一种多源异构数据融合的网络运维实时监控与分析呈现平台的制作方法
本发明涉及一种平台,具体是一种多源异构数据融合的网络运维实时监控与分析呈现平台。
背景技术:
在当前,大量的主机和设备横跨用户的整个信息基础设施,从交换机和路由器到安全设备,主机资产,应用软件,服务器及存储层,从物理层到应用层,运维管理人员无法对所有安全威胁进行100%可视化管理,无法预先防范即将出现的问题,无法快速定位发生问题的原因,或无法提供有说服力的设备故障原因等方面的依据。
很多企业的IT部门为了保证系统的正常运行,部署了各种网络管理和分析工具,但却达不到预期的成效。主要的原因其实就是三大网络管理技术之间(SNMP/SYSLOG/FLOW)没有加以有效的整合。
在大多数情况下,各设备的CPU之所以升高通常是因为它必须要处理瞬间流经的大量数据包。使用SNMP监控技术的网关工具只能监测到CPU升高的状况和具体数值,卻无法告知是哪些IP发送了大量数据包才造成了性能负担。IT管理者必须使用另一套管理工具--Flow分析系统自行找出可疑的IP地址。然而,就算知道了IP地址,如果网络复杂且庞大,想要进一步了解这些IP在哪個具体位置(ex:哪個Switch3的哪個Port)?是谁正在操作这台电脑?而又是什么样的Application让这些IP发送了这么大量的数据包?是电脑中毒或被植入了木马吗?这些问题的答案还是只能再从Syslog分析去慢慢拼凑蛛丝马迹。
下面是企业一些经常出现的问题:
网络异常缓慢时该如何快速定位原因?
员工反映有些邮件收不到也发不出去,真的是邮件服务器的问题吗?
无法浏览外部网站,或是客戶反映无法浏览我们的网站,什么原因?
公司网站遭受入侵攻击或重要的信息被泄露该如何处理和防御?
如何知道各部门的网络使用量?流量这么大是什么样的服务占用了网络资源?
员工无法登陆网络使用IT资源,故障原因是什么,如何能最快速度定位?
管理的网络这么庞大,这么多人使用网络,我怎么能及时知道哪些IP发生了异常?谁正在用这个IP?这个IP在哪个物理位置?
信息安全事件这么多,每个时间点应该要优先处理的事件是什么?
目前市场上针对IT运维的产品和工具很多,但是没有一款能将三大网络管理技术之间(SNMP/SYSLOG/FLOW)(运维大数据)加以有效的整合和关联。
技术实现要素:
本发明的目的在于提供一种多源异构数据融合的网络运维实时监控与分析呈现平台,以解决上述背景技术中提出的问题。
为实现上述目的,本发明提供如下技术方案:
一种多源异构数据融合的网络运维实时监控与分析呈现平台,对网络流量、网络行为、系统日志分别采用不同的分布式数据采集模块,采集流经各个网络设备的网络流量数据、不同网络设备的行为数据以及其系统日志数据;数据采集模块通过网络,包括带内网络和带外网络,将所采集的数据传输到消息队列中;流式处理模块对缓存在消息队列中的数据进行流水线处理,其能够完成数据整理、路由还原功能,并将处理后的数据存入内存数据库中,内存数据库能够提供高性能的数据读写能力;大数据处理模块定时轮询内存数据库,并采用分布式并行处理的方式,快速地对海量数据进行定制化处理;大数据处理模块同时将已完成的数据流数据传输到消息队列中;关系型数据库按照一定的时间间隔存储大量数据流的统计数据,并提供统计数据访问接口,以供前端呈现模块调用;采用分布式数据库存储来自消息队列的海量数据,分布式数据库依靠分布式文件系统的大容量和高可靠特性保证海量数据的安全存储;同时分布式数据库通过查询工具提供历史详细数据的查询功能,以供前端呈现模块调用。
作为本发明进一步的方案:所述消息队列是在数据的传输过程中保存消息的容器,能够解决数据采集速率和处理速率不匹配的问题,当后续处理模块不可用时,起到缓存数据的作用,避免产生数据丢失的问题。
作为本发明再进一步的方案:所述的对海量数据进行定制化处理,包括对网络中所有的数据流进行统计,统计的数据流具体包括已完成的数据流和未完成的数据流,按自定义指标统计出前N条数据流,并将该N条数据流的元信息存入关系型数据库中。
与现有技术相比,本发明的有益效果是:本发明的系统平台能够提供大规模网络运维监控能力,实时准确地对网络流量、网络行为和设备日志进行采集、存储和分析,并提供路由还原和异常检测等功能,使得运维人员对于网络情况有更加直观的认识且能够及时发现网络异常。
附图说明
图1为多源异构数据融合的网络运维实时监控与分析呈现平台的控制流程图。
图2为多源异构数据融合的网络运维实时监控与分析呈现平台的一个具体实施例的控制流程图。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
请参阅图1~2,本发明实施例中,一种多源异构数据融合的网络运维实时监控与分析呈现平台,对网络流量101、网络行为102、系统日志103分别采用不同的分布式数据采集模块,采集流经各个网络设备的网络流量数据、不同网络设备的行为数据以及其系统日志数据;
数据采集模块通过网络,包括带内网络和带外网络,将所采集的数据传输到消息队列111中。消息队列111是在数据的传输过程中保存消息的容器,能够解决数据采集速率和处理速率不匹配的问题,而且当后续处理模块不可用时,起到缓存数据的作用,可以避免产生数据丢失的问题。
流式处理模块112对缓存在消息队列111中的数据进行流水线处理,其能够完成数据整理、路由还原等功能,并将处理后的数据存入内存数据库113中。内存数据库113能够提供高性能的数据读写能力。
大数据处理模块114定时轮询内存数据库113,并采用分布式并行处理的方式,快速地对海量数据进行定制化处理。如对网络中所有的数据流进行统计,包括已完成的数据流和未完成的数据流,按自定义指标统计出前N条数据流,并将该N条数据流的元信息存入关系型数据库121中;大数据处理模块114同时将已完成的数据流数据传输到消息队列122中。关系型数据库121按照一定的时间间隔存储大量数据流的统计数据,并提供统计数据访问接口,以供前端呈现模块131调用,可自定义时间区间进行查询。
分布式数据库123存储来自消息队列122的海量数据。分布式数据库123依靠分布式文件系统124的大容量和高可靠等特性保证海量数据的安全存储。同时分布式数据库123通过查询工具125提供历史详细数据的查询功能,以供前端呈现模块131调用,可自定义进行查询。
网络流量采集模块101采用NetFlow协议系统;
网络行为采集模块102采用SNMP(简单网络管理协议)系统;
系统日志采集模块采用syslog协议系统;
消息队列模块111采用高吞吐量的分布式消息系统Kafka;
流式处理模块112采用大规模流式数据处理系统Spark Streaming;
内存数据库113采用著名的开源键值对内存数据库Redis;
大数据处理模块114采用开源大规模数据计算引擎Spark;
关系型数据库121模块采用开源关系型数据库MySQL;
消息队列模块122采用高吞吐量的分布式消息系统Kafka;
分布式数据库123采用开源面向列的分布式数据库HBase;
分布式文件系统124采用开源大规模分布式文件系统HDFS;
查询工具模块125采用开源数据仓库工具Hive,可将结构化的数据文件映射为一张数据库表,并提供SQL查询功能。
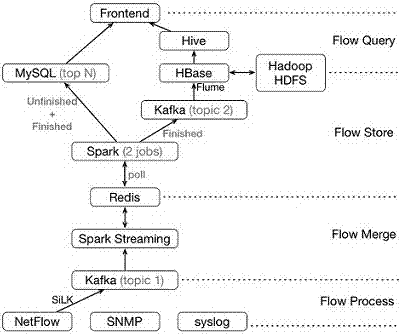
从NetFlow到Kafka(topic 1)为数据流处理(Flow Process)部分:网络流量采集工具SiLK将其解析出来的NetFlow数据包信息保存在预先定义的flow record结构体中,然后从这个结构体将所需信息读取出来,并以CSV的格式将这些信息传送到Kafka的特定topic上。
从Kafka(topic 1)往上到Redis为数据还原(Flow Merge)部分:Spark Streaming会读取存储在Redis中未完成(Unfinished)的数据流信息,并从Kafka的特定topic上获取NetFlow记录,判断NetFlow记录是在Redis中已有的未完成的数据流还是新到来的数据流。更新那些未完成的数据流,同时添加新到来的数据流。
数据流存储(Flow Store)部分:运行在Spark中的job定期轮询Redis读取所有的数据流记录,包括未完成的(Unfinished)数据流和已完成的(Finished)数据流,然后分为两路进行处理。轮询的时间间隔可自定义设置,目前设置与Flow Merge中的时间间隔相同(3秒)。
a)一路将已完成(Finished)的数据流记录写入到Kafka的特定topic中,同时删除Redis中已完成的数据流记录。使用Flume中间件从Kafka特定topic中读取已完成的数据流,并按照其key的组合方式序列化后存储到HBase中。HBase中的key为六元组(数据流开始时间+源IP+源端口+目的IP+目的端口+协议类型)。HBase使用Hadoop HDFS作为后端存储。
b)另一路统计所有数据流在当前设置的时间间隔(目前设置为1min)内的Top 100数据流,并按时间窗口的整数倍存入MySQL中。
数据流查询(Flow Query)部分同样分为两路:
a)使用Hive建立外部表查询HBase(提供条件查询),可以根据用户的输入使用Hive做查询,并返回查询结果;同时也设置了从Web界面查看HBase的功能。
统计Top N部分给前端提供一个查询接口,使用户可以查询自定义时间段内Top 100的数据流。查询时间段为存入数据时间间隔的整数倍(目前为1min的整数倍)。
对于本领域技术人员而言,显然本发明不限于上述示范性实施例的细节,而且在不背离本发明的精神或基本特征的情况下,能够以其他的具体形式实现本发明。因此,无论从哪一点来看,均应将实施例看作是示范性的,而且是非限制性的,本发明的范围由所附权利要求而不是上述说明限定,因此旨在将落在权利要求的等同要件的含义和范围内的所有变化囊括在本发明内。不应将权利要求中的任何附图标记视为限制所涉及的权利要求。
此外,应当理解,虽然本说明书按照实施方式加以描述,但并非每个实施方式仅包含一个独立的技术方案,说明书的这种叙述方式仅仅是为清楚起见,本领域技术人员应当将说明书作为一个整体,各实施例中的技术方案也可以经适当组合,形成本领域技术人员可以理解的其他实施方式。
- 还没有人留言评论。精彩留言会获得点赞!