基于知识蒸馏的面部表情识别方法、系统、设备及介质
本发明属于图像处理,尤其涉及基于知识蒸馏的面部表情识别方法、系统、设备及介质。
背景技术:
1、本部分的陈述仅仅是提供了与本发明相关的背景技术信息,不必然构成在先技术。
2、目前面部表情识别方法因深度学习的兴起已取得较大进展,但目前基于深度学习的面部表情识别方法存在只关注视觉表示,将类别名称转换为矢量标签以简化训练过程,从而忽略了类别名称的语义信息的问题,导致学习到的特征对训练数据类别的依赖性高、泛化性差。语言-视觉对比学习模型的出现给学习泛化性能更强的通用视觉表示带来了希望。这类模型在亿级甚至十亿级别的语言图像对上进行训练,以对比学习的方式提升了语言编码器和视觉编码器,使二者更具泛化能力。
3、然而,由于语言-视觉对比学习模型参数规模较大、模型要求对目标数据集进行标记,这限制了模型对数据集的理解,降低了模型用于面部表情识别的实用性。
技术实现思路
1、为克服上述现有技术的不足,本发明提供了一种基于知识蒸馏的面部表情识别方法、系统、设备及介质,基于无监督学习的方式,通过第一语言-视觉对比学习模型生成伪标签,解决语言-视觉对比学习模型的标签限制问题;将训练好的教师模型中适用于面部表情识别的能力迁移至学生模型,不仅使得到的学生模型具备了语言和视觉表示之间的一致性的能力,还降低了模型的参数规模。
2、为实现上述目的,本发明的第一个方面提供一种基于知识蒸馏的面部表情识别方法,包括:
3、获取待识别的面部图像;
4、通过训练好的学生模型,识别得到所述待识别的面部图像对应的面部表情类别;
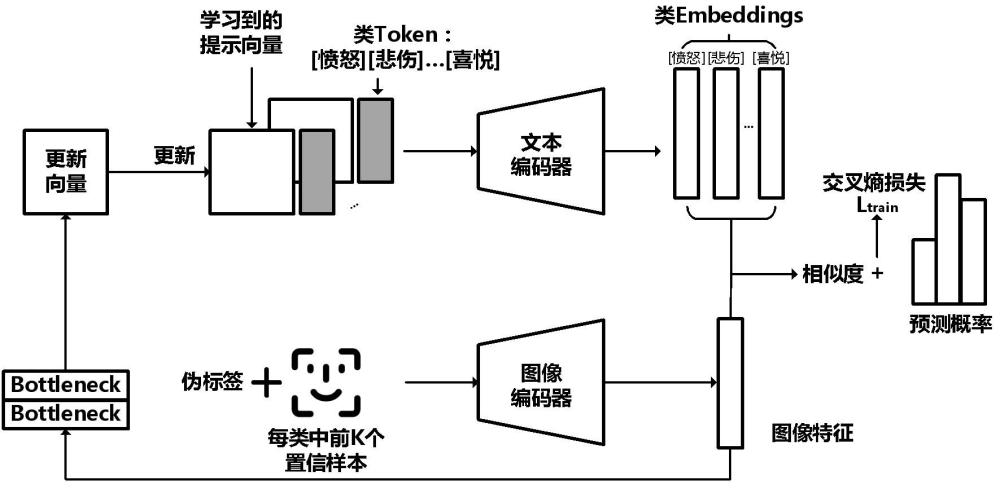
5、其中,所述学生模型通过训练好的教师模型知识蒸馏训练得到,所述教师模型包括第一语言-视觉对比学习模型和第二语言-视觉对比学习模型,在所述教师模型训练过程中,基于无监督学习的方式,通过第一语言-视觉对比学习模型生成伪标签,将所生成的伪标签以及对应的训练样本图像输入到第二语言-视觉对比学习模型的图像编码器中,以最小化第一交叉熵损失为目标,训练得到学习好的提示向量;将学习好的提示向量输入到第二语言-视觉对比学习模型的文本编辑器中,以最小化第二交叉熵损失为目标进行训练。
6、本发明的第二个方面提供一种基于知识蒸馏的面部表情识别系统,包括:
7、获取模块:获取待识别的面部图像;
8、识别模块:通过训练好的学生模型,识别得到所述待识别的面部图像对应的面部表情类别;
9、其中,所述学生模型通过训练好的教师模型知识蒸馏训练得到,所述教师模型包括第一语言-视觉对比学习模型和第二语言-视觉对比学习模型,在所述教师模型训练过程中,基于无监督学习的方式,通过第一语言-视觉对比学习模型生成伪标签,将所生成的伪标签以及对应的训练样本图像输入到第二语言-视觉对比学习模型的图像编码器中,以最小化第一交叉熵损失为目标,训练得到学习好的提示向量;将学习好的提示向量输入到第二语言-视觉对比学习模型的文本编辑器中,以最小化第二交叉熵损失为目标进行训练。
10、本发明的第三个方面提供一种计算机设备,包括:处理器、存储器和总线,所述存储器存储有所述处理器可执行的机器可读指令,当计算机设备运行时,所述处理器与所述存储器之间通过总线通信,所述机器可读指令被所述处理器执行时执行一种基于知识蒸馏的面部表情识别方法。
11、本发明的第四个方面提供一种计算机可读存储介质,所述计算机可读存储介质上存储有计算机程序,所述计算机程序被处理器运行时执行一种基于知识蒸馏的面部表情识别方法。
12、以上一个或多个技术方案存在以下有益效果:
13、在本发明中,基于无监督学习的方式,通过第一语言-视觉对比学习模型生成伪标签,解决语言-视觉对比学习模型的标签限制问题;通过生成的伪标签以及对应的训练样本图像对第二语言-视觉对比学习模型的图像编码器进行训练,将学习得到的提示向量用于第二语言-视觉对比学习模型的文本编辑器的训练,将训练好的教师模型中适用于面部表情识别的能力迁移至学生模型,不仅使得到的学生模型具备了语言和视觉表示之间的一致性的能力,还降低了模型的参数规模,为提高应用服务的性能提供了条件。
14、本发明附加方面的优点将在下面的描述中部分给出,部分将从下面的描述中变得明显,或通过本发明的实践了解到。
技术特征:
1.一种基于知识蒸馏的面部表情识别方法,其特征在于,包括:
2.如权利要求1所述的一种基于知识蒸馏的面部表情识别方法,其特征在于,还包括对获取的待识别的面部图像进行预处理,所述预处理包括:采用关键点对齐网络提取面部区域,将所提取的面部区域进行矫正,将矫正后的面部区域采用双线性插值法进行放缩处理。
3.如权利要求1所述的一种基于知识蒸馏的面部表情识别方法,其特征在于,将所生成的伪标签以及对应的训练样本图像输入到第二语言-视觉对比学习模型的图像编码器中,以最小化第一交叉熵损失为目标,得到学习的提示向量,具体为:将所生成的伪标签以及对应的训练样本图像输入到第二语言-视觉对比学习模型的图像编码器中,提取图像特征,将所提取的图像特征输入到bottleneck网络中,通过激活函数对学习的提示向量进行更新,直至获得最小的第一交叉熵损失,得到学习好的提示向量。
4.如权利要求1所述的一种基于知识蒸馏的面部表情识别方法,其特征在于,将训练样本图像输入到学生模型中,得到与所述教师模型相同维度的图像特征,以最小化所述学生模型与所述教师模型所提取的图像特征的特征损失为目标,对所学生模型进行训练。
5.如权利要求1所述的一种基于知识蒸馏的面部表情识别方法,其特征在于,将训练好的学生模型所输出的图像特征输入至分类器中,以最小化软标签和硬标签的k-l散度损失为目标,对所述分类器进行训练。
6.如权利要求1所述的一种基于知识蒸馏的面部表情识别方法,其特征在于,所述学生模型和所述教师模型的网络结构不同。
7.如权利要求3所述的一种基于知识蒸馏的面部表情识别方法,其特征在于,将所生成的伪标签中每一类别的前n个置信样本以及对应的伪标签输入到第二语言-视觉对比学习模型的图像编码器中进行图像特征提取;其中,n为整数。
8.一种基于知识蒸馏的面部表情识别系统,其特征在于,包括:
9.一种计算机设备,其特征在于,包括:处理器、存储器和总线,所述存储器存储有所述处理器可执行的机器可读指令,当计算机设备运行时,所述处理器与所述存储器之间通过总线通信,所述机器可读指令被所述处理器执行时执行如权利要求1至7任一项所述的一种基于知识蒸馏的面部表情识别方法。
10.一种计算机可读存储介质,其特征在于,所述计算机可读存储介质上存储有计算机程序,所述计算机程序被处理器运行时执行如权利要求1至7任一项所述的一种基于知识蒸馏的面部表情识别方法。
技术总结
本发明属于图像处理技术领域,为了解决现有模型参数规模较大、模型要求对目标数据集进行标记,限制了对数据集的理解的问题,提出了基于知识蒸馏的面部表情识别方法、系统、设备及介质,通过第一语言‑视觉对比学习模型生成伪标签,解决语言‑视觉对比学习模型的标签限制问题;通过生成的伪标签以及对应的训练样本图像对第二语言‑视觉对比学习模型的图像编码器进行训练,将学习得到的提示向量用于第二语言‑视觉对比学习模型的文本编辑器的训练,将训练好的教师模型中适用于面部表情识别的能力迁移至学生模型,使学生模型具备了语言和视觉表示之间的一致性的能力,降低了模型的参数规模。
技术研发人员:赵显,刘治,吴静林,陈丹阳,任朝霞
受保护的技术使用者:山东大学
技术研发日:
技术公布日:2024/4/29
- 还没有人留言评论。精彩留言会获得点赞!