说话人视频生成方法、装置及电子设备与流程
本发明涉及人工智能,尤其涉及一种说话人视频生成方法、装置及电子设备。
背景技术:
1、说话人视频生成技术的目标是,基于一段音频和给定的人物形象生成对应人物的讲话视频,并使得说话人口型与音频匹配。相关技术中,基于nerf的说话人视频生成方法在生成单张图像时,对图像上所有像素位置进行采样并发出光线,处理的数据量较大,导致说话人视频生成的速度较慢。
技术实现思路
1、本发明实施例提供一种说话人视频生成方法、装置及电子设备,以解决相关技术中说话人视频生成的速度较慢的问题。
2、为解决上述技术问题,本发明是这样实现的:
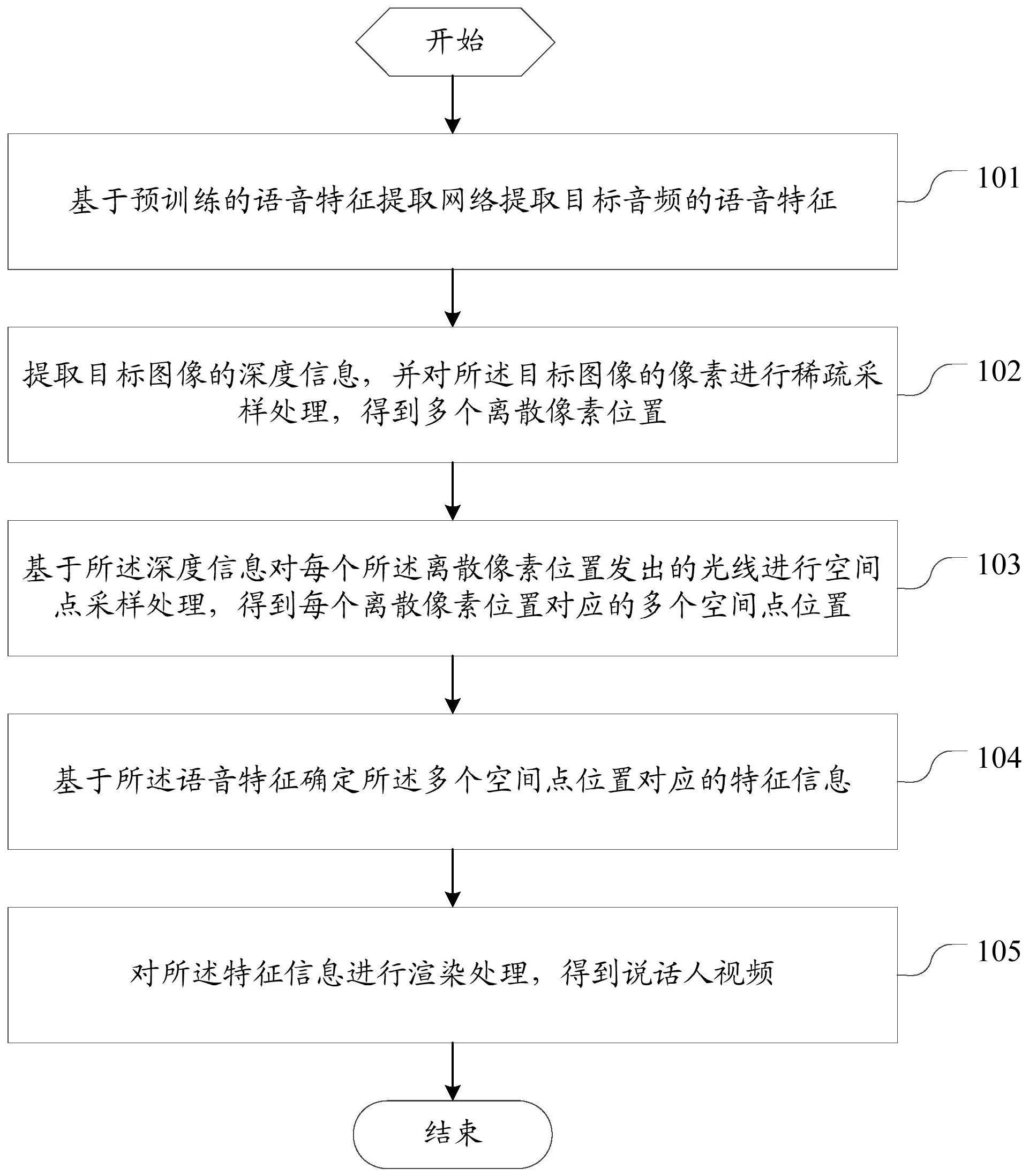
3、第一方面,本发明实施例提供了一种说话人视频生成方法,所述方法包括:
4、基于预训练的语音特征提取网络提取目标音频的语音特征;
5、提取目标图像的深度信息,并对所述目标图像的像素进行稀疏采样处理,得到多个离散像素位置;
6、基于所述深度信息对每个所述离散像素位置发出的光线进行空间点采样处理,得到每个离散像素位置对应的多个空间点位置;
7、基于所述语音特征确定所述多个空间点位置对应的特征信息;
8、对所述特征信息进行渲染处理,得到说话人视频。
9、可选地,所述基于预训练的语音特征提取网络提取目标音频的语音特征之前,所述方法还包括:
10、通过语音特征提取网络提取训练样本的语音特征;
11、通过图像特征提取网络提取所述训练样本的图像特征;
12、确定所述训练样本的语音特征和所述训练样本的图像特征的对比损失值;
13、基于所述对比损失值对所述语音特征提取网络进行训练,得到预训练的语音特征提取网络。
14、可选地,所述预训练的语音特征提取网络通过以对齐音频和图像的口型为训练目标进行训练获得。
15、可选地,所述基于所述深度信息对每个所述离散像素位置发出的光线进行空间点采样处理,得到每个离散像素位置对应的多个空间点位置包括:
16、在所述深度信息指示的深度范围内,对每个所述离散像素位置发出的光线进行均匀3d空间点采样处理,得到每个离散像素位置对应的多个空间点位置。
17、可选地,所述基于所述语音特征确定所述多个空间点位置对应的特征信息,包括:
18、将所述语音特征及所述每个离散像素位置对应的多个空间点位置输入全连接神经网络mlp进行计算,得到所述每个离散像素位置对应的多维特征值及体密度;
19、其中,所述特征信息包括所述多维特征值及体密度。
20、可选地,所述对所述特征信息进行渲染处理,得到说话人视频,包括:
21、对所述每个离散像素位置对应的多维特征值及体密度进行体渲染处理,得到目标特征图;
22、采用卷积神经网络cnn优化网络对所述目标特征图进行特征上采样处理,得到说话人视频。
23、可选地,所述对所述每个离散像素位置对应的多维特征值及体密度进行体渲染处理,得到目标特征图,包括:
24、对所述每个离散像素位置对应的多维特征值按照所述体密度进行加权处理,得到所述每个离散像素位置对应的特征向量;
25、其中,所述目标特征图为由所述多个离散像素位置对应的特征向量形成的特征图。
26、第二方面,本发明实施例提供了一种说话人视频生成装置,所述装置包括:
27、第一提取模块,用于基于预训练的语音特征提取网络提取目标音频的语音特征;
28、第二提取模块,用于提取目标图像的深度信息,并对所述目标图像的像素进行稀疏采样处理,得到多个离散像素位置;
29、第一处理模块,用于基于所述深度信息对每个所述离散像素位置发出的光线进行空间点采样处理,得到每个离散像素位置对应的多个空间点位置;
30、第一确定模块,用于基于所述语音特征确定所述多个空间点位置对应的特征信息;
31、第二处理模块,用于对所述特征信息进行渲染处理,得到说话人视频。
32、可选地,所述装置还包括:
33、第三提取模块,用于通过语音特征提取网络提取训练样本的语音特征;
34、第四提取模块,用于通过图像特征提取网络提取所述训练样本的图像特征;
35、第二确定模块,用于确定所述训练样本的语音特征和所述训练样本的图像特征的对比损失值;
36、训练模块,用于基于所述对比损失值对所述语音特征提取网络进行训练,得到预训练的语音特征提取网络。
37、可选地,所述预训练的语音特征提取网络通过以对齐音频和图像的口型为训练目标进行训练获得。
38、可选地,所述第一处理模块具体用于:
39、在所述深度信息指示的深度范围内,对每个所述离散像素位置发出的光线进行均匀3d空间点采样处理,得到每个离散像素位置对应的多个空间点位置。
40、可选地,所述第一确定模块具体用于:
41、将所述语音特征及所述每个离散像素位置对应的多个空间点位置输入全连接神经网络mlp进行计算,得到所述每个离散像素位置对应的多维特征值及体密度;
42、其中,所述特征信息包括所述多维特征值及体密度。
43、可选地,所述第二处理模块包括:
44、第一处理单元,用于对所述每个离散像素位置对应的多维特征值及体密度进行体渲染处理,得到目标特征图;
45、第二处理单元,用于采用卷积神经网络cnn优化网络对所述目标特征图进行特征上采样处理,得到说话人视频。
46、可选地,所述第一处理单元具体用于:
47、对所述每个离散像素位置对应的多维特征值按照所述体密度进行加权处理,得到所述每个离散像素位置对应的特征向量;
48、其中,所述目标特征图为由所述多个离散像素位置对应的特征向量形成的特征图。
49、第三方面,本发明实施例提供一种电子设备,包括:处理器、存储器及存储在所述存储器上并可在所述处理器上运行的程序,所述程序被所述处理器执行时实现第一方面所述的说话人视频生成方法的步骤。
50、第四方面,本发明实施例提供一种计算机可读存储介质,所述计算机可读存储介质上存储有计算机程序,所述计算机程序被处理器执行时实现第一方面所述的说话人视频生成方法的步骤。
51、在本发明实施例中,基于预训练的语音特征提取网络提取目标音频的语音特征;提取目标图像的深度信息,并对所述目标图像的像素进行稀疏采样处理,得到多个离散像素位置;基于所述深度信息对每个所述离散像素位置发出的光线进行空间点采样处理,得到每个离散像素位置对应的多个空间点位置;基于所述语音特征确定所述多个空间点位置对应的特征信息;对所述特征信息进行渲染处理,得到说话人视频。这样,通过对所述目标图像的像素进行稀疏采样处理,在显著减少算法运行时间的同时能够避免信息过度损失,能够提高说话人视频的生成速度。
技术特征:
1.一种说话人视频生成方法,其特征在于,所述方法包括:
2.根据权利要求1所述的方法,其特征在于,所述基于预训练的语音特征提取网络提取目标音频的语音特征之前,所述方法还包括:
3.根据权利要求1所述的方法,其特征在于,所述预训练的语音特征提取网络通过以对齐音频和图像的口型为训练目标进行训练获得。
4.根据权利要求1所述的方法,其特征在于,所述基于所述深度信息对每个所述离散像素位置发出的光线进行空间点采样处理,得到每个离散像素位置对应的多个空间点位置,包括:
5.根据权利要求1所述的方法,其特征在于,所述基于所述语音特征确定所述多个空间点位置对应的特征信息,包括:
6.根据权利要求5所述的方法,其特征在于,所述对所述特征信息进行渲染处理,得到说话人视频,包括:
7.根据权利要求6所述的方法,其特征在于,所述对所述每个离散像素位置对应的多维特征值及体密度进行体渲染处理,得到目标特征图,包括:
8.一种说话人视频生成装置,其特征在于,所述装置包括:
9.一种电子设备,其特征在于,包括:处理器、存储器及存储在所述存储器上并可在所述处理器上运行的程序,所述程序被所述处理器执行时实现如权利要求1至7中任一项所述的说话人视频生成方法的步骤。
10.一种计算机可读存储介质,其特征在于,所述计算机可读存储介质上存储有计算机程序,所述计算机程序被处理器执行时实现如权利要求1至7中任一项所述的说话人视频生成方法的步骤。
技术总结
本发明提供一种说话人视频生成方法、装置及电子设备,涉及人工智能技术领域,其中,所述方法包括:基于预训练的语音特征提取网络提取目标音频的语音特征;提取目标图像的深度信息,并对所述目标图像的像素进行稀疏采样处理,得到多个离散像素位置;基于所述深度信息对每个所述离散像素位置发出的光线进行空间点采样处理,得到每个离散像素位置对应的多个空间点位置;基于所述语音特征确定所述多个空间点位置对应的特征信息;对所述特征信息进行渲染处理,得到说话人视频。本发明实施例能够提高说话人视频的生成速度。
技术研发人员:叶晓倩,王千,杜瞻,闫敏,柳欣,冯俊兰,邓超
受保护的技术使用者:中国移动通信有限公司研究院
技术研发日:
技术公布日:2024/1/15
- 还没有人留言评论。精彩留言会获得点赞!