一种基于高斯点渲染的单目人脸化身生成方法
本发明涉及图像处理和模式识别,尤其是一种基于高斯点渲染的单目人脸化身生成方法。
背景技术:
1、单目人像化身生成旨在生成特定人物面部化身以表演特定动作和表情,其在人机交互、虚拟现实和增强现实等领域具有广泛应用。现有方法大多采用隐式网络来解决该问题,但该类型网络训练时间长,渲染时间长,生成结果几何结果差。近年来,点渲染的出现为该领域注入了新的活力,点渲染通过将点渲染到二维图像上与真值做损失,得到高精度的渲染人像。特别是近期出现的高斯抛雪球渲染,它具有比点渲染更快的渲染速度,同时兼具渲染质量。但现有高斯抛雪球渲染只能做到静态场景,无法根据用户的需求生成动态序列。此外,现有的基于高斯抛雪球渲染的方法是迭代优化的,无法根据用户的需求生成特定人脸化身,并使其根据输入的驱动信号生成动作序列。
技术实现思路
1、本发明的目的是提供一种基于高斯点渲染的单目人脸化身生成方法,利用高斯抛雪球渲染的高保真图像渲染能力,生成基于flame参数驱动的人脸化身,并利用高斯形变场和高斯参数预测网络,通过预训练好的线性混合蒙皮函数建立点的偏移与flame参数的关系,以提高人脸化身的渲染质量、几何质量以及驱动质量。
2、为实现上述目的,本发明采用下述技术方案:
3、一种基于高斯点渲染的单目人脸化身生成方法,包括以下步骤:
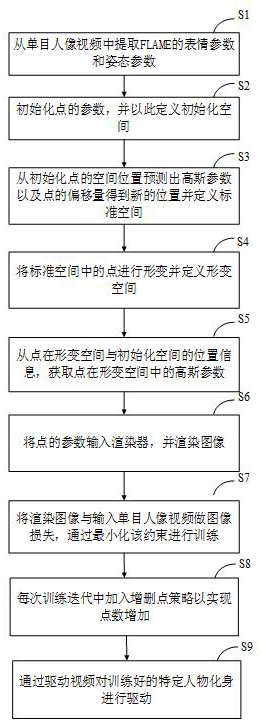
4、从单目人像视频中提取flame的表情参数和姿态参数;
5、进一步地,将单目人像训练集的数据输入flame拟合网络,预测得到对应图像的人脸表情参数和姿态参数。
6、初始化点的参数,并以此定义初始化空间;
7、进一步地,设定初始化点的数量,设定为400个,在空间中随机初始化点的位置,并将此空间定义为初始化空间。
8、从初始化点的空间位置预测出高斯参数以及点的偏移量得到新的位置并定义标准空间;
9、进一步地,从初始化点的空间位置预测出高斯参数以及点的偏移量,并将偏移量与对应点的位置相加,得到新的位置,将此阶段定义为标准空间。
10、将标准空间中的点进行形变并定义形变空间;
11、进一步地,将标准空间中的点的位置输入预先学习好的线性混合蒙皮函数中得到形变后的点,并将此阶段定义为形变空间。
12、从点在形变空间与初始化空间的位置信息,获取点在形变空间中的高斯参数;
13、进一步地,将形变空间中的点的位置与初始化空间中点的位置作差,输入高斯形变场中,得到高斯参数形变量,从而得到点在形变空间中的高斯参数。
14、将点在形变空间中的高斯参数输入渲染器,并渲染图像;
15、进一步地,将点在形变空间中的高斯参数与点的位置输入高斯抛雪球渲染器,得到渲染图像。
16、将渲染图像与输入单目人像视频做图像损失,并结合flame损失和图像感知损失,通过最小化图像损失、flame损失和图像感知损失加权后的和进行训练;
17、进一步地,将渲染图像与输入单目人像视频做图像损失,并结合flame损失和图像感知损失,通过最小化图像损失、flame损失和图像感知损失加权后的和对隐式网络进行训练,学习模型参数。
18、每次训练迭代中加入增删点策略以实现点数增加;
19、进一步地,在每一次训练周期结束时,将不符合要求的点删去,并在每个剩余点的周围随机增加一个点。例如:将点数增至100000时,在每一次训练周期结束时,将不符合要求的点删去,随机在剩余点的周围随机增加一个点,并将点的总数补充至100000。
20、通过驱动视频对训练好的特定人物化身进行驱动。
21、进一步地,将驱动视频中提取到的flame参数输入训练好的网络,得到点位置和与之对应的高斯参数,并输入高斯抛雪球渲染器中,得到对应的特定人物化身驱动动作以及其渲染图像。
22、
技术实现要素:
中提供的效果仅仅是实施例的效果,而不是发明所有的全部效果,上述技术方案中的一个技术方案具有如下优点或有益效果:
23、本发明提供一种基于高斯点渲染的单目人脸化身生成方法,弥补了现有方法驱动人脸化身渲染实时性问题,克服了高斯抛雪球渲染无法渲染动态场景的问题。设计迭代优化的策略,以及高斯点云的增删点策略,充分利用高斯抛雪球渲染器的渲染速度和渲染质量,通过预训练的线性混合蒙皮函数引导高斯参数网络和点的形变网络的训练,以提高人像化身的生成质量。
技术特征:
1.一种基于高斯点渲染的单目人脸化身生成方法,其特征在于:包括以下步骤:
2.如权利要求1所述的一种基于高斯点渲染的单目人脸化身生成方法,其特征是,所述步骤一具体为:将单目人像训练集的数据输入flame拟合网络,预测得到对应图像的人脸表情参数和姿态参数。
3.如权利要求1所述的一种基于高斯点渲染的单目人脸化身生成方法,其特征是,所述步骤二具体为:设定初始化点的数量,在空间中随机初始化点的位置,并将此空间定义为初始化空间。
4.如权利要求1所述的一种基于高斯点渲染的单目人脸化身生成方法,其特征是,所述步骤三具体为:从初始化点的空间位置预测出高斯参数以及点的偏移量,并将偏移量与对应点的位置相加,得到新的位置,将此阶段定义为标准空间。
5.如权利要求1所述的一种基于高斯点渲染的单目人脸化身生成方法,其特征是,所述步骤四具体为:将标准空间中的点的位置输入预先学习好的线性混合蒙皮函数中得到形变后的点,并将此阶段定义为形变空间。
6.如权利要求1所述的一种基于高斯点渲染的单目人脸化身生成方法,其特征是,所述步骤五具体为:将形变空间中点的位置与初始化空间中点的位置作差,输入高斯形变场中,得到高斯参数形变量,从而得到点在形变空间中的高斯参数。
7.如权利要求1所述的一种基于高斯点渲染的单目人脸化身生成方法,其特征是,所述步骤六具体为:将点在形变空间中的高斯参数与点的位置输入高斯抛雪球渲染器得到渲染图。
8.如权利要求1所述的一种基于高斯点渲染的单目人脸化身生成方法,其特征是,所述步骤七具体为:将渲染图像与输入单目人像视频做图像损失,并结合flame损失和图像感知损失,通过最小化图像损失、flame损失和图像感知损失加权后的和对隐式网络进行训练,学习模型参数。
9.如权利要求1所述的一种基于高斯点渲染的单目人脸化身生成方法,其特征是,所述步骤八具体为:在每一次训练周期结束时,将不符合要求的点删去,并在每个剩余点的周围随机增加一个点;将点数增至n时,在每一次训练周期结束时,将不符合要求的点删去,随机在剩余点的周围随机增加一个点,并将点的总数补充至n。
10.如权利要求1所述的一种基于高斯点渲染的单目人脸化身生成方法,其特征是,所述步骤九具体为:将驱动视频中提取到的flame参数输入训练好的网络,得到点位置和与之对应的高斯参数,并输入高斯抛雪球渲染器中,得到对应的特定人物化身驱动动作以及其渲染图像。
技术总结
一种基于高斯点渲染的单目人脸化身生成方法,包括以下步骤:从单目人像视频中提取FLAME的表情参数和姿态参数;定义初始化空间、标准空间、形变空间;从点在形变空间与初始化空间的位置信息,获取点在形变空间中的高斯参数;将点在形变空间中的高斯参数输入渲染器,并渲染图像;将渲染图像与输入单目人像视频做图像损失,通过最小化该约束进行训练;每次训练迭代中加入增删点策略以实现点数增加;通过驱动视频对训练好的特定人物化身进行驱动。本发明设计迭代优化的策略,以及高斯点云的增删点策略,利用高斯抛雪球渲染器的渲染速度和渲染质量,通过预训练的线性混合蒙皮函数引导高斯参数网络和点的形变网络的训练,提高人像化身的生成质量。
技术研发人员:张盛平,陈宇凡,柳青林,孟权令,吕晓倩,王晨阳
受保护的技术使用者:哈尔滨工业大学(威海)
技术研发日:
技术公布日:2024/5/8
- 还没有人留言评论。精彩留言会获得点赞!