽取模型是一条非常有前景的技术路径。通过结合深度学习和基于关系先验偏置建模的方法,可以构建更强大和智能的关系抽取模型,为实际应用中的文本分析、知识图谱构建等任务提供更准确和可靠的解决方案。
技术实现思路
1、本发明旨在至少解决现有技术中存在的技术问题之一。为此,本发明公开了基于关系先验偏置的文档关系抽取方法。所述方法创新性地根据头尾实体的类型计算出实体对的关系先验偏置,并将关系先验偏置作为先验知识引入深度学习模型中,实现了高精度的文档关系抽取。
2、本发明的目的是通过如下技术方案实现的,基于关系先验偏置的文档关系抽取方法,所述方法包括:
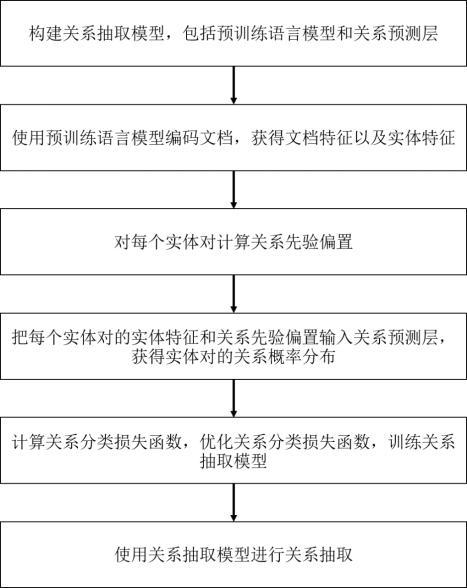
3、步骤1,构建关系抽取模型,包括预训练语言模型和关系预测层;
4、步骤2,使用预训练语言模型编码文档,获得文档特征以及实体特征;
5、步骤3,对每个实体对计算关系先验偏置;
6、步骤4,把每个实体对的实体特征和关系先验偏置输入关系预测层,获得实体对的关系概率分布;
7、步骤5,计算关系分类损失函数,优化关系分类损失函数,训练关系抽取模型;
8、步骤6,使用关系抽取模型进行关系抽取。
9、所述的对每个实体对计算关系先验偏置,具体做法如下:
10、步骤301,统计第i个实体和第j个实体组成的实体对的关系频次向量,表达式为:
11、
12、其中,表示第i个实体和第j个实体组成的实体对的关系频次向量,表示的第k个元素,c为数据集预定义的关系数量,表示训练集头实体类型同第i个实体的类型,尾实体类型同第j个实体的类型,关系为第k类关系的三元组数量;
13、步骤302,把第i个实体和第j个实体组成的实体对的关系频次向量归一化,得到第i个实体和第j个实体组成的实体对的关系先验偏置,表达式为:
14、
15、其中,表示第i个实体和第j个实体组成的实体对的关系先验偏置,表示的第k个元素,c为数据集预定义的关系数量;
16、对所有实体对都计算关系先验偏置。
17、所述的使用预训练语言模型编码文档,获得文档特征以及实体特征,包括以下步骤:
18、步骤201,将文档进行分词,并使用预训练的词嵌入模型对每个词进行编码,获得词的向量表示;文档为,词序列为,预训练的词嵌入模型为,表达式为:
19、
20、其中,是词嵌入序列,是词嵌入的维度,是文档中词汇的数量;
21、步骤202,将词嵌入序列输入到预训练语言模型roberta中进行编码,获得文档特征,roberta的编码函数表示为,表达式为:
22、
23、其中,是文档特征,是roberta的隐藏层维度,roberta 的隐藏层维度与词嵌入的维度相等,表示第i个词的特征,至此,获得文档特征和文档中每个词的特征;
24、步骤203,计算实体特征;第个实体在文档中有个指称,其中第个指称是长度为的词序列为,词的特征表示为;
25、对于第个实体的第个指称,将其对应的词特征进行聚合,得到该指称的特征,表达式为:
26、
27、将第个实体的所有指称的特征取平均,得到第个实体的特征,表达式为:
28、
29、其中,为第个实体的特征;
30、所有实体特征的表达式为:
31、
32、其中,表示所有的实体特征,u表示实体数量。
33、所述的把每个实体对的实体特征和关系先验偏置输入关系预测层,获得实体对的关系概率分布,包括以下步骤:
34、把第i个实体和第j个实体的特征和关系先验偏置输入关系预测层,得到第i个实体和第j个实体的关系概率分布,表达式为:
35、
36、其中,表示第i个实体和第j个实体的关系概率分布,、、和是可学习参数,是激活函数,表示第i个实体的实体特征,表示第j个实体的实体特征,表示第i个实体和第j个实体组成的实体对的关系先验偏置;
37、把所有实体对的实体特征和关系先验偏置输入关系预测层,计算所有实体对的关系概率分布。
38、所述的计算关系分类损失函数,优化关系分类损失函数,训练关系抽取模型,具体做法如下:
39、计算关系分类损失函数:
40、
41、其中,是关系分类损失函数,是实体的数量,c表示数据集预定义的关系类别数,是第i个实体和第j个实体是否具有第类关系的标签,是所述的第i个实体和第j个实体的关系概率分布的第k个元素;
42、使用优化算法对关系分类损失函数进行优化,训练关系抽取模型。
43、与现有方法相比,本发明方法的优点在于:本技术提供了基于关系先验偏置的文档关系抽取方法。对于文档关系抽取,其天然存在着很强的统计先验知识,本发明创新性地根据头尾实体的类型计算出实体对的关系先验偏置,并将关系先验偏置作为先验知识引入深度学习模型中,实现了高精度的文档关系抽取。
技术特征:
1.基于关系先验偏置的文档关系抽取方法,其特征在于,所述方法包括:
2.根据权利要求1所述的基于关系先验偏置的文档关系抽取方法,其特征在于,所述的对每个实体对计算关系先验偏置,包括以下步骤:
3.根据权利要求1所述的基于关系先验偏置的文档关系抽取方法,其特征在于,所述的使用预训练语言模型编码文档,获得文档特征以及实体特征,包括以下步骤:
4.根据权利要求2和3任一所述的基于关系先验偏置的文档关系抽取方法,其特征在于,所述的把每个实体对的实体特征和关系先验偏置输入关系预测层,获得实体对的关系概率分布,包括以下步骤:
5.根据权利要求4所述的基于关系先验偏置的文档关系抽取方法,其特征在于,所述的计算关系分类损失函数,优化关系分类损失函数,训练关系抽取模型,具体做法如下:
6.根据权利要求1所述的基于关系先验偏置的文档关系抽取方法,其特征在于,所述的预训练语言模型采用roberta-large模型。
技术总结
本发明公开了基于关系先验偏置的文档关系抽取方法,所述方法包括:构建关系抽取模型,包括预训练语言模型和关系预测层;使用预训练语言模型编码文档,获得文档特征以及实体特征;对每个实体对计算关系先验偏置;把每个实体对的实体特征和关系先验偏置输入关系预测层,获得实体对的关系概率分布;计算关系分类损失函数,优化关系分类损失函数,训练关系抽取模型;使用关系抽取模型进行关系抽取。本发明发现对于文档关系抽取,其天然存在着很强的统计先验知识,本发明创新性地根据头尾实体的类型计算出实体对的关系先验偏置,并将关系先验偏置作为先验知识引入深度学习模型中,实现了高精度的文档关系抽取。
技术研发人员:黄森,黄双萍
受保护的技术使用者:华南理工大学
技术研发日:
技术公布日:2024/4/17
- 还没有人留言评论。精彩留言会获得点赞!