通信网络上的逐片AI/ML模型推断的制作方法
本文所公开的实施方案总体涉及无线通信,并且例如涉及用于通信网络上的ai/ml模型推断的方法、装置和系统。
背景技术:
1、深度神经网络(dnn)是将某个输入域映射到另一个域(输出)的复杂函数。dnn由若干神经层(通常是串联的)组成,并且每个神经层由若干感知器组成。感知器是由输入和非线性函数(例如s型函数)的线性组合组成的函数。
2、因此,dnn由两个元素组成:架构,包括感知器的数量和它们之间的连接,以及参数,这些参数是线性函数的权重,并且如果需要,还包括非线性函数的参数。
3、通过机器学习算法对巨大数据集进行训练,这些模型最近已被证明对于广泛的应用是有用的,并且已导致对人工智能、计算机视觉、音频处理和若干其他领域中现有技术的显著改进。由于这些模型在今天的流行,它们通常被称为“ai/ml模型”。
4、除了dnn,决策树和随机森林是可以考虑的机器学习技术的其他示例。决策树是可以用根、分支和叶表示的分类和回归方法。其结构基于被称为节点的嵌套式if-else条件,树从这些节点拆分为分支。不再拆分的分支末端是叶或决策。决策树学习适用于从医学诊断到工业的广泛领域。
5、应用程序越来越依赖于终端用户设备上运行的ai/ml模型,以在严格的延迟要求下提供交互式结果。这些ai/ml模型通常位于远程服务器上,例如在边缘处或在云中,并且模型大小在几千字节到几百兆字节的范围内。移动设备将请求下载新的ai/ml模型或更新版本的ai/ml模型,通常是在启动新服务、改变应用程序环境或在增量学习的情况下。当应用程序请求时,终端用户将必须等待模型的完整下载,然后才能使用输入数据运行推断。另一个缺点是,移动设备需要在存储器中加载完整模型来运行推断,并且由于内存不足或可用磁盘空间不足,这有时是不可能的。
技术实现思路
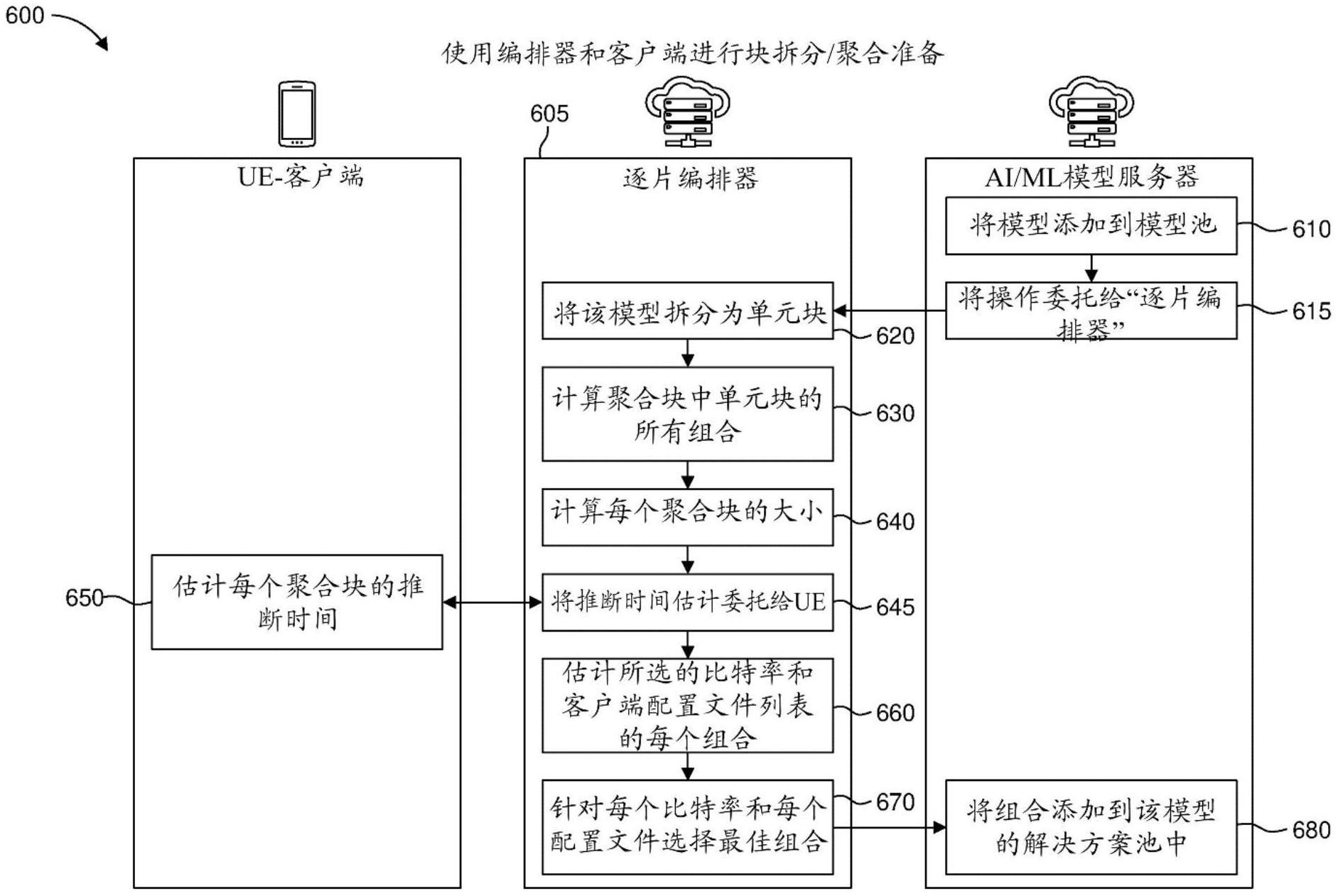
1、根据实施方案,提供了一种方法,包括:将ai/ml模型拆分为多个子部分;以及基于与所述多个子部分相关联的下载时间和推断时间,形成聚合块集合,每个聚合块对应于所述多个子部分的一个或多个子部分。
2、根据另一个实施方案,提供了一种方法,包括:接收作为ai/ml模型的一部分的块;从所述块生成第一推断或中间结果;接收也作为所述ai/ml模型的一部分的后续块;以及基于所述第一推断或中间结果和所述后续块生成推断结果。
3、根据另一个实施方案,提出了一种服务器,包括一个或多个处理器和至少一个存储器,所述一个或多个处理器被配置为:将ai/ml模型拆分为多个子部分;以及基于与所述多个子部分相关联的下载时间和推断时间,形成聚合块集合,每个聚合块对应于所述多个子部分的一个或多个子部分。
4、根据另一个实施方案,提出了一种用户设备,包括一个或多个处理器和至少一个存储器,所述一个或多个处理器被配置为:接收作为ai/ml模型的一部分的块;从所述块生成第一推断或中间结果;接收也作为所述ai/ml模型的一部分的后续块;以及基于所述第一推断或中间结果和所述后续块生成推断结果。
技术特征:
1.一种方法,所述方法包括:
2.根据权利要求1所述的方法,其中所述聚合块集合进一步基于设备约束形成。
3.根据权利要求2所述的方法,其中所述设备约束包括可用存储器和聚合块的加载时间中的至少一者。
4.根据权利要求1-3中任一项所述的方法,其中待首先传输的聚合块可用于在不使用其他聚合块的情况下生成推断或中间结果。
5.根据权利要求1-4中任一项所述的方法,其中在首次之后待传输的聚合块可用于生成具有先前中间结果的推断或中间结果,并且不使用其他聚合块。
6.根据权利要求1-5中任一项所述的方法,其中每个子部分对应于一个或多个神经网络层。
7.根据权利要求1-6中任一项所述的方法,所述方法还包括:
8.根据权利要求1-7中任一项所述的方法,所述方法还包括:
9.根据权利要求1-8中任一项所述的方法,所述方法还包括:
10.根据权利要求1-9中任一项所述的方法,其中每个聚合块包括以下项中的一者或多者:
11.根据权利要求1-10中任一项所述的方法,其中所述ai/ml模型是卷积神经混合模型,并且其中所述ai/ml模型被拆分为修剪的cnn(卷积神经网络)混合模型和移除的cnn。
12.根据权利要求1-10中任一项所述的方法,其中所述ai/ml模型在早期退出(ee)阶段被拆分。
13.根据权利要求1-10中任一项所述的方法,其中所述ai/ml模型基于可精简神经网络。
14.根据权利要求1-10中任一项所述的方法,其中所述ai/ml模型使用决策树模型,并且其中根节点成为模型入口,并且源自决策树拆分的子分支成为中间块或最终块。
15.一种方法,所述方法包括:
16.根据权利要求15所述的方法,其中下载所述后续块和所述生成第一推断或中间结果并行地执行。
17.根据权利要求15或16所述的方法,所述方法还包括在生成所述第一推断或中间结果之后删除所述块。
18.根据权利要求15-17中任一项所述的方法,所述方法还包括:
19.一种包括处理器和非暂态计算机可读存储介质的装置,所述非暂态计算机可读存储介质存储在所述处理器上被执行时操作以执行根据权利要求1-17中任一项所述的方法的指令。
20.一种计算机可读存储介质,所述计算机可读存储介质具有存储在其上的指令,所述指令用于执行根据权利要求1-17中任一项所述的方法。
技术总结
在一个实施方式中,AI/ML模型首先被拆分为对应于该模型的子部分的若干单元块。然后,通过考虑下载时间、单元块的推断时间和/或设备约束来进行单元块的聚合。第一拆分对应于AI/ML层的第一块,其一旦被下载,就可按原样使用,并基于一些感测/感知数据生成中间结果。一旦有新的块到达,该块就被用来基于先前块的中间数据生成新的结果。由于下载和推断是并行的,因此可以比使用全顺序方法更早地生成最终结果。此外,一旦推断在块上结束,该块就可以从设备中移除。提供了若干AI/ML模型拆分方法来为不同的模型架构生成模型子集/块。
技术研发人员:T·菲洛奇,C·昆奎斯,P·方丹,P·勒古亚德克,A·兰伯特,F·施尼茨勒
受保护的技术使用者:交互数字CE专利控股有限公司
技术研发日:
技术公布日:2024/1/12
- 还没有人留言评论。精彩留言会获得点赞!