一种针对电力无线网络的基于强化学习的最佳路由调度方法与流程
本发明属于无线传输网络qos保障,涉及接纳控制中的调度算法,尤其涉及一种针对电力无线网络的基于强化学习的最佳路由调度方法。
背景技术:
1、随着居民生活水平的提高,电力通信技术不断发展,越来越多的智能化通信设备被应用与电力通信网络之中。这些新设备的出现一方面满足了客户的新需求,另一方面对网络的多样化qos支持能力也提出了更高的要求。但是通过提高设备性能来满足逐渐增长的服务质量要求,已经到达顶点,进一步提高需要消耗大量资源。相反的是,如何合理利用现有的网络资源,分配合适的通信带宽,仍有较大的进步空间。对于传统的计算机网络而言,主要采用尽力而为的数据调度方法,网络尽最大可能传输报文,只考虑数据是否送达,不考虑链路状态,时延等信息,无法保障qos服务质量。在如今的网络结构下,该调度方法难以满足数据传输要求。因此,需要寻找合适的路由调度算法以满足新时代对于数据传输的要求。
2、传统的动态路由算法可以分为两大类,基于最优化方法的路由算法和基于启发式方法的路由算法。基于最优化方法的路由算法如分层最短路由算法(hierarchicalshortest path algorithm,hsra),该算法将无线网络描述为一系列静态图并建模为时空图,空间链路表示为两个通信节点的无线链路(即信道),时间链路表示为节点讲数据包从一个时隙传送到另一个时隙。该算法通过空间链路转发数据,依靠时间链路计算传播时延和链路可靠性概率,计算数据找出最佳路由,但是算法本身没有考虑链路带宽对qos需求的影响,同时也要求较高的网络检测能力,以便实时更新链路信息。而基于启发式方法的路由算法,也存在着一些问题。如基于蚁群和膜计算的非均匀分簇路由算法,在进行路由选择时,需要将路径分组,进行迭代,再整合信息,迭代选出最佳路由。该算法虽然保证了可靠性,但过程复杂,能耗较大。综上所述,传统的动态路由算法,算法结构简单,稳定性高。但是计算速度慢,无法适应当今的网络环境,难以支撑差异化qos保障需求。而强化学习能够利用智能体(agent)与环境状态参量,进行多次迭代,最终选择能够达到目标的最优动作。面对复杂多变的网络环境,基于真实数据驱动的强化学习可以准确快速的完成寻找出最佳路由。
3、发明目的
4、本发明目的就是应对上述现有技术中所存在的技术问题,基于802.11标准的wlan网络的qos机制中的接纳控制,提供一种基于机器学习的最佳路由算法,利用sdn架构,实时感知网络状态,统一处理数据信息,合理分配通信带宽,防止网络负载超出其承受能力以及保护已有的数据流的传输,满足差异化的qos需求。
技术实现思路
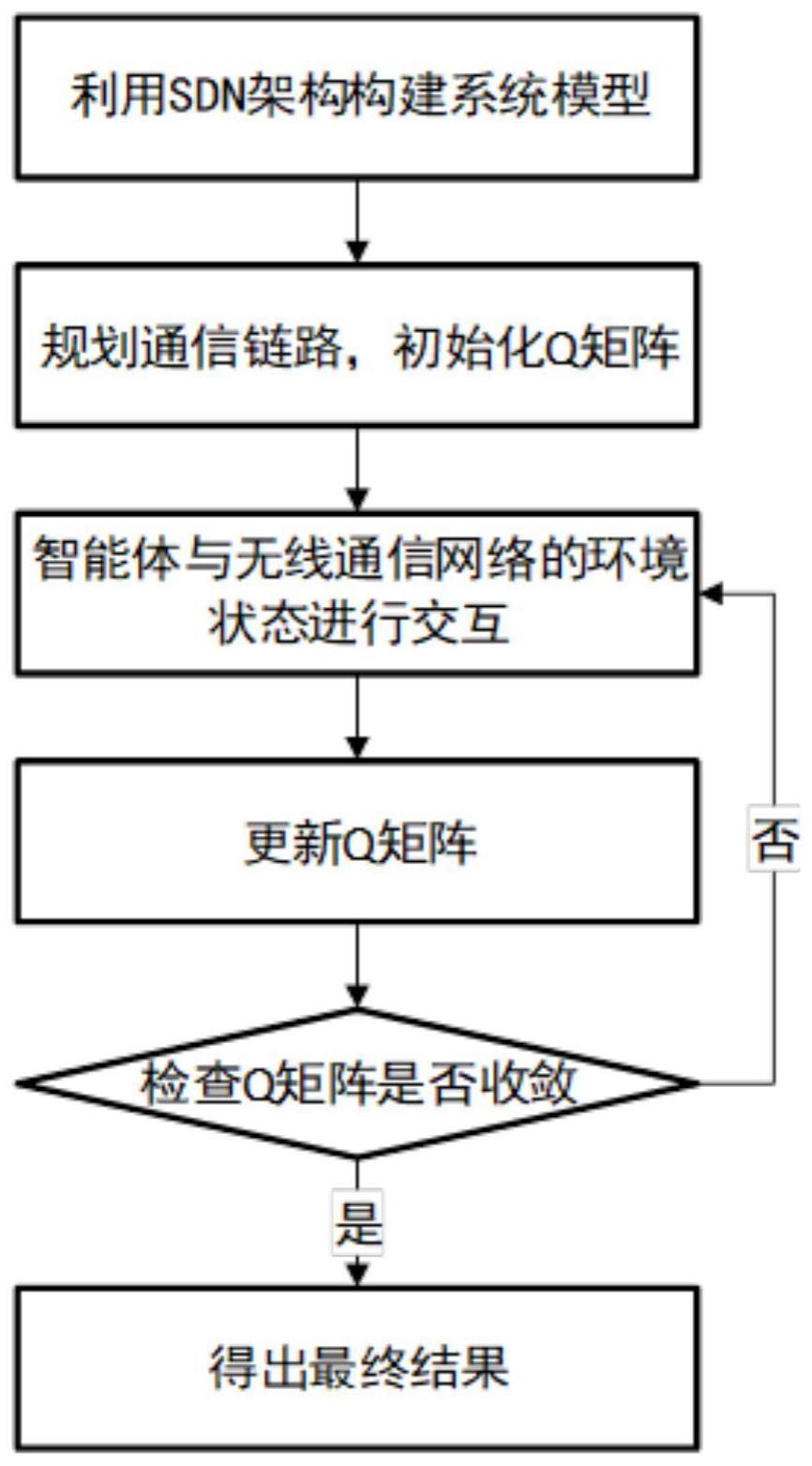
1、本发明提供了一种针对电力无线网络的基于强化学习的最佳路由调度方法,包括以下步骤:
2、步骤s101、利用sdn架构构建系统模型,具体是将无线通信网络部署在sdn架构平台上,在sdn平台上收集网络信息,通过控制器直接管理全局网络,进行强化学习;所述sdn架构包括应用层、控制层和转发层,其中,所述应用层为用户服务,负责收集网络信息,监控网络状态;所述控制层对应用层收集来的数据进行处理,更新r值表和q值表;在迭代完成后,依靠q值表,控制信息下一跳选择;所述转发层由通信设备组成,负责执行决策,完成路由选择;所述系统模型中设定所选信道的最大传输速率w大于信息正常传输所需带宽b,如果出现多个信道同时满足条件,则选择拥有较大传输速率的链路作为传输信道。
3、步骤s102、规划通信链路,初始化q矩阵,具体是在传递信息通过源节点进入无线通信网络之前,依靠信息的目的节点和业务类型,通过dijkstra算法,规划出多条满足传输要求的通信线路,提高q矩阵收敛速度;将路由选择问题映射成为马尔可夫决策过程,其中状态集<s>设定为所选通信链路中的所有节点集合,动作集<a>设定为信息在节点s处的下一跳可选择的全部节点集合,基于动作选定后,下一个状态固定,所以概率转移矩阵p为1,奖励函数r与时延,丢包率,带宽相关;该mdp(马尔可夫决策过程)的四元组均为已知,利用强化学习中的q-learning算法进行迭代求解;
4、步骤s103、智能体与无线通信网络的环境状态进行交互,其中,所述无线通信网络的环境状态参数包括链路剩余带宽、通信时延和信道丢包率;
5、步骤s104、更新q矩阵;
6、步骤s105、重复步骤s103到步骤s104直到网络结果收敛,将训练好的网络应用于无线通信网络的路由选择中。
7、优选地,所述步骤s101中,用一个有向图g(v,e)来表示无线通信网络,其中顶点集v表示通信节点的集合,边集e表示为通信链路的集合,每条链路的容量,即信道带宽有限;所述有向图g(v,e)中的节点代表网络中的通信节点,由网络中的路由器和交换机构成,节点间的连线代表着信道,箭头的方向即为信息的传输方向,某一时刻信息通过源节点向整个网络递交发送请求,且带宽需求稳定;在网络状态保持稳定的前提下,信息传送过程中,信道的带宽,时延,丢包率,网络拓扑默认不会变化;
8、优选地,所述步骤s103中设定b(s,a)为带宽参数,被表示为如式(1)所示:
9、
10、其中w为链路剩余带宽,b为通信所需最低带宽;
11、t(s,a)为时延参数,被表示为如式(2)所示:
12、t(s,a)=tanh(-αt+b) (2),
13、其中α,b为常量,t为链路时延;
14、l(s,a)为丢包率参数,被表示为如式(3)所示:
15、
16、其中δ为信息在传输过程中能接受的最大丢包率,l为链路实际丢包率;
17、通过ε-greedy方法选择下一跳节点,得到下一个状态s'和奖赏函数r(s,a),该奖赏函数r(s,a)被表示为如式(4)所示:
18、
19、其中x,y,z为调整参数,针对不同的业务类型,优先级,合理调节不同参数的权重,满足差异化的qos服务需求;
20、用四维元组(s,a,s',r)储存这一过程的数据并放入经验池。
21、优选地,所述步骤s104包括:从经验池中取出执行步骤s103得到的样本(s,a,s',r)进行训练,当信息在节点s处选择动作a到达节点s'后,更新自我状态,在q矩阵中,选择能使q值最大的动作a',得到q(s',a'),于是矩阵q(s,a)更新被为如式(5)所示:
22、
23、其中q(s,a)为更新前的q值,α为学习率,γ为奖励性衰变系数。
24、优选地,所述步骤s105包括:在信息到达目的节点后,源节点向目的节点重新发送信息,重复步骤s103到s104,通过ε-greedy方法,随机选择通信节点,多次迭代,直至q矩阵完成收敛,最后将训练好的网络应用于无线通信网络的路由选择中,在路由选择过程中,选择最大的q值,即为最佳路由调度。
技术特征:
1.一种针对电力无线网络的基于强化学习的最佳路由调度方法,其特征在于,包括以下步骤:
2.根据权利要求1所述的一种针对电力无线网络的基于强化学习的最佳路由调度方法,其特征在于,所述步骤s101中,用一个有向图g(v,e)来表示无线通信网络,其中顶点集v表示通信节点的集合,边集e表示为通信链路的集合,每条链路的容量,即信道带宽有限;所述有向图g(v,e)中的节点代表网络中的通信节点,由网络中的路由器和交换机构成,节点间的连线代表着信道,箭头的方向即为信息的传输方向,某一时刻信息通过源节点向整个网络递交发送请求,且带宽需求稳定;在网络状态保持稳定的前提下,信息传送过程中,信道的带宽,时延,丢包率,网络拓扑默认不会变化。
3.根据权利要求2所述的一种针对电力无线网络的基于强化学习的最佳路由调度方法,其特征在于,所述步骤s103中设定b(s,a)为带宽参数,被表示为如式(1)所示:
4.根据权利要求3所述的一种针对电力无线网络的基于强化学习的最佳路由调度方法,其特征在于,所述步骤s104包括:从经验池中取出执行步骤s103得到的样本(s,a,s',r)进行训练,当信息在节点s处选择动作a到达节点s'后,更新自我状态,在q矩阵中,选择能使q值最大的动作a',得到q(s',a'),于是矩阵q(s,a)更新被为如式(5)所示:
5.根据权利要求4所述的一种针对电力无线网络的基于强化学习的最佳路由调度方法,其特征在于,所述步骤s105包括:在信息到达目的节点后,源节点向目的节点重新发送信息,重复步骤s103到s104,通过ε-greedy方法,随机选择通信节点,多次迭代,直至q矩阵完成收敛,最后将训练好的网络应用于无线通信网络的路由选择中,在路由选择过程中,选择最大的q值,即为最佳路由调度。
技术总结
本发明公开了一种针对电力无线网络的基于强化学习的最佳路由调度方法,包括以下步骤:步骤S101、利用SDN架构构建系统模型;步骤S102、规划通信链路,初始化Q矩阵;步骤S103、智能体与无线通信网络的环境状态进行交互;步骤S104、更新Q矩阵;步骤S105、重复步骤S103到步骤S104直到网络结果收敛,将训练好的网络应用于无线通信网络的路由选择中。本发明利用SDN架构方式,合理调节信道资源分配,来满足差异化的QoS服务需求,建立无线通信网络系统模型,将路由选择问题映射成为马尔可夫决策过程过程,进行迭代求解,最后将训练好的网络应用于无线通信网络的路由选择中。
技术研发人员:刘超,冯尚友,肖博,高鼎,马军,曹超,王克敏,王旭阳,李贝伦
受保护的技术使用者:国网甘肃省电力公司信息通信公司
技术研发日:
技术公布日:2024/1/15
- 还没有人留言评论。精彩留言会获得点赞!