用于自适应波束形成的系统和方法与流程
背景技术:
1、本公开整体涉及用于自适应波束形成的系统和方法。
技术实现思路
1、下文提及的所有示例和特征均可以任何技术上可能的方式组合。
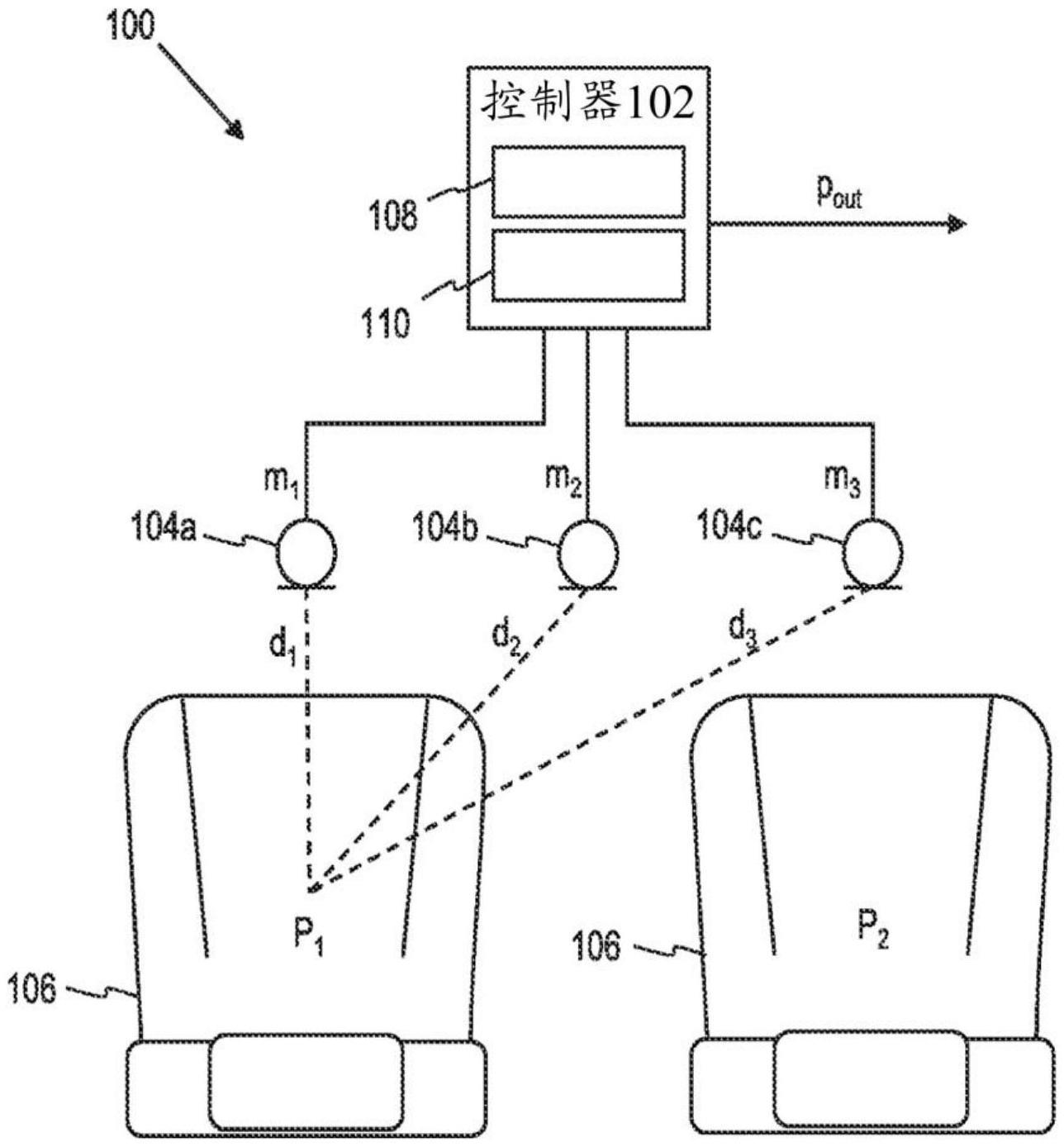
2、根据一个方面,一种自适应波束形成系统,包括:设置在车辆座舱各处的多个麦克风,该多个麦克风中的每个麦克风都生成麦克风信号,其中车辆座舱限定多个乘坐位置;语音活动检测器,该语音活动检测器被配置为:当至少坐在该多个乘坐位置中的目标座位中的用户在说话时进行检测;以及自适应波束形成器,该自适应波束形成器被配置为:从多个麦克风接收麦克风信号,并且根据自适应波束形成算法,基于麦克风信号和噪声相干矩阵,生成目标乘坐位置处的声学信号的估计,其中当根据语音活动检测器,坐在该目标乘坐位置中的用户在说话时,停止更新噪声相干矩阵。
3、在一个示例中,根据用户选择来选择目标座位。
4、在一个示例中,根据语音活动检测器检测到的多个乘坐位置中的哪个乘坐位置的用户正在说话来选择目标座位。
5、在一个示例中,自适应波束形成器被进一步配置为:当根据语音活动检测器,坐在多个乘坐位置中的任一个乘坐位置中的用户在说话时,噪声相干矩阵停止更新。
6、在一个示例中,自适应波束形成器被进一步配置为:计算多个噪声相干矩阵,其中的每个噪声相干矩阵都表示多个乘坐位置中的相应的相关联乘坐位置处的噪声条件,其中当根据语音活动检测器,坐在该相关联乘坐位置中的用户在说话时,停止更新该多个噪声相干矩阵中的每个噪声相干矩阵。
7、在一个示例中,自适应波束形成器被进一步配置为:当根据语音活动检测器,坐在目标乘坐位置中的用户在说话并且坐在第二目标乘坐位置中的用户在说话时,生成第二目标乘坐位置处的第二声学信号的估计,其中声学信号和该第二声学信号的估计相加在一起。
8、在一个示例中,自适应波束形成器被进一步配置为:当根据语音活动检测器,坐在目标乘坐位置中的用户在说话并且坐在第二目标乘坐位置中的用户在说话时,根据第二自适应波束形成算法,生成声学信号和第二目标乘坐位置处的第二声学信号的估计。
9、在一个示例中,第二自适应波束形成算法是线性约束最小方差波束形成算法。
10、根据另一个方面,一种自适应波束形成系统,包括:设置在车辆座舱各处的多个麦克风,该多个麦克风中的每个麦克风都生成麦克风信号,其中车辆座舱限定多个乘坐位置;语音活动检测器,该语音活动检测器被配置为:当坐在多个乘坐位置中的目标乘坐位置中的用户在说话时进行检测;以及自适应波束形成器,该自适应波束形成器被配置为:从多个麦克风接收麦克风信号,并且根据自适应波束形成算法,基于该麦克风信号以及第一噪声相干矩阵和第二噪声相干矩阵中的一者,生成目标乘坐位置处的声学信号的估计,其中该第一噪声相干矩阵是通过将第一先前计算的噪声相干矩阵与第一新计算的噪声相干矩阵递归地求和来计算的,其中该第一先前计算的噪声相干矩阵的加权比该第一新计算的噪声相干矩阵更重,其中当语音活动检测器检测到坐在目标乘坐位置中的用户在说话时,使用该第一噪声相干矩阵来更新该自适应波束形成器的系数,其中该第二噪声相干矩阵是通过将第二先前计算的噪声相干矩阵与第二新计算的噪声相干矩阵递归地求和来计算的,其中该第二先前计算的噪声相干矩阵的加权比该第二新计算的噪声相干矩阵更轻,其中当语音活动检测器未检测到坐在目标乘坐位置中的用户在说话时,使用该第二噪声相干矩阵来更新自适应波束形成滤波器的系数。
11、在一个示例中,使用在先前帧期间存储的历史第一噪声相干矩阵来更新自适应波束形成器的系数,其中在语音活动检测器检测到坐在目标乘坐位置中的用户在说话之前至少预定时间段存储该历史第一噪声相干矩阵,其中该预定时间段大于语音活动检测器检测到目标用户在说话所需要的延迟。
12、根据另一个方面,一种自适应波束形成系统,包括:设置在车辆座舱各处的多个麦克风,该多个麦克风中的每个麦克风都生成麦克风信号,其中车辆座舱限定多个乘坐位置;以及自适应波束形成器,该自适应波束形成器被配置为:从多个麦克风接收麦克风信号,并且根据自适应波束形成算法,基于该麦克风信号和噪声相干矩阵,生成目标乘坐位置处的声学信号的估计,其中该噪声相干矩阵至少部分地从预定噪声相干矩阵确定,该预定噪声相干矩阵表示由设置在车辆座舱的至少一个扬声器引到该车辆座舱中的噪声条件。
13、在一个示例中,根据噪声条件的幅值来设置预定噪声相干矩阵的增益。
14、在一个示例中,预定噪声相干矩阵的增益在多个样本上增加。
15、在一个示例中,当噪声条件停止被引到车辆座舱时,从更新噪声相干矩阵中减去预定噪声相干矩阵,其中该更新噪声相干矩阵是根据多个麦克风信号针对噪声相干矩阵的更新。
16、在一个示例中,噪声相干矩阵包括计算噪声相干矩阵与预定噪声相干矩阵之和,其中该计算的噪声相干矩阵在与该预定噪声相干矩阵求和之前从反转状态求逆。
17、在一个示例中,预定噪声相干矩阵作为反转矩阵检索。
18、根据另一个方面,一种自适应波束形成系统,包括:设置在车辆座舱各处的多个麦克风,该多个麦克风中的每个麦克风都生成麦克风信号,其中车辆座舱限定多个乘坐位置;自适应波束形成器,该自适应波束形成器被配置为:从多个麦克风接收麦克风信号,并且根据自适应波束形成算法,基于该麦克风信号和噪声相干矩阵,生成目标乘坐位置处的声学信号的估计,其中将人工白噪声信号添加到多个麦克风信号中的每个麦克风信号,使得改善声学信号的估计的白噪声增益。
19、在一个示例中,选择人工白噪声信号使得在预定频率范围内实现最小白噪声增益。
20、在一个示例中,人工白噪声信号是预定的。
21、在一个示例中,根据座舱内的噪声条件从多个人工白噪声信号中选择人工白噪声信号。
22、在一个示例中,调整人工白噪声信号,使得噪声相干矩阵的条件数在频率上保持在预定范围之内。
23、一个或多个具体实施的细节在附图和以下描述中论述。其他特征、对象和优点在说明书、附图和权利要求书中将是显而易见的。
技术特征:
1.一种自适应波束形成系统,包括:
2.根据权利要求1所述的系统,其中根据用户选择来选择所述目标座位。
3.根据权利要求1所述的系统,其中所述目标座位根据所述多个乘坐位置中所述语音活动检测器检测到用户正在说话的那个乘坐位置而被选择。
4.根据权利要求1所述的系统,其中所述自适应波束形成器被进一步配置为:当根据所述语音活动检测器,坐在所述多个乘坐位置中的任一个乘坐位置中的用户在说话时,停止更新所述噪声相干矩阵。
5.根据权利要求1所述的系统,其中所述自适应波束形成器被进一步配置为:计算多个噪声相干矩阵,所述多个噪声相干矩阵中的每个噪声相干矩阵都表示所述多个乘坐位置中的相应的相关联乘坐位置处的噪声条件,其中当根据所述语音活动检测器,坐在所述相关联乘坐位置中的用户在说话时,所述多个噪声相干矩阵中的每个噪声相干矩阵被停止更新。
6.根据权利要求1所述的系统,其中所述自适应波束形成器被进一步配置为:当根据所述语音活动检测器,坐在所述目标乘坐位置中的所述用户在说话并且坐在第二目标乘坐位置中的所述用户在说话时,生成所述第二目标乘坐位置处的第二声学信号的估计,其中所述声学信号和所述第二声学信号的所述估计相加在一起。
7.根据权利要求1所述的系统,其中所述自适应波束形成器被进一步配置为:当根据所述语音活动检测器,坐在所述目标乘坐位置中的所述用户在说话并且坐在第二目标乘坐位置中的所述用户在说话时,根据第二自适应波束形成算法,生成所述声学信号和所述第二目标乘坐位置处的第二声学信号的估计。
8.根据权利要求7所述的系统,其中所述第二自适应波束形成算法是线性约束最小方差波束形成算法。
9.一种自适应波束形成系统,包括:
10.根据权利要求9所述的系统,其中使用在先前帧期间存储的历史第一噪声相干矩阵来更新所述自适应波束形成器的所述系数,其中在所述语音活动检测器检测到坐在所述目标乘坐位置中的所述用户在说话之前的至少预定时间段存储所述历史第一噪声相干矩阵,其中所述预定时间段大于所述语音活动检测器检测到目标用户在说话所需要的延迟。
11.一种自适应波束形成系统,包括:
12.根据权利要求11所述的系统,其中根据所述噪声条件的幅值来设置所述预定噪声相干矩阵的增益。
13.根据权利要求12所述的系统,其中所述预定噪声相干矩阵的所述增益在多个样本上增加。
14.根据权利要求11所述的系统,其中当所述噪声条件停止被引到所述车辆座舱时,从更新的噪声相干矩阵中减去所述预定噪声相干矩阵,其中所述更新的噪声相干矩阵是根据所述多个麦克风信号对所述噪声相干矩阵的更新。
15.根据权利要求11所述的系统,其中所述噪声相干矩阵包括所计算的噪声相干矩阵和所述预定噪声相干矩阵之和,其中所计算的噪声相干矩阵在与所述预定噪声相干矩阵求和之前从反转状态求逆。
16.根据权利要求11所述的系统,其中所述预定噪声相干矩阵作为反转矩阵检索。
17.一种自适应波束形成系统,包括:
18.根据权利要求17所述的系统,其中所述人工白噪声信号被选择为使得在预定频率范围内实现最小白噪声增益。
19.根据权利要求17所述的系统,其中所述人工白噪声信号是预定的。
20.根据权利要求17所述的系统,其中所述人工白噪声信号根据所述座舱内的所述噪声条件从多个人工白噪声信号中选择。
21.根据权利要求17所述的系统,其中所述人工白噪声信号被调整为使得所述噪声相干矩阵的条件数在频率上被保持在预定范围之内。
技术总结
本公开涉及一种用于捕获用户的语音的系统,包括:设置在车辆座舱各处的多个麦克风,该多个麦克风中的每个麦克风都生成麦克风信号,其中该车辆座舱限定多个乘坐位置;语音活动检测器,该语音活动检测器被配置为:当至少坐在该多个乘坐位置中的目标座位中的用户在说话时进行检测;以及自适应波束形成器,该自适应波束形成器被配置为:从该多个麦克风接收麦克风信号,并根据自适应波束形成算法,基于该麦克风信号和噪声相干矩阵,生成该目标乘坐位置处的声学信号的估计,其中当根据该语音活动检测器,坐在该目标乘坐位置中的用户在说话时,停止更新该噪声相干矩阵。
技术研发人员:E·博达赫,C·M·赫拉
受保护的技术使用者:伯斯有限公司
技术研发日:
技术公布日:2024/1/14
- 还没有人留言评论。精彩留言会获得点赞!