基于深度学习的视频拆条方法与流程
本发明涉及媒资管理技术领域,更具体的说,涉及一种基于深度学习的
视频拆条方法。
背景技术:
随着电视节目生产全流程的数字化,网络化、信息化以及电视节目的不断发展,积累了大量的多媒体数据,面对海量的多媒体资源无法深度开发和利用以及我国对电视节目的监管要求不断提升,拆条技术应运而生。而互联网的不断发展,使得视频素材量呈现爆炸式增长,直播、小视频、网络电视节目、移动多媒体等不是进行完整的节目播出,而是需要拆分或精简小视频,用户对互联网内容的碎片化需求不断增加,拆条在新媒体中也有越来越广泛的应用。
传统拆条方法是人工拆条即人工逐帧预览手工拆条,需要大量的人力投入且效率太低。现有技术是基于云架构的拆条方法,和传统的拆条方式比效率有所提高,在内容产出的时效性和软件成本方面有较大的优势,但需要大量的人力投入,并没有将人力从大量低质量的重复劳动中解放出来。
技术实现要素:
有鉴于此,本发明提供一种可以降低拆条工作中人力投入的基于深度学习的视频拆条方法,用于解决现有技术中需要大量的人力投入的问题。
本发明提供了一种基于深度学习的视频拆条方法,包括以下步骤:
步骤1:视频数据初始化;
步骤2:利用人脸识别技术进行人脸检测,得到连续出现相似人脸的时间片段作为候选拆条片段;
步骤3:在候选的拆条片段中,提取声音特征;
步骤4:利用声音识别技术和所述声音特征细化候选拆条片段的拆条时间点,得到最终的拆条时间点。
可选的,所述步骤1中视频数据初始化包括获取视频数据中的音频波形数据和图像数据。
可选的,所述步骤2中的人脸识别技术包括:使用深度学习算法对人脸进行编码,比较视频数据中各个图像帧人脸的相似性。
可选的,所述步骤4中声音识别技术包括:使用深度学习算法在候选拆条片段的拆条时间点前后一定范围中寻找与所述提取声音特征具有相似特征的声音。
可选的,所述使用深度学习算法对人脸进行编码过程包括:
训练深度神经网络模型,使其能够对输入的人脸提取特征;
输入视频数据的图像数据到所述深度神经网络模型,提取图像数据的高维度人脸特征;
进行编码,即将高维度人脸特征映射为低维度的向量;
根据低维度的向量,辨别视频数据中的人脸相似或不同。
本发明中与现有技术相比,具有以下优点:本发明中利用深度学习算法对人脸和声音两个特征进行识别,提高了拆条的准确性,且可同时对多个视频片段进行人脸和声音识别,速度极快。此外,深度学习算法可以对视频进行智能拆条,减少了人力的投入。
附图说明
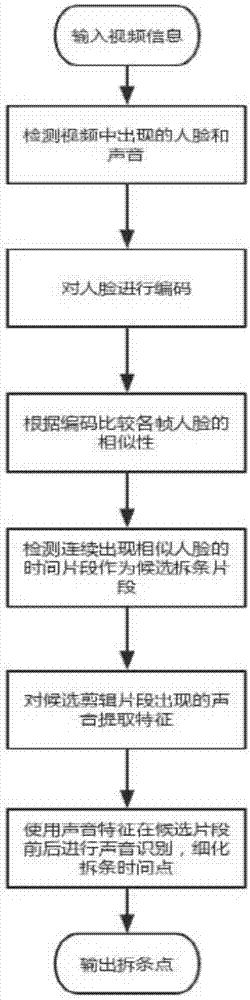
图1为本发明基于深度学习的视频拆条方法的流程图。
具体实施方式
以下结合附图对本发明的优选实施例进行详细描述,但本发明并不仅仅限于这些实施例。本发明涵盖任何在本发明的精神和范围上做的替代、修改、等效方法以及方案。
为了使公众对本发明有彻底的了解,在以下本发明优选实施例中详细说明了具体的细节,而对本领域技术人员来说没有这些细节的描述也可以完全理解本发明。
在下列段落中参照附图以举例方式更具体地描述本发明。需说明的是,附图均采用较为简化的形式且均使用非精准的比例,仅用以方便、明晰地辅助说明本发明实施例的目的。
本发明提供了一种基于深度学习的视频拆条方法,如图1所示,包括以下步骤:
步骤1:视频数据初始化;
步骤2:利用人脸识别技术进行人脸检测,得到连续出现相似人脸的时间片段作为候选拆条片段;
步骤3:在候选的拆条片段中,提取声音特征;
步骤4:利用声音识别技术和所述声音特征细化候选拆条片段的拆条时间点,得到最终的拆条时间点。
所述步骤1中视频数据初始化包括获取视频数据中的音频波形数据和图像数据。
所述步骤2中的人脸识别技术包括:使用深度学习算法对人脸进行编码,比较视频数据中各个图像帧人脸的相似性,将出现相似人脸的的连续时间片段视为一个拆条片段,故可以得到多个拆条片段。
所述步骤4中声音识别技术包括:使用深度学习算法在候选拆条片段的拆条时间点前后一定范围中寻找与所述提取声音特征具有相似特征的声音。
所述使用深度学习算法对人脸进行编码过程包括:
训练深度神经网络模型,使其能够对输入的人脸提取特征;
输入视频数据的图像数据到所述深度神经网络模型,提取图像数据的高维度人脸特征;
进行编码,即将高维度人脸特征映射为低维度的向量;
根据低维度的向量,辨别视频数据中的人脸相似或不同。
通过将多张人脸图像信息映射成低维度向量,模型可以辨别出两张人脸是相似或相同。
在实际过程中,可以先利用分布式算法对视频进行分析和处理,将视频以指定秒数(如10秒)为粒度,划分为若干片段。而后将这些片段分配给可用的服务器同时进行人脸和声音的检测,速度极快,可以实现秒级短视频生产。
以上所述的实施方式,并不构成对该技术方案保护范围的限定。任何在上述实施方式的精神和原则之内所作的修改、等同替换和改进等,均应包含在该技术方案的保护范围之内。
技术特征:
技术总结
本发明公开了一种基于深度学习的视频拆条方法,包括以下步骤:步骤1:视频数据初始化;步骤2:利用人脸识别技术进行人脸检测,得到连续出现相似人脸的时间片段作为候选拆条片段;步骤3:在候选的拆条片段中,提取声音特征;步骤4:利用声音识别技术和所述声音特征细化候选拆条片段的拆条时间点,得到最终的拆条时间点。本发明中利用深度学习算法对人脸和声音两个特征进行识别,提高了拆条的准确性,且可同时对多个视频片段进行人脸和声音识别,速度极快。此外,深度学习算法可以对视频进行智能拆条,减少了人力的投入。
技术研发人员:倪攀;姜子琛;彭梅;刘睿;刘宜飞
受保护的技术使用者:杭州星犀科技有限公司
技术研发日:2018.06.29
技术公布日:2018.12.14
- 还没有人留言评论。精彩留言会获得点赞!