一种摄像头实时快速字幕叠加的方法与流程
本发明涉及通信设备技术领域,尤其涉及一种摄像头实时快速字幕叠加的方法。
背景技术:
在视频会议中,通常都是全国各地不同地方的人参加同一个视频会议,各个视频参与方并不是相互熟悉,当各个地方的视频画面合并成一个大的视频画面并呈现给所有参与方的时候,由于视频画面中缺少字幕,我们无法通过字幕的方式,将一些需要呈现给所有会议参与方的信息(如:会议参与方名字、所在公司、所在地方等)实时叠加到视频图像里面去,从而无法让各个参与方可以实时了解同本次视频会议相关的一些其他信息,如:会议日期、会议时间等。
在视频会议中,由于摄像头捕捉到的视频数据格式主要有yuv、mjpg、h264等,而mjpg、h264解码后的格式也主要是yuv格式,因此,一些开源的视频图像处理软件对字幕的处理方法为:为了进行不同颜色和透明度的字幕叠加,先将yuv视频图像转化为rgb格式,然后将彩色字幕图像转化为rgb格式,再将转化后的彩色字幕图像和摄像头捕捉到的视频图像进行叠加,合并成一张图像,并进行透明度等相关处理,然后再将rgb转化回编码器需要的yuv图像格式,最后编码并传送出去。
上述处理方式是对每一帧视频数据都进行了:“yuv转化为rgb,再将rgb转回yuv”的过程,两次图像转换对系统的消耗极大,仅仅每秒几十兆的内存拷贝就令一般的cpu无法承担,再加上图像处理,直接导致cpu无法满足高清图像的处理,并导致每秒能够处理的帧率大大下降,严重影响系统性能,降低视频质量。
技术实现要素:
本发明要解决的技术问题,在于提供一种摄像头实时快速字幕叠加的方法,避开了复杂的图像处理和海量的内存拷贝,提高系统性能。
本发明是这样实现的:
一种摄像头实时快速字幕叠加的方法,包括如下步骤:
步骤1、根据字幕内容和字幕的字号大小,生成对应的点阵图像,再将点阵图像转化为点阵数据;
步骤2、根据字幕颜色和字幕透明度将点阵数据转化为yuv数据;
步骤3、根据摄像头捕捉到的视频图像的分辨率、字幕占用的视频图像范围和用户配置的显示位置,确定字幕叠加到摄像头捕捉到的视频图像中具体的叠加位置;
步骤4、根据yuv数据及叠加位置进行字幕的叠加,从而获得带有字幕的视频图像。
进一步地,所述步骤1具体为:
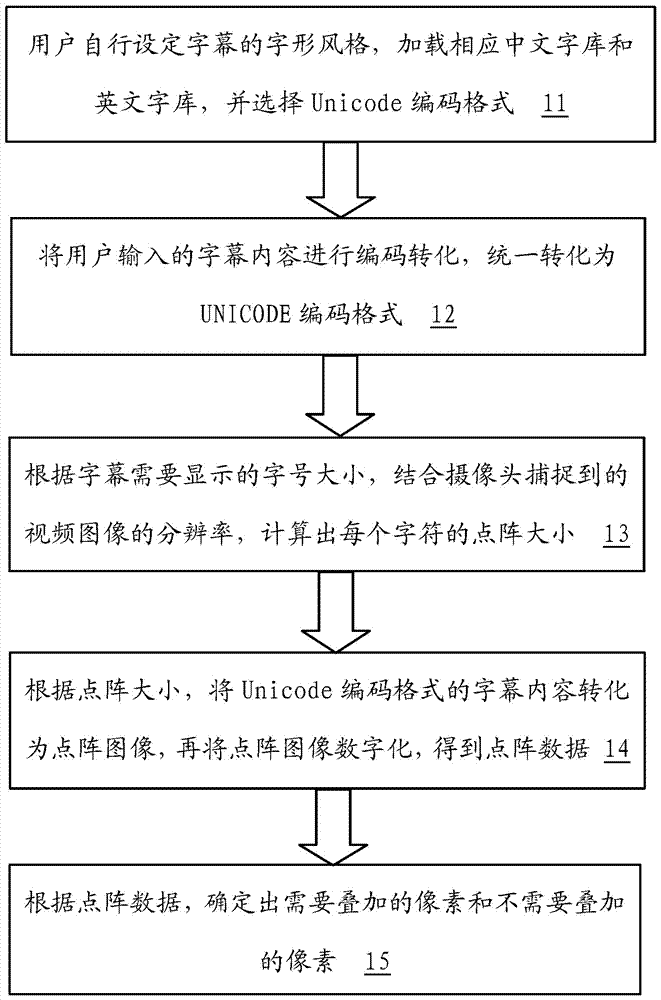
步骤11、用户自行设定字幕的字形风格,加载相应的中文字库和英文字库,并选定unicode编码格式;
步骤12、用户从中文字库和英文字库中获取相应的字幕内容,将用户输入的字幕内容进行编码转化,统一转化为unicode编码格式;
步骤13、根据字幕需要显示的字号大小,结合摄像头捕捉到的视频图像的分辨率,计算出视频图像中每个字符的点阵大小;
步骤14、根据计算出的点阵大小,将unicode编码格式的字幕内容转化为点阵图像,再将点阵图像数字化,得到点阵数据;
步骤15、根据点阵数据,确定出需要叠加的像素和不需要叠加的像素,并将需要叠加的像素标记为1,不需要叠加的像素标记为0。
进一步地,所述步骤2具体为:
步骤21、获取字幕需要显示的字幕颜色;
步骤22、将字幕颜色对应的rgb值转化为对应的需要叠加的像素的yuv值,并将yuv值简化为y1u1v1值;
步骤23、获取字幕需要显示的字幕透明度和摄像头采集的视频图像的y0u0v0值;
步骤24、根据字幕透明度、y0u0v0值和y1u1v1值进行修正,得到修正后的y2u2v2值;
步骤25、根据计算出来的y2u2v2值,将点阵数据转化为yuv数据。
进一步地,所述步骤3具体为:
步骤31、根据获取的字幕所要显示的区域、字幕的横向偏移量和字幕的纵向偏移量,确定出用户配置的字幕显示位置;
步骤32、根据每个字符的点阵大小和字幕内容里的字符个数,确定出字幕占用的视频图像范围;
步骤33、根据摄像头捕捉到的视频图像的分辨率、字幕占用的视频图像范围和用户配置的字幕显示位置,确定字幕叠加到摄像头捕捉到的视频图像中具体的叠加位置。
本发明具有如下优点:
本发明在叠加字幕时不再进行视频格式的转换,而是直接根据字幕的颜色得到这种颜色对应的yuv值,确定出字幕对应的yuv数据,然后找出字幕需要叠加到视频图像的叠加位置,根据yuv数据及叠加位置进行字幕的叠加,从而获得带有字幕的视频图像;这样直接避开了复杂的图像处理和海量的内存拷贝,直接减少cpu的消耗,提高系统性能,使相同性能的cpu可以处理更高分辨率和更大帧率的视频图像,从而可以得到更高清的视频质量。
附图说明
下面参照附图结合实施例对本发明作进一步的说明。
图1为本发明一种摄像头实时快速字幕叠加的方法执行流程图。
图2为本发明一种摄像头实时快速字幕叠加的方法中生成对应的点阵图像并转化为点阵数据的具体流程图。
图3为本发明一种摄像头实时快速字幕叠加的方法中将点阵数据转化为yuv数据的具体流程图。
图4为本发明一种摄像头实时快速字幕叠加的方法中确定叠加位置的具体流程图。
图5为本发明一种摄像头实时快速字幕叠加的方法中数字0的点阵图像的示意图。
具体实施方式
为使得本发明更明显易懂,现以一优选实施例,并配合附图作详细说明如下。
如图1所示,本发明的一种摄像头实时快速字幕叠加的方法,包括如下步骤:
步骤1、根据字幕内容和字幕的字号大小,生成对应的点阵图像,再将点阵图像转化为点阵数据;
步骤2、根据字幕颜色和字幕透明度将点阵数据转化为yuv数据;
步骤3、根据摄像头捕捉到的视频图像的分辨率、字幕占用的视频图像范围和用户配置的显示位置,确定字幕叠加到摄像头捕捉到的视频图像中具体的叠加位置;
步骤4、根据yuv数据及叠加位置进行字幕的叠加,从而获得带有字幕的视频图像。
如图2所示,所述步骤1具体为:
步骤11、用户自行设定字幕的字形风格,加载相应的中文字库和英文字库,并选定unicode编码格式;
步骤12、用户从中文字库和英文字库中获取相应的字幕内容,将用户输入的字幕内容进行编码转化,统一转化为unicode编码格式;
步骤13、根据字幕需要显示的字号大小,结合摄像头捕捉到的视频图像的分辨率,计算出视频图像中每个字符(包括中文字符和英文字符)的点阵大小;其中,计算每个字符的点阵大小的计算方式为:
每次摄像头采集出来的视频图像的分辨率可能是1280×720,也可能是1920×1080,也有可能是800*600等等。但是,无论摄像头采集出来的视频图像的分辨率如何改变,用户都希望字幕的每个汉字使用的大小是一个固定的物理尺寸。比如:一号字体的物理尺寸为9.17mm,如果我们的显示屏宽是27cm,那么每一行可以显示约30个字符。当视频图像的分辨率为1280*720时,每一个字符的点阵大小则为42x42(1280÷30≈42.67,这里直接取42);当视频图像的分辨率为1920*1080时,每一个字符的点阵大小为64x64(1920÷30=64);
步骤14、根据计算出的点阵大小,将unicode编码格式的字幕内容转化为点阵图像,再将点阵图像数字化,得到点阵数据;其中,点阵图像转化为点阵数据的转化方式为:
假设每个字符的点阵大小是8×8,我们使用数据0来说明点阵图像同点阵数据之间的关系。
图5是数字0的点阵图像,与该数字0的点阵图像转化成相对应的点阵数据,转化后的点阵数据为:
0x00
0x3c
0x42
0x42
0x42
0x42
0x42
0x3c
说明:上面是8×8的点阵图像(点阵图像上的一个点就对应显示屏上的一个像素),即有8行,每行有8个表格,每个表格代表的值我们使用一个二进制位来表示。表格里面有黑点的表示二进制1,没有黑点的表示二进制0;所以,第一行表示二进制“00000000”=0x00,第二行表示二进制“00111100”=0x3c,以次类推,就可以将点阵图像转化为点阵数据。
步骤15、根据点阵数据,确定出需要叠加的像素和不需要叠加的像素,并将需要叠加的像素标记为1,不需要叠加的像素标记为0。
如图3所示,所述步骤2具体为:
步骤21、获取字幕需要显示的字幕颜色(颜色是由rgb值(红绿蓝)来表示);
步骤22、将字幕颜色对应的rgb值转化为对应的需要叠加的像素的yuv值,并将yuv值简化为y1u1v1值;其中,转化的计算方法具体如下:
a、算法模型(rgb→yuv的变换):
b、算法公式:
y=0.299r+0.587g+0.114b;
u=-0.1678r-0.3313g+0.5b;
v=0.5r-0.4187g-0.0813b;
c、简化后的算法公式(yuv→y1u1v1):
由于cpu的浮点运算都很差,所以,都需要将浮点运算简化为定点运算;
y1=((0.299r+0.587g+0.114b)*256)>>8;
u1=((-0.1678r-0.3313g+0.5b)*256)>>8;
v1=((0.5r-0.4187g-0.0813b)*256)>>8;
即:
y1=((77*r+150*g+29*b)>>8);
u1=((-43*r-85*g+128*b)>>8);
v1=((128*r-107*g-21*b)>>8);
步骤23、获取字幕需要显示的字幕透明度和摄像头采集的视频图像的y0u0v0值;
步骤24、根据字幕透明度、y0u0v0值和y1u1v1值进行修正,得到修正后的y2u2v2值;
一幅彩色图像的每个像素用r,g,b三个分量表示,若每个分量用8位,那么一个像素共用3x8=24位表示。在用32位表示一个像素时,若r,g,b分别用8位表示,剩下的8位常称为alpha位,即通常我们说的透明度。alpha的取值一般为0到255。当alpha的取值为0时,表示是全透明的,即字幕内容是看不见的;当alpha的取值为255时,表示显示字幕内容是完全看的见的;当alpha的取值为中间值时,表示显示字幕内容为半透明状态。
计算alpha时,通常的方法是将源像素(字幕内容中需要叠加的像素)的y1u1v1值,分别与目标像素(即摄像头采集的视频图像)的y0u0v0值按比例混合,最后得到一个混合后的y2u2v2值。
修正计算公式为:
y2=(y1*alpha+y0*(256-alpha))/256;
u2=(u1*alpha+u0*(256-alpha))/256;
v2=(v1*alpha+v0*(256-alpha))/256;
所以,只考虑透明度后字幕内容的修正值如下:
y2=(y1*alpha)/256;
u2=(u1*alpha)/256;
v2=(v1*alpha)/256;
步骤25、根据计算出来的y2u2v2值,将点阵数据转化为yuv数据。
如图4所示,所述步骤3具体为:
步骤31、根据获取的字幕所要显示的区域(即字幕要显示在显示屏上的大体位置)、字幕的横向偏移量和字幕的纵向偏移量,确定出用户配置的字幕显示位置;
a、字幕在显示屏顶部居中显示(即字幕所要显示的区域(大体位置)),并距离显示屏顶部p厘米(即字幕纵向偏移量),距离显示屏左边m厘米(即字幕的横向偏移量)和距离显示屏右边n厘米(即字幕的横向偏移量)相等;
b、字幕在显示屏左下方显示(即字幕所要显示的区域(大体位置)),并距离显示屏底部q厘米(即字幕纵向偏移量),距离显示屏左边m厘米(即字幕的横向偏移量);
c、字幕在显示屏右下方显示(即字幕所要显示的区域(大体位置)),并距离显示屏底部q厘米(即字幕纵向偏移量),距离显示屏右边n厘米(即字幕的横向偏移量);
步骤32、根据每个字符的点阵大小和字幕内容里的字符个数,确定出字幕占用的视频图像范围;即有:
根据每个字符的点阵大小(如m×n)和字幕内容里面的字符个数y,确定字幕占用的视频图像范围为:(my)×n;
例:如果每个字符的点阵大小是8×8,如果字幕内容有10个字符,则字幕占用的视频图像范围为:80×8;
步骤33、根据摄像头捕捉到的视频图像的分辨率、字幕占用的视频图像范围和用户配置的字幕显示位置,确定字幕叠加到摄像头捕捉到的视频图像中具体的叠加位置。
本发明的优点如下:
本发明在叠加字幕时不再进行视频格式的转换,而是直接根据字幕的颜色得到这种颜色对应的yuv值,确定出字幕对应的yuv数据,然后找出字幕需要叠加到视频图像的叠加位置,根据yuv数据及叠加位置进行字幕的叠加,从而获得带有字幕的视频图像;这样直接避开了复杂的图像处理和海量的内存拷贝,直接减少cpu的消耗,提高系统性能,使相同性能的cpu可以处理更高分辨率和更大帧率的视频图像,从而可以得到更高清的视频质量。
虽然以上描述了本发明的具体实施方式,但是熟悉本技术领域的技术人员应当理解,我们所描述的具体的实施例只是说明性的,而不是用于对本发明的范围的限定,熟悉本领域的技术人员在依照本发明的精神所作的等效的修饰以及变化,都应当涵盖在本发明的权利要求所保护的范围内。
- 还没有人留言评论。精彩留言会获得点赞!