一种基于大数据的云计算任务执行时间预测方法
本发明属于云计算中的数据挖掘领域,具体涉及一种基于大数据的云计算任务执行时间预测方法。
背景技术:
1、随着互联网技术的不断发展,对云计算平台的需求逐渐增加,基于云计算平台的应用及算法也越来越重要,例如云计算的快速创新与应用,云平台中的云资源调度、负载均衡等任务。其中,云资源调度的第一步就是为每个任务都分配合适的机器与合理的使用时间,这样可以提高资源的利用效率;
2、而计算任务的完成时间是云资源调度等任务的基础。在实际云数据中心环境下,工作流执行日志数据包含了大量的任务执行时间数据及其相关影响因素数据,在数据驱动的任务执行时间预测中发挥着重要作用。如何使用这些数据来准确预测任务执行时间,是云计算领域的一项重要任务。
3、为了解决这个问题,云计算领域的研究人员已经提出了许多不同的方法和技术,例如基于历史数据的时序预测方法和基于任务数据的机器学习预测方法。但由于云计算环境的复杂性和不确定性,这些方法仍然不能较好的完成预测任务。
技术实现思路
1、为解决上述问题,本发明提供了一种基于大数据的云计算任务执行时间预测方法,该方法构建并训练任务执行时间预测模型;将当前任务的影响因素数据输入训练好的任务执行时间预测模型,输出当前任务的预测执行时间;所述任务执行时间预测模型包括相关性注意力模块、多级特征筛选模块、特征融合模块和预测模块;
2、所述任务执行时间预测模型的训练过程,包括以下步骤:
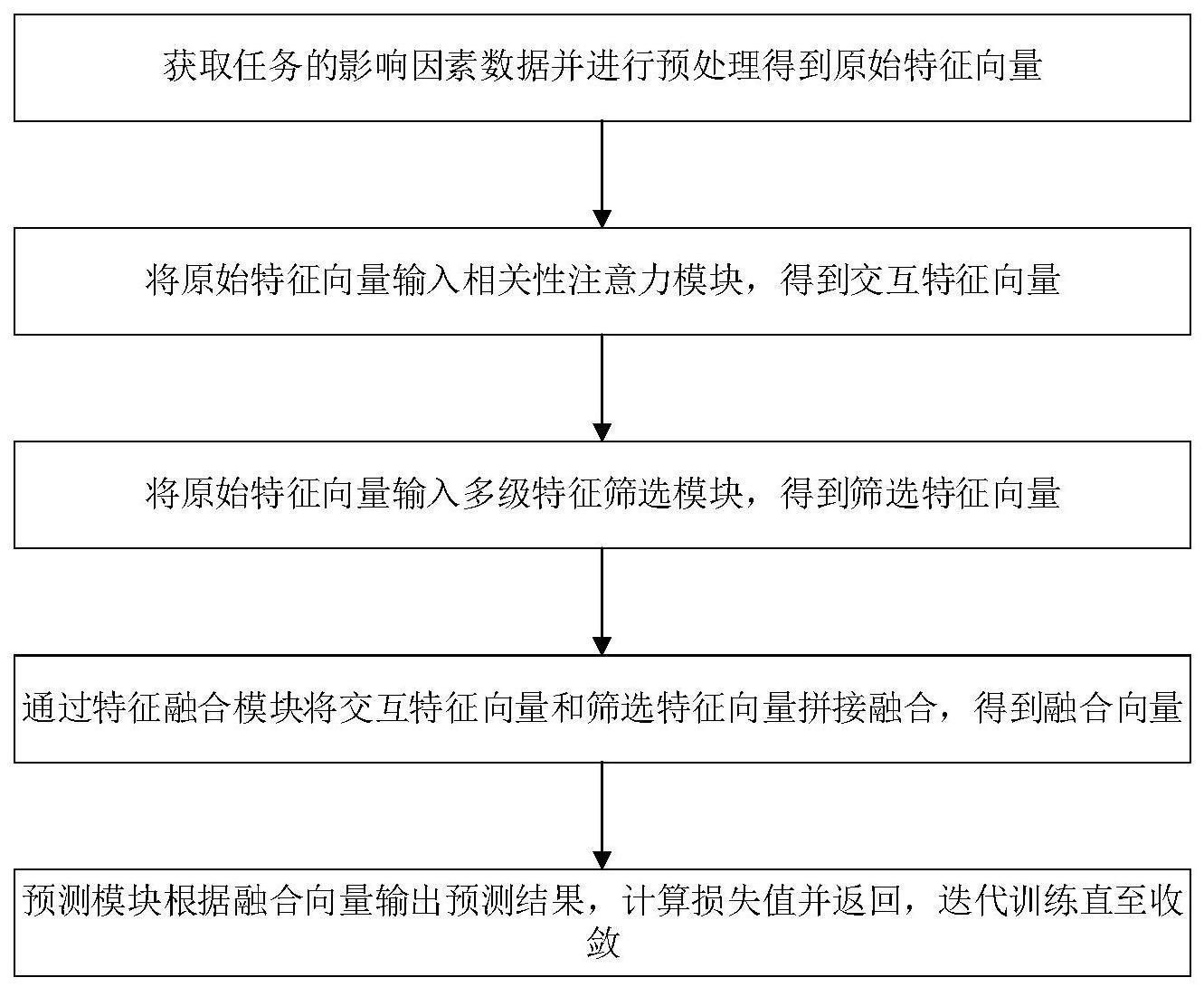
3、s1.获取任务的影响因素数据并进行预处理得到原始特征向量;
4、s2.将原始特征向量输入相关性注意力模块,得到交互特征向量;
5、s3.将原始特征向量输入多级特征筛选模块,得到筛选特征向量;
6、s4.通过特征融合模块将交互特征向量和筛选特征向量拼接融合,得到融合向量;
7、s5.预测模块根据融合向量输出预测结果,计算损失值并返回,迭代训练直至收敛。
8、进一步的,所述任务的影响因素数据包括离散数据和连续数据,步骤s1对影响因素数据并进行预处理得到原始特征,包括:
9、s11.在影响因素数据的离散数据中提取离散特征并编码,得到编码离散特征;
10、s12.在影响因素数据的连续数据中提取连续特征并归一化,得到归一化连续特征;
11、s13.将编码离散特征与归一化连续特征合并,得到原始特征向量。
12、进一步的,步骤s2将原始特征向量输入相关性注意力模块,得到交互特征向量,包括:
13、s21.通过embedding层将原始特征向量映射到高维空间得到初始特征向量;
14、s22.采用query线性矩阵和key线性矩阵分别与初始特征向量点积,得到对应的query向量和key向量,将query向量和key向量交互得到一个权重矩阵;
15、s23.执行3次步骤s22的过程,得到w1、w2、w3共3个权重矩阵;
16、s24.设置可学习阈值参数,将权重矩阵w1中小于可学习阈值参数的元素都置为0,得到高相关性特征权重矩阵并采用位置矩阵p1记录高相关性特征权重矩阵中的非零元素的位置;将权重矩阵w2中大于等于可学习阈值参数的元素都置为0,得到低相关性特征权重矩阵并采用位置矩阵p2记录低相关性特征权重矩阵中的非零元素的位置;
17、s25.权重矩阵w3分别与高相关性特征权重矩阵低相关性特征权重矩阵进行融合平均,得到融合高相关性特征权重矩阵wh、融合低相关性特征权重矩阵wl;
18、s26.采用value线性矩阵与初始特征向量点积得到value向量ev,将value向量分别与融合高相关性特征权重矩阵wh、融合低相关性特征权重矩阵wl进行乘法计算,得到高相关性特征注意力向量eh和低相关性特征注意力向量el;
19、s27.将高相关性特征注意力向量eh和低相关性特征注意力向量el融合得到交互特征向量ef。
20、进一步的,步骤s26计算高相关性特征注意力向量eh和低相关性特征注意力向量el的公式为:
21、
22、
23、其中,表示softmax激活函数,⊙表示矩阵逐位相乘,t表示特征向量的维度大小。
24、进一步的,步骤s27将高相关性特征注意力向量eh和低相关性特征注意力向量el融合得到交互特征向量ef,表示为:
25、
26、其中,fx、fy为线性层,w1、w2为可学习权重参数。
27、进一步的,步骤s3将原始特征输入多级特征筛选模块,得到筛选特征向量,包括:
28、s31.通过embedding层将原始特征向量映射到高维空间得到初始特征向量;
29、s32.将原始特征向量通过带有sigmoid激活函数的1×1门控线性层,得到候选状态向量e1;将初始特征向量通过带有tanh激活函数的t×t门控线性层,得到候选状态向量e2;
30、s33.将候选状态向量e1与候选状态向量e2进行点积得到交互多级特征向量eu1;
31、s34.将候选状态向量e1在最后一个维度进行复制,使其与候选状态向量e2的维度大小相同,得到扩张候选状态向量e11;
32、s35.将候选状态向量e2通过带有sigmoid激活函数的线性映射层后与扩张候选状态向量e11逐位相乘,得到过滤多级特征向量eu2;
33、s36.通过可学习权重u1、u2融合交互多级特征向量eu1和过滤多级特征向量eu2,得到筛选特征向量。
34、进一步的,计算筛选特征向量的公式为:
35、e1=σ(k1e1+b1)
36、e2=f(k2e2+b2)
37、eu=u1*e1we2+u2*σ(e2)⊙e11
38、其中,σ表示sigmoid激活函数,f表示tanh激活函数,w表示可学习的参数矩阵。
39、本发明的有益效果:
40、本发明采用的方法中,通过相关性注意力机制,挖掘特征之间的相互作用,并自动根据基础特征进行特征交互,自动地提取出更有效的高阶特征;通过基于门控模块的多级特征筛选方法,对于低维的基础特征和高维的向量特征,通过门控模块进行权重计算,并将多种特征进行融合,更加合理的分配各类特征的重要性。通过以上两种方法,大大提高了模型在预测阶段的鲁棒性和准确性。
技术特征:
1.一种基于大数据的云计算任务执行时间预测方法,其特征在于,构建并训练任务执行时间预测模型;将当前任务的影响因素数据输入训练好的任务执行时间预测模型,输出当前任务的预测执行时间;所述任务执行时间预测模型包括相关性注意力模块、多级特征筛选模块、特征融合模块和预测模块;
2.根据权利要求1所述的一种基于大数据的云计算任务执行时间预测方法,其特征在于,所述任务的影响因素数据包括离散数据和连续数据,步骤s1对影响因素数据并进行预处理得到原始特征,包括:
3.根据权利要求1所述的一种基于大数据的云计算任务执行时间预测方法,其特征在于,步骤s2将原始特征向量输入相关性注意力模块,得到交互特征向量,包括:
4.根据权利要求3所述的一种基于大数据的云计算任务执行时间预测方法,其特征在于,步骤s26计算高相关性特征注意力向量eh和低相关性特征注意力向量el的公式为:
5.根据权利要求3所述的一种基于大数据的云计算任务执行时间预测方法,其特征在于,步骤s27将高相关性特征注意力向量eh和低相关性特征注意力向量el融合得到交互特征向量ef,表示为:
6.根据权利要求1所述的一种基于大数据的云计算任务执行时间预测方法,其特征在于,步骤s3将原始特征输入多级特征筛选模块,得到筛选特征向量,包括:
7.根据权利要求6所述的一种基于大数据的云计算任务执行时间预测方法,其特征在于,计算筛选特征向量的公式为:
8.根据权利要求1所述的一种基于大数据的云计算任务执行时间预测方法,其特征在于,步骤s4包括:将交互特征向量ef和筛选特征向量eu分别通过一个带有sigmoid激活函数的线性层,得到向量和向量将向量和向量逐元素相乘得到融合向量em,表示为:
技术总结
本发明属于云计算中的数据挖掘领域,具体涉及一种基于大数据的云计算任务执行时间预测方法;该方法构建并训练任务执行时间预测模型;将当前任务的影响因素数据输入训练好的任务执行时间预测模型,输出当前任务的预测执行时间;所述任务执行时间预测模型包括相关性注意力模块、多级特征筛选模块、特征融合模块和预测模块;本发明提高了模型在预测阶段的鲁棒性和准确性。
技术研发人员:王进,周继聪,母雪豪
受保护的技术使用者:重庆邮电大学
技术研发日:
技术公布日:2024/1/14
- 还没有人留言评论。精彩留言会获得点赞!