一种基于云计算大数据服务器的数据管理方法和系统与流程
1.本发明属于大数据处理分析领域,具体的,涉及一种基于云计算大数据服务器的数据管理方法和系统。
背景技术:
2.云计算业务服务器端不断整合服务,各种系统都整合在云计算服务器中,各个系统的数据都是孤立的;通常采用的方式是数据库物化视图、goldengate等数据库技术实现数据同步,而采用这种方法有几种弊端,一是系统内部各个模块之间数据同步还可以,如果是系统间数据同步,一般就没法实现了。二是同步的数据不够准确,可能会有部分垃圾数据。三是各个数据库关联性太强,如果系统需要更新或者业务变化,都影响数据同步工作。基于此,现提供一种采用数据库锁的方式来实现云计算环境下并发控制任务的调用工作的方法,一是保证了数据同步的效率;二是系统需要什么样的数据我们就同步什么样的数据。
3.随着云计算业务服务器端不断整合服务,各种系统都整合在云计算服务器中,各个系统的数据都是孤立的;通常采用的方式是数据库物化视图、goldengate等数据库技术实现数据同步,而采用这种方法有几种弊端,一是系统内部各个模块之间数据同步还可以,如果是系统间数据同步,一般就没法实现了。二是同步的数据不够准确,可能会有部分垃圾数据。三是各个数据库关联性太强,如果系统需要更新或者业务变化,都影响数据同步工作。四是数据之间同步有延迟,无法实时同步到生产环境中。我们采用消息队列、监听器、监听端口和数据库锁的方式来实现云计算环境下并发实时同步数据的调用工作,一是保证了数据同步的效率;二是系统需要什么样的数据我们就同步什么样的数据,三是保证实时同步到生产环境中。
4.云计算是网格计算、效用计算、网络存储、虚拟化、负载均衡等计算机技术和网络技术相融合的产物。它将所有的计算资源集中起来,并由软件实现自动管理,用户无需参与实际的管理。这使得企业和个人没有必要为计算能力和存储以及对这些资源的管理而烦恼,能够更加专注于自己的业务流程,有利于创新和降低成本。作为一种按需服务、高性价比和资源透明化的业务提供方式,其本质就是通过对互联网的计算、存储及传送等资源的池化,满足不同用户的个性化、多层次服务需求。云计算提供了可靠、安全的数据存储中心,用户不必再担心数据丢失、病毒入侵等严重问题;同时云计算可应用于多种用户终端设备,电脑、手机、电视等终端均可接入;此外,云计算可以轻松实现不同设备间的数据与应用共享,更重要的是云计算在网络使用方面也提供了无限多的可能。
5.目前,云计算平台下的数据同步还存在效率不高的问题。
技术实现要素:
6.本发明实施例的目的在于提供一种基于云计算大数据服务器的数据管理方法和系统,以实现动态的为客户端分配云同步服务器。具体技术方案如下:
7.为了达到上述目的,第一方面,本发明实施例提供了一种基于云计算大数据服务
器的数据管理方法,其特征在于,包括:
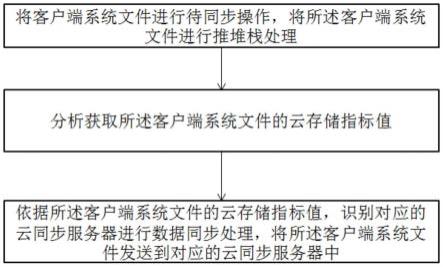
8.将客户端系统文件进行待同步操作,将所述客户端系统文件进行推堆栈处理;
9.分析获取所述客户端系统文件的云存储指标值;
10.依据所述客户端系统文件的云存储指标值,识别对应的云同步服务器进行数据同步处理,将所述客户端系统文件发送到对应的云同步服务器中。
11.可选的,所述将客户端系统文件进行待同步操作,将所述客户端系统文件进行推堆栈处理,具体包括:
12.创建第一堆栈,将所述堆栈赋进栈时间标签,所述进栈时间标签表示允许进入所述第一堆栈的客户端系统文件的同步时间区间范围;
13.所述客户端系统文件需要进行待同步操作时,获取所述客户端系统文件的同步时间,如果所述客户端系统文件的同步时间处于所述第一堆栈的客户端系统文件的同步时间区间范围中,则将所述客户端系统文件入所述堆栈处理;
14.如果所述客户端系统文件的同步时间不处于所述第一堆栈的客户端系统文件的同步时间区间范围中,则创建第二堆栈,将所述第二堆栈赋进栈时间标签,所述进栈时间标签表示允许进入所述第二堆栈的客户端系统文件的同步时间区间范围,将所述待处理数据进行入第二堆栈处理。
15.可选的,所述分析获取所述客户端系统文件的云存储指标值,还包括:
16.监测客户端系统的历史数据;
17.将所述客户端系统的历史数据进行评估;
18.将各客户端系统文件的动态数据属性进行评估;
19.基于所述客户端系统的历史数据、所述各客户端系统文件的动态数据属性获取所述客户端系统文件的云存储指标值。
20.可选的,所述依据所述客户端系统文件的云存储指标值,识别对应的云同步服务器进行数据同步处理,将所述客户端系统文件发送到对应的云同步服务器中,还包括:
21.当所述客户端系统文件的云存储指标值属于第一云同步服务器的云存储指标值范围时,开启所述第一云同步服务器的同步处理通道;
22.获取当前同步处理时间,如果所述同步处理时间属于第一时间范围,将所述客户端系统文件发送至所述第一云同步服务器;
23.如果所述同步处理时间不属于第一时间范围,将所述客户端系统文件发送至第一备份云同步服务器。
24.可选的,所述当所述客户端系统文件的云存储指标值属于第一云同步服务器的云存储指标值范围时,开启所述第一云同步服务器的同步处理通道前,还包括:
25.获取所述客户端系统文件的单位时间的同步处理密度,如果所述客户端系统文件的单位时间的同步处理密度大于预设阈值,获取所述客户端系统文件单位时间内的多个客户端系统文件的云存储指标值在所述客户端系统的占比,开启所述单位时间内的多个客户端系统文件发送给云存储指标值占比最多的云同步服务器,将其作为最优云同步服务器,并将所述客户端系统文件发送至所述最优云同步服务器;
26.获取所述最优云同步服务器的最优时间范围和所述最优云同步服务器中不属于所述云同步服务器的类型的客户端系统文件,获取属于所述云同步服务器的类型的客户端
系统文件的第二云同步服务器的第二时间范围,获取所述最优时间范围和所述第二时间范围的重叠部分,在所述重叠部分的时间到来时,开启所述最优云同步服务器和第二云同步服务器,将所述不属于所述云同步服务器的类型的客户端系统文件发送至所述第二云同步服务器;
27.如果所述最优时间范围和所述第二时间范围不存在重叠,依据预设闲时时间范围,在所述预设闲时时间范围内,开启所述最优云同步服务器和第二云同步服务器,将所述不属于所述云同步服务器的类型的客户端系统文件发送至所述第二云同步服务器。
28.本发明实施例还提供了一种基于云计算大数据服务器的数据管理系统,其特征在于,包括:
29.待同步操作模块,将客户端系统文件进行待同步操作,将所述客户端系统文件进行推堆栈处理;
30.权重划分模块,分析获取所述客户端系统文件的云存储指标值;
31.同步处理模块,依据所述客户端系统文件的云存储指标值,识别对应的云同步服务器进行数据同步处理,将所述客户端系统文件发送到对应的云同步服务器中。
32.可选的,所述待同步操作模块,将客户端系统文件进行待同步操作,将所述客户端系统文件进行推堆栈处理,具体包括:
33.创建第一堆栈,将所述堆栈赋进栈时间标签,所述进栈时间标签表示允许进入所述第一堆栈的客户端系统文件的同步时间区间范围;
34.所述客户端系统文件需要进行待同步操作时,获取所述客户端系统文件的同步时间,如果所述客户端系统文件的同步时间处于所述第一堆栈的客户端系统文件的同步时间区间范围中,则将所述客户端系统文件入所述堆栈处理;
35.如果所述客户端系统文件的同步时间不处于所述第一堆栈的客户端系统文件的同步时间区间范围中,则创建第二堆栈,将所述第二堆栈赋进栈时间标签,所述进栈时间标签表示允许进入所述第二堆栈的客户端系统文件的同步时间区间范围,将所述待处理数据进行入第二堆栈处理。
36.可选的,所述权重划分模块,分析获取所述客户端系统文件的云存储指标值,还包括:监测客户端系统的历史数据;
37.将所述客户端系统的历史数据进行评估;
38.将各客户端系统文件的动态数据属性进行评估;
39.基于所述客户端系统的历史数据、所述各客户端系统文件的动态数据属性获取所述客户端系统文件的云存储指标值。
40.可选的,所述同步处理模块,依据所述客户端系统文件的云存储指标值,识别对应的云同步服务器进行数据同步处理,将所述客户端系统文件发送到对应的云同步服务器中,还包括:
41.当所述客户端系统文件的云存储指标值属于第一云同步服务器的云存储指标值范围时,开启所述第一云同步服务器的同步处理通道;
42.获取当前同步处理时间,如果所述同步处理时间属于第一时间范围,将所述客户端系统文件发送至所述第一云同步服务器;
43.如果所述同步处理时间不属于第一时间范围,将所述客户端系统文件发送至第一
备份云同步服务器。
44.可选的,所述当所述客户端系统文件的云存储指标值属于第一云同步服务器的云存储指标值范围时,开启所述第一云同步服务器的同步处理通道前,还包括:
45.获取所述客户端系统文件的单位时间的同步处理密度,如果所述客户端系统文件的单位时间的同步处理密度大于预设阈值,获取所述客户端系统文件单位时间内的多个客户端系统文件的云存储指标值在所述客户端系统的占比,开启所述单位时间内的多个客户端系统文件发送给云存储指标值占比最多的云同步服务器;
46.获取所述最优云同步服务器的最优时间范围和所述最优云同步服务器中不属于所述云同步服务器的类型的客户端系统文件,获取属于所述云同步服务器的类型的客户端系统文件的第二云同步服务器的第二时间范围,获取所述最优时间范围和所述第二时间范围的重叠部分,在所述重叠部分的时间到来时,开启所述最优云同步服务器和第二云同步服务器,将所述不属于所述云同步服务器的类型的客户端系统文件发送至所述第二云同步服务器;
47.如果所述最优时间范围和所述第二时间范围不存在重叠,依据预设闲时时间范围,在所述预设闲时时间范围内,开启所述最优云同步服务器和第二云同步服务器,将所述不属于所述云同步服务器的类型的客户端系统文件发送至所述第二云同步服务器。
48.本发明所请求保护的基于云计算大数据服务器的数据管理方法和系统,通过将客户端系统文件进行待同步操作,将所述客户端系统文件进行推堆栈处理;分析获取所述客户端系统文件的云存储指标值;依据所述客户端系统文件的云存储指标值,识别对应的云同步服务器进行数据同步处理,将所述客户端系统文件发送到对应的云同步服务器中。该方案不单纯考虑了数据的静态属性信息,充分考虑了待发送数据的动态密度变化,和云同步服务器运行状态的动态波动性,将批量到达客户端系统文件进行合理的评估、排序和客户端系统文件分配,实现动态的的历史数据均衡,避免客户端系统文件拥塞和的历史数据热点的形成通过将数据的动态发送的密度信息进行基于考量;同时,本发明还将服务器的同步处理进行定时合理开启和交互同步处理,可以更好地调度发挥各方性能。
附图说明
49.为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将将实施例或现有技术描述中所需要使用的附图作简单地介绍。
50.图1为本发明提供的一种基于云计算大数据服务器的数据管理方法的工作流程图;
51.图2为本发明提供的一种基于云计算大数据服务器的数据管理方法的实施例一的工作流程图;
52.图3为本发明提供的一种基于云计算大数据服务器的数据管理方法的实施例二的工作流程图;
53.图4为本发明提供的一种基于云计算大数据服务器的数据管理方法的实施例三的工作流程图;
54.图5为本发明提供的一种基于云计算大数据服务器的数据管理系统的结构模块图。
具体实施方式
55.下面将结合本发明实施例中的附图,将本发明实施例中的技术方案进行描述。
56.参照附图1,本发明请求保护一种基于云计算大数据服务器的数据管理方法,其特征在于,包括:
57.将客户端系统文件进行待同步操作,将所述客户端系统文件进行推堆栈处理;
58.分析获取所述客户端系统文件的云存储指标值;
59.依据所述客户端系统文件的云存储指标值,识别对应的云同步服务器进行数据同步处理,将所述客户端系统文件发送到对应的云同步服务器中。
60.其中,所述客户端系统文件为客户端持续不断发送的需要给各个云同步服务器的数据,所述客户端系统文件可以但不限于包括:客户端用户的浏览数据,如html类型数据、视频数据、音乐数据;客户端用户的待处理或已处理文件数据,如txt、pdf、word、excel格式等数据。客户端希望将这些数据进行有效的管理。
61.各个云同步服务器为将这些数据进行系统管理的结构,依据多种因素将各个客户端系统文件进行分配至各个云同步服务器是本发明的最终目的。
62.本领域技术人员能够理解,本公开所披露的内容可以出现多种变型和改进。例如,以上所描述的各种设备或组件可以通过硬件实现,也可以通过软件、固件、或者三者中的一些或全部的组合实现。
63.本公开中使用了流程图用来说明根据本公开的实施例的方法的步骤。应当理解的是,前面或后面的步骤不一定按照顺序来精确的进行。相反,可以按照倒序或同时处理各种步骤。同时,也可以将其他操作添加到这些过程中。
64.参照附图2,本发明提供的一种基于云计算大数据服务器的数据管理方法的实施例一的工作流程图;
65.具体的,所述将客户端系统文件进行待同步操作,将所述客户端系统文件进行推堆栈处理,具体包括:
66.创建第一堆栈,将所述堆栈赋进栈时间标签,所述进栈时间标签表示允许进入所述第一堆栈的客户端系统文件的同步时间区间范围;
67.所述客户端系统文件需要进行待同步操作时,获取所述客户端系统文件的同步时间,如果所述客户端系统文件的同步时间处于所述第一堆栈的客户端系统文件的同步时间区间范围中,则将所述客户端系统文件入所述第一堆栈处理;
68.如果所述客户端系统文件的同步时间不处于所述第一堆栈的客户端系统文件的同步时间区间范围中,则创建第二堆栈,将所述第二堆栈赋进栈时间标签,所述进栈时间标签表示允许进入所述第二堆栈的客户端系统文件的同步时间区间范围,将所述待处理数据进行入第二堆栈处理。
69.所述第一堆栈由第一线程创建,所述第一线程由第一云同步服务器分配;
70.所述第一堆栈的进栈时间标签与第一云同步服务器的第一时间范围相同,保证所述进栈的客户端系统文件均符合第一云同步服务器的时间范围。
71.例如第一云同步服务器的第一时间范围为9:00-15:00,则对应的所述第一云同步服务器创建第一线程,所述第一线程创建第一堆栈,为所述第一堆栈赋时间标签9:00-15:00。
72.当客户端系统文件需要进行待同步操作时,获取所述客户端系统文件的同步时间,如果所述客户端系统文件的同步时间为11:00时,其处于所述第一堆栈的客户端系统文件的同步时间区间范围中,则将所述客户端系统文件入所述第一堆栈处理;
73.如果所述客户端系统文件的同步时间为16:00时,其不处于所述第一堆栈的客户端系统文件的同步时间区间范围中,则由第二云同步服务器的第二线程创建第二堆栈,将所述第二堆栈赋进栈时间标签,所述进栈时间标签表示允许进入所述第二堆栈的客户端系统文件的同步时间区间范围,将所述待处理数据进行入第二堆栈处理。
74.其中,16:00需要落入第二云同步服务器的时间范围。
75.具体的,所述分析获取所述客户端系统文件的云存储指标值,还包括:
76.监测客户端系统的历史数据;
77.将所述客户端系统的历史数据进行评估;
78.将各客户端系统文件的动态数据属性进行评估,
79.基于所述客户端系统的历史数据、所述各客户端系统文件的动态数据属性获取所述客户端系统文件的云存储指标值。
80.设定客户端中的云同步服务器数量为n,n>0;
81.所述监测客户端系统的历史数据包括:
82.获取客户端新到达客户端系统文件的数量xdsl、每个新到客户端系统文件将线程数量的历史平均需求lsprocess、每个新到客户端系统文件将存储空间的历史平均需求lsmemory、每个新到客户端系统文件将堆栈大小的历史平均需求lsstack、客户端中各个云同步服务器当前空闲可用的线程数量kxprocess、客户端中各个云同步服务器当前空闲可用存储空间kxmemory、客户端中各个云同步服务器当前空闲可用堆栈大小kxstack、各个云同步服务器上一次完成的客户端系统文件所使用的时间scsj、各个云同步服务器上一次完成客户端系统文件到当前的跨度时间kdsj、各个云同步服务器最近一次宕机持续时间djsj、各个云同步服务器最近一次宕机到当前的跨度时间djkdsj、各个云同步服务器上一次完成客户端系统文件所释放的线程数量sfprocess、各个云同步服务器上一次完成客户端系统文件所释放的存储空间sfmemory、各个云同步服务器上一次完成客户端系统文件所释放的堆栈大小sfstack;
83.所述将所述客户端系统的历史数据进行评估包括:
84.a1、设定所述客户端系统资源历史需求度为lsxqd:
85.计算lsxqd=(lsprocess
×
lsmemory
×
lsstack)/xdsl获取所述客户端系统资源历史需求度lsxqd;
86.a2、设定各个云同步服务器的客户端系统文件空闲执行率为sxzxl:
87.计算sxzxl=(kxprocess
×
kxmemory
×
kxstack)/xdsl获取各个云同步服务器的客户端系统文件空闲执行率;
88.a3、设定近期客户端系统文件空闲影响效应的各个云同步服务器的客户端系统文件历史执行率为lszxl:
89.计算lszxl=(scsj
×
kdsj
×
djsj
×
djkdsj)/xdsl获取近期客户端系统文件空闲影响效应的各个云同步服务器的客户端系统文件历史执行率lszxl;
90.a4、设定等效未来释放执行率为sfzxl:
91.计算sfzxl=(sfprocess
×
sfmemory
×
sfstack)/xdsl获取等效未来释放执行率。
92.所述基于所述客户端系统的历史数据、所述各客户端系统文件的动态数据属性获取所述客户端系统文件的云存储指标值ycczbz包括:
93.计算ycczbz=(lsxqd
×
sxzxl
×
lszxl
×
sfzxl)获取所述客户端系统文件的云存储指标值;
94.参照附图3,本发明提供的一种基于云计算大数据服务器的数据管理方法的实施例二的工作流程图;
95.具体的,所述依据所述客户端系统文件的云存储指标值,识别对应的云同步服务器进行数据同步处理,将所述客户端系统文件发送到对应的云同步服务器中,还包括:
96.当所述客户端系统文件的云存储指标值属于第一云同步服务器的云存储指标值范围时,开启所述第一云同步服务器的同步处理通道;
97.获取当前同步处理时间,如果所述同步处理时间属于第一时间范围,将所述客户端系统文件发送至所述第一云同步服务器;
98.如果所述同步处理时间不属于第一时间范围,将所述客户端系统文件发送至第一备份云同步服务器。
99.例如,通过计算获得客户端系统文件的权重为20,第一云同步服务器的云存储指标值范围为0-50,则开启所述第一云同步服务器的同步处理通道;
100.获取当前同步处理时间为12:00,属于第一时间范围9:00-15:00,将所述客户端系统文件发送至所述第一云同步服务器;
101.如果当前同步处理时间为17:00,不属于第一时间范围9:00-15:00,将所述客户端系统文件发送至第一备份云同步服务器。
102.所述第一备份云同步服务器用于在闲时将其存储的客户端系统文件发送给第一云同步服务器。
103.参照附图4,本发明提供的一种基于云计算大数据服务器的数据管理方法的实施例三的工作流程图;
104.具体的,所述当所述客户端系统文件的云存储指标值属于第一云同步服务器的云存储指标值范围时,开启所述第一云同步服务器的同步处理通道前,还包括:
105.获取所述客户端系统文件的单位时间的同步处理密度,如果所述客户端系统文件的单位时间的同步处理密度大于预设阈值,获取所述客户端系统文件单位时间内的多个客户端系统文件的云存储指标值在所述客户端系统的占比,开启所述单位时间内的多个客户端系统文件发送给云存储指标值占比最多的云同步服务器,将其作为最优云同步服务器,并将所述客户端系统文件发送至所述最优云同步服务器;
106.获取所述最优云同步服务器的最优时间范围和所述最优云同步服务器中不属于所述云同步服务器的类型的客户端系统文件,获取属于所述云同步服务器的类型的客户端系统文件的第二云同步服务器的第二时间范围,获取所述最优时间范围和所述第二时间范围的重叠部分,在所述重叠部分的时间到来时,开启所述最优云同步服务器和第二云同步服务器,将所述不属于所述云同步服务器的类型的客户端系统文件发送至所述第二云同步服务器;
107.如果所述最优时间范围和所述第二时间范围不存在重叠,依据预设闲时时间范
围,在所述预设闲时时间范围内,开启所述最优云同步服务器和第二云同步服务器,将所述不属于所述云同步服务器的类型的客户端系统文件发送至所述第二云同步服务器。
108.具体的,设定单位时间为5min,获取到5min内的客户端系统文件为10条,各条数据的云存储指标值为20,40,42,38,60,70,18,78,42,90,当前第一云同步服务器的云存储指标值范围为0-50,第二云同步服务器的云存储指标值范围为50-100,由此可看出,6条数据处于第一云同步服务器的云存储指标值范围内,4条数据处于第二云同步服务器的云存储指标值范围内,因此,优先开启第一云同步服务器,将其作为最优云同步服务器,并将所述客户端系统文件发送至所述最优云同步服务器,并将该10条数据发送给最优云同步服务器。
109.获取所述最优云同步服务器的最优时间范围9:00-15:00和所述最优云同步服务器中不属于所述云同步服务器的类型的4条客户端系统文件,获取属于所述云同步服务器的类型的4条客户端系统文件的第二云同步服务器的第二时间范围14:00-18:00,获取所述最优时间范围9:00-15:00和所述第二时间范围14:00-18:00的重叠部分14:00-15:00,在所述重叠部分的时间14:00-15:00到来时,开启所述最优云同步服务器和第二云同步服务器,将所述不属于所述云同步服务器的类型的4条客户端系统文件发送至所述第二云同步服务器。
110.如果所述最优时间范围9:00-15:00和所述第二时间范围(假设为16:00-20:00)不存在重叠,依据预设闲时时间范围22:00-5:00,在所述预设闲时时间范围内,开启所述最优云同步服务器和第二云同步服务器,将所述不属于所述云同步服务器的类型的4条客户端系统文件发送至所述第二云同步服务器。
111.参照图5,为本发明提供的一种基于云计算大数据服务器的数据管理系统的结构模块图。
112.本发明实施例还提供了一种基于云计算大数据服务器的数据管理系统,其特征在于,包括:
113.待同步操作模块,将客户端系统文件进行待同步操作,将所述客户端系统文件进行推堆栈处理;
114.权重划分模块,分析获取所述客户端系统文件的云存储指标值;
115.同步处理模块,依据所述客户端系统文件的云存储指标值,识别对应的云同步服务器进行数据同步处理,将所述客户端系统文件发送到对应的云同步服务器中。
116.可选的,所述待同步操作模块,将客户端系统文件进行待同步操作,将所述客户端系统文件进行推堆栈处理,具体包括:
117.创建第一堆栈,将所述堆栈赋进栈时间标签,所述进栈时间标签表示允许进入所述第一堆栈的客户端系统文件的同步时间区间范围;
118.所述客户端系统文件需要进行待同步操作时,获取所述客户端系统文件的同步时间,如果所述客户端系统文件的同步时间处于所述第一堆栈的客户端系统文件的同步时间区间范围中,则将所述客户端系统文件入所述堆栈处理;
119.如果所述客户端系统文件的同步时间不处于所述第一堆栈的客户端系统文件的同步时间区间范围中,则创建第二堆栈,将所述第二堆栈赋进栈时间标签,所述进栈时间标签表示允许进入所述第二堆栈的客户端系统文件的同步时间区间范围,将所述待处理数据
进行入第二堆栈处理。
120.可选的,所述权重划分模块,分析获取所述客户端系统文件的云存储指标值,还包括:监测客户端系统的历史数据;
121.将所述客户端系统的历史数据进行评估;
122.将各客户端系统文件的动态数据属性进行评估,
123.基于所述客户端系统的历史数据、所述各客户端系统文件的动态数据属性获取所述客户端系统文件的云存储指标值。
124.可选的,所述同步处理模块,依据所述客户端系统文件的云存储指标值,识别对应的云同步服务器进行数据同步处理,将所述客户端系统文件发送到对应的云同步服务器中,还包括:
125.当所述客户端系统文件的云存储指标值属于第一云同步服务器的云存储指标值范围时,开启所述第一云同步服务器的同步处理通道;
126.获取当前同步处理时间,如果所述同步处理时间属于第一时间范围,将所述客户端系统文件发送至所述第一云同步服务器;
127.如果所述同步处理时间不属于第一时间范围,将所述客户端系统文件发送至第一备份云同步服务器。
128.可选的,所述当所述客户端系统文件的云存储指标值属于第一云同步服务器的云存储指标值范围时,开启所述第一云同步服务器的同步处理通道前,还包括:
129.获取所述客户端系统文件的单位时间的同步处理密度,如果所述客户端系统文件的单位时间的同步处理密度大于预设阈值,获取所述客户端系统文件单位时间内的多个客户端系统文件的云存储指标值在所述客户端系统的占比,开启所述单位时间内的多个客户端系统文件发送给云存储指标值占比最多的云同步服务器;
130.获取所述最优云同步服务器的最优时间范围和所述最优云同步服务器中不属于所述云同步服务器的类型的客户端系统文件,获取属于所述云同步服务器的类型的客户端系统文件的第二云同步服务器的第二时间范围,获取所述最优时间范围和所述第二时间范围的重叠部分,在所述重叠部分的时间到来时,开启所述最优云同步服务器和第二云同步服务器,将所述不属于所述云同步服务器的类型的客户端系统文件发送至所述第二云同步服务器;
131.如果所述最优时间范围和所述第二时间范围不存在重叠,依据预设闲时时间范围,在所述预设闲时时间范围内,开启所述最优云同步服务器和第二云同步服务器,将所述不属于所述云同步服务器的类型的客户端系统文件发送至所述第二云同步服务器。
132.本领域普通技术人员可以理解上述方法中的全部或部分的步骤可通过计算机程序来指令相关硬件完成,程序可以存储于计算机可读存储介质中,如只读存储器、磁盘或光盘等。可选地,上述实施例的全部或部分步骤也可以使用一个或多个集成电路来实现。相应地,上述实施例中的各模块/单元可以采用硬件的形式实现,也可以采用软件功能模块的形式实现。本公开并不限制于任何特定形式的硬件和软件的结合。
133.除非另有定义,这里使用的所有术语具有与本公开所属领域的普通技术人员共同理解的相同含义。还应当理解,诸如在通常字典里定义的那些术语应当被解释为具有与它们在相关技术的上下文中的含义相一致的含义,而不应用理想化或极度形式化的意义来解
释,除非这里明确地这样定义。
134.以上是将本公开的说明,而不应被认为是将其的限制。尽管描述了本公开的若干示例性实施例,但本领域技术人员将容易地理解,在不背离本公开的新颖教学和优点的前提下可以将示例性实施例进行许多修改。因此,所有这些修改都意图包含在权利要求书所限定的本公开范围内。应当理解,上面是将本公开的说明,而不应被认为是限于所公开的特定实施例,并且将所公开的实施例以及其他实施例的修改意图包含在所附权利要求书的范围内。本公开由权利要求书及其等效物限定。
135.在本说明书的描述中,参考术语“一个实施例”、“一些实施例”、“示意性实施例”、“示例”、“具体示例”、或“一些示例”等的描述意指结合该实施例或示例描述的具体特征、结构、材料或者特点包含于本发明的至少一个实施例或示例中。在本说明书中,将上述术语的示意性表述不一定指的是相同的实施例或示例。而且,描述的具体特征、结构、材料或者特点可以在任何的一个或多个实施例或示例中以合适的方式结合。
136.尽管已经示出和描述了本发明的实施例,本领域的普通技术人员可以理解:在不脱离本发明的原理和宗旨的情况下可以将这些实施例进行多种变化、修改、替换和变型,本发明的范围由权利要求及其等同物限定。
相关技术
网友询问留言
已有1条留言
-
 0155293... 来自[中国] 2023年04月02日 14:47该数据管理方法可以有效过滤垃圾数据和实现数据同步
0155293... 来自[中国] 2023年04月02日 14:47该数据管理方法可以有效过滤垃圾数据和实现数据同步
1