一种中文语法纠错方法及系统与流程
本申请涉及中文语法纠错,尤其是一种中文语法纠错方法及系统。
背景技术:
1、中文语法纠错的方法主要有两种方案,一种是基于机器翻译模式的seq2seq方式,一种是基于编辑标签预测的seq2edit方式。基于机器翻译的seq2seq架构,因为其是自回归语言模型,存在着推理速度慢,需要大量的训练数据的问题,其次它的可解释性差,无法判别句子的具体语法错误类型,在速度性能上无法满足实际生产环境的需要。目前seq2edit架构也存在很多的问题,一是bert预训练语言模型由遮蔽语言建模(mlm,masked languagemodeling)和上下文匹配(nsp,next sentence predict)两个任务预训练而成,缺乏单词插入和删除相关的预训练任务,而语法纠错任务存在很多冗余和缺失的错误;二是对编辑标签的要求高,编辑标签的预测空间太大。
技术实现思路
1、本申请的目的是提供一种中文语法纠错方法及系统,旨在提升中文语法纠错的准确性。
2、本申请实施例提供一种中文语法纠错方法,该方法包括:
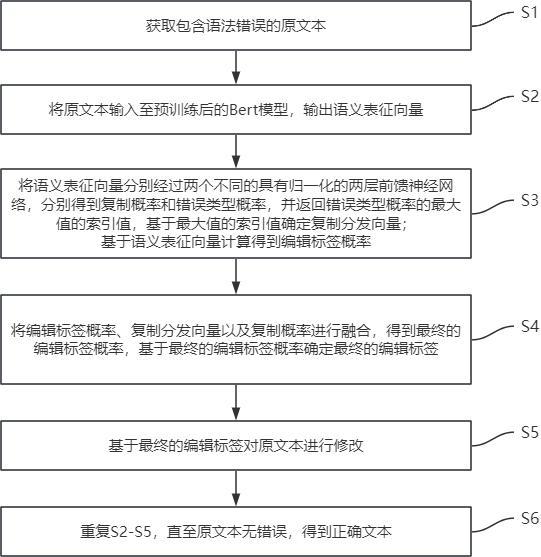
3、s1:获取包含语法错误的原文本;
4、s2:将所述原文本输入至预训练后的bert模型,输出语义表征向量;
5、s3:将所述语义表征向量分别经过两个不同的具有归一化的两层前馈神经网络,分别得到复制概率和错误类型概率,并返回错误类型概率的最大值的索引值,基于所述最大值的索引值确定复制分发向量;
6、基于所述语义表征向量计算得到编辑标签概率;
7、s4:将所述编辑标签概率、所述复制分发向量以及所述复制概率进行融合,得到最终的编辑标签概率,基于所述最终的编辑标签概率确定最终的编辑标签;
8、s5:基于所述最终的编辑标签对所述原文本进行修改;
9、s6:重复s2-s5,直至所述原文本无错误,得到正确文本。
10、本申请实施例还提供了一种中文语法纠错系统,该系统包括:
11、获取模块,用于获取包含语法错误的原文本;
12、表征模块,用于将所述原文本输入至预训练后的bert模型,输出语义表征向量;
13、复制模块,用于将所述语义表征向量分别经过两个不同的具有归一化的两层前馈神经网络,分别得到复制概率和错误类型概率,并返回错误类型概率的最大值的索引值,基于所述最大值的索引值确定复制分发向量;
14、编辑标签概率计算模块,用于基于所述语义表征向量计算得到编辑标签概率;
15、编辑标签预测模块,用于将所述编辑标签概率、所述复制分发向量以及所述复制概率进行融合,得到最终的编辑标签概率,基于所述最终的编辑标签概率确定最终的编辑标签;
16、修改模块,用于基于所述最终的编辑标签对所述原文本进行修改;
17、迭代模块,用于以依次运行一次所述表征模块、所述复制模块、所述编辑标签概率计算模块、所述编辑标签预测模块、所述修改模块为一个周期,循环周期,直至所述原文本无错误,得到正确文本。
18、本申请的有益效果:通过将原文本输入至预训练后的bert模型,输出语义表征向量;基于语义表征向量分别得到复制概率和错误类型概率,并返回错误类型概率的最大值的索引值,基于最大值的索引值确定复制分发向量;再基于语义表征向量计算得到编辑标签概率;融合编辑标签概率、复制分发向量以及复制概率,得到最终的编辑标签概率,而后基于最终的编辑标签概率确定最终的编辑标签;根据最终的编辑标签对原文本进行修改;循环执行,直至原文本没有错误,得到正确文本;提高了预训练模型bert模型在语法纠错任务中的适配度,也解决了下游语法纠错任务标签稀疏的问题,提高了整体性能,提升了中文语法纠错的准确性。
技术特征:
1.一种中文语法纠错方法,其特征在于,包括:
2.根据权利要求1所述的中文语法纠错方法,其特征在于,s2中,bert模型的预训练过程包括:
3.根据权利要求2所述的中文语法纠错方法,其特征在于,s2.1中,所述对所述无错误的文本进行替换操作和插入操作得到损失文本包括:
4.根据权利要求1所述的中文语法纠错方法,其特征在于,s3中,得到复制概率和错误类型概率的计算公式为:
5.根据权利要求4所述的中文语法纠错方法,其特征在于,s3中,所述返回错误类型概率的最大值的索引值,基于所述最大值的索引值确定复制分发向量包括:
6.根据权利要求1所述的中文语法纠错方法,其特征在于,s3中,所述基于所述语义表征向量计算得到编辑标签概率包括:
7.根据权利要求1所述的中文语法纠错方法,其特征在于,s4中,最终的编辑标签概率的计算公式为:
8.根据权利要求1所述的中文语法纠错方法,其特征在于,s4中,所述基于所述最终的编辑标签概率确定最终的编辑标签包括通过argmax函数返回最终的编辑标签概率的最大值的索引,得到最终的编辑标签。
9.根据权利要求1所述的中文语法纠错方法,其特征在于,编辑标签包括保持、删除、替换、插入。
10.一种中文语法纠错系统,其特征在于,包括:
技术总结
本申请涉及一种中文语法纠错方法及系统,方法包括:获取包含语法错误的原文本;将原文本输入至预训练后的Bert模型,输出语义表征向量;将语义表征向量分别经过两个不同的具有归一化的两层前馈神经网络,分别得到复制概率和错误类型概率,并返回错误类型概率的最大值的索引值,基于最大值的索引值确定复制分发向量;基于语义表征向量计算得到编辑标签概率;将编辑标签概率、复制分发向量以及复制概率进行融合,得到最终的编辑标签概率,基于最终的编辑标签概率确定最终的编辑标签;基于最终的编辑标签对原文本进行修改;直至原文本无错误,得到正确文本。
技术研发人员:康占英,黄惟,王青,肖峰,徐伯辰,刘优,彭卓,汤达夫,李芳芳
受保护的技术使用者:长沙市智为信息技术有限公司
技术研发日:
技术公布日:2024/4/17
- 还没有人留言评论。精彩留言会获得点赞!