一种生成式多模态互利增强视频语义通信方法
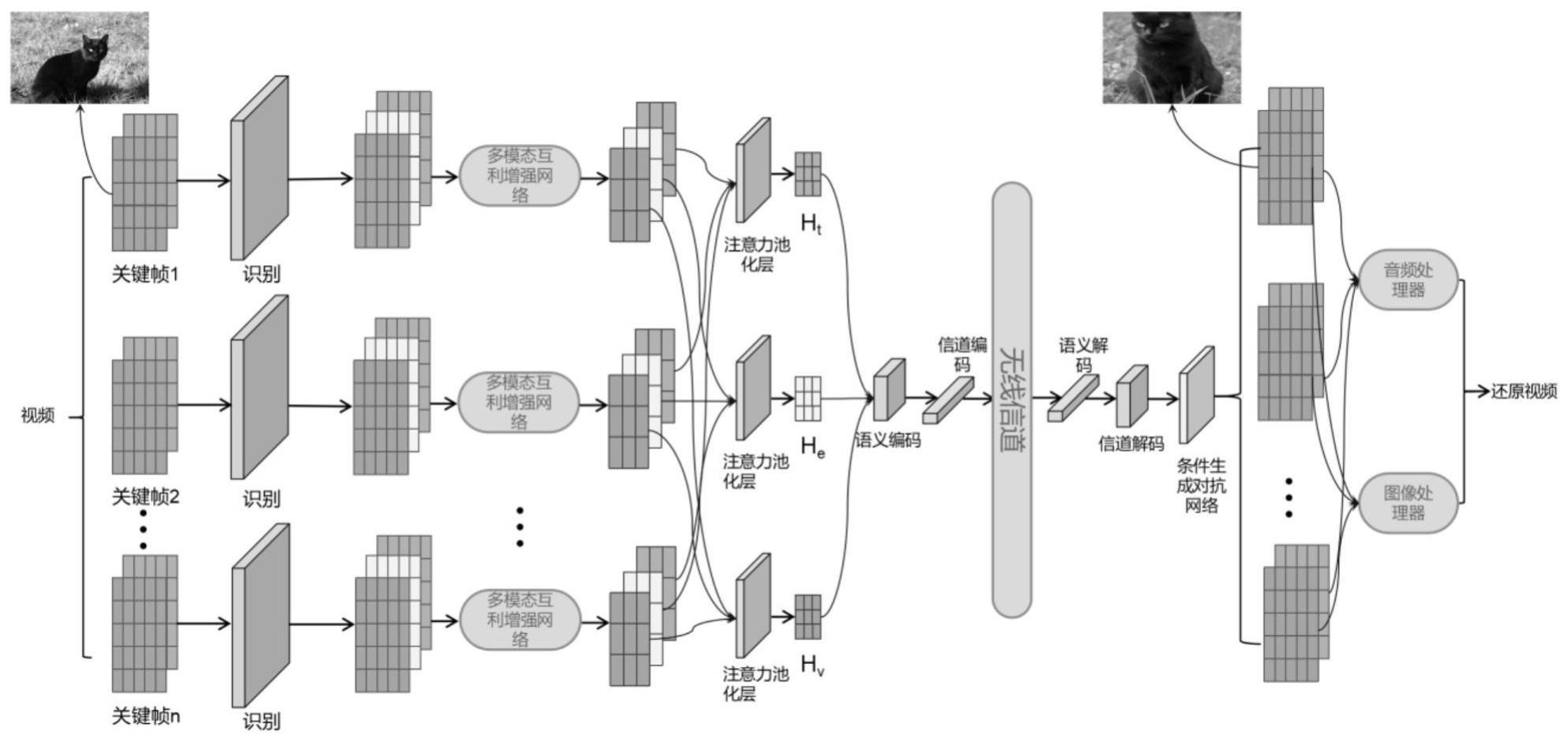
本发明涉及一种生成式多模态互利增强视频语义通信方法,属于人工智能与无线通信技术交叉领域。
背景技术:
1、在过去30年里,无线通信经历了快速发展,第六代(6g)无线通信技术的研究更受到广泛关注。然而,随着通信流量迅速增长,频谱资源愈发稀缺。频谱资源是无线通信的重要资源,作为社会主要信息传输手段之一,视频通信对频谱资源的利用尤为关键。为了满足不断增长的视频通信需求,必须对现有的通信范式和通信技术进行改进以满足更高效的频谱利用。语义通信作为一种新式的智能化通信方式,通过关注传输信息的语义,在减少网络流量和提高频谱效率上展现出巨大潜力。现阶段,深度强化学习受到工业界和学术界的广泛关注,归因于其能够解决大规模复杂问题并实时发现最优解决方法,而语义通信以深度学习基础,其工作主要集中对信息的特征提取和特征恢复,以实现对模态语义信息的传输并完成下游语义任务。h.xie,z.qin等人在“deep learning enabled semanticcommunication systems”(ieee transactions on signal processing)中提出了一种基于深度学习的文本语义通信系统deepsc。通过利用深度学习的特征提取和恢复能力,提取出文本语义信息并只对语义信息进行传输。与传统通信相比,该方法可以很大程度上提高频谱效率。此外,h.zhang等人在“deep learning-enabled semantic communicationsystems with task-unaware transmitter and dynamic data”中提出一种基于神经网络的图像语义通信系统,采用动态训练过程进行迁移学习,能够实现图像语义特征的准确提取与传输。
2、然而,现阶段语义通信传输架构主要集中在对单模态信息的建模处理,对于以视频为代表的多模态传输任务的研究仍相对不足。多模态传输涉及到图像、音频、文本等多种信息的同时传输和处理,其复杂性和挑战性更高。在多模态视频通信领域的研究中,一项关键任务是实现跨模态的信息融合和语义理解。传统方法主要依赖于手工设计的特征提取与模态间对齐,但其存在一定的局限性。b.xin,j.huang等人在“interpretation on deepmultimodal fusion for diagnostic classification”中提出了一种基于深度典型相关分析(cca)的可解释深度多模态融合(dmfusion)框架。dmfusion框架利用cca(canonicalcorrelation analysis)损失来建模模态间的相关性,并通过重构损失和交叉熵损失在低维潜在融合空间中优化多模态信息,有效地结合了模态内部的结构和判别信息。类似地,h.wu等人在“channel-adaptive wireless image transmission with ofdm”提出了一种多模态注意力网络,通过捕捉视觉和文本模态之间的交互来实现更准确的图像字幕生成。然而这些方法仅是对多模态视频通信的初步探索,如何有效地处理多模态数据的异质性和动态性以及如何在多模态传输中实现实时性和带宽效率的平衡等问题仍待解决。此外,多模态信息处理如何与语义通信相结合,实现高效而精准的视频传输也是仍需探索的问题。
技术实现思路
1、本发明目的在于针对语义通信场景下多模态信息难以融合以及综合利用率低的问题,提出了一种多模态互利增强的视频语义通信方法,该方法基于条件生成对抗网络(cgan),实现高效精准传输的视频通信,可以完成对简单场景视频的高效准确语义通信,显著提升视频通信系统的频谱效率,同时在复杂低信噪比环境下能保持较高的鲁棒性。
2、本发明解决其技术问题所采用的技术方案是:一种生成式多模态互利增强视频语义通信方法,该方法包括如下步骤:
3、步骤1:发送端视频片段语义信息提取;
4、步骤1-1:视频关键帧判别选择;
5、步骤1-2:关键帧图像音频模态信息提取文本语义信息;
6、步骤2:建立多模态互利增强网络模型;
7、步骤2-1:输入单帧图像文本音频信息并分别编码;
8、步骤2-2:设计语义差分处理,文本模态以预训练cgan为基础生成图像音频;
9、步骤2-3:进行语义信息差分处理;
10、步骤3:建立通信编解码模块:
11、步骤3-1:建立语义通信编解码模块,设定语义网络集合引入语义相似度其中b(·)代表了基于转换器的句子-双向编码器(bert)的预训练模型,语义相似度ξ是一个在0和1之间的连续值,s代表了传输原句,代表了接收端恢复语句,(·)t代表转置;
12、步骤3-2:建立语义编解码模块;
13、步骤3-3:建立信道编解码模块;
14、步骤4:接收端视频恢复;
15、步骤4-1:接收端基于条件生成对抗网络cgan实现文本语义及辅助信息图像音频还原;
16、步骤4-2:多帧信息匹配性纠错,确保信息的一致性和逻辑性,最终恢复出完整的视频。
17、有益效果:
18、1、本发明提出了一种新颖的多模态互利增强视频语义通信模型(mme-sc),该模型旨在解决现有方法在多模态视频通信中存在的局限性,并为不同模态之间的语义信息精准提取提供了有效的解决方案。具体来说,本发明构建了整体的视频语义通信框架,在收发端实现对视频关键帧语义信息的优化处理,同时提出了以文本为主要传输信息,图像音频残差为辅助信息的语义通信模块,实现了端到端的视频语义通信,仿真结果表明,本发明的方法实现了以较小的传输量完成简单场景视频的传输任务。
19、2、本发明设计了一个多模态互利增强网络,通过综合利用生成对抗网络和信息差分机制,该模型实现了多模态数据之间的互补和错误纠正,从而优化了视频语义信息的提取过程。具体来说,本发明采用条件生成对抗网络(cgan)架构,以增强模型对不同模态数据之间的互补性。通过生成器和判别器之间的对抗训练,模型能够从不同模态数据中学习到更加丰富和一致的语义信息。其次,引入信息差分机制,以实现模态间的错误纠正和补偿。通过对比不同模态数据之间的信息差异,并将差异信息引入模型训练,多模态互利增强网络能够自动学习各个模态之间的补偿关系,从而实现多模态语义的精准提取。
20、3、本发明提出了多帧语义信息的连续性检验方法,通过在接收端对关键帧语义信息的联合分配控制,可以实现视频的高质量还原。该方法通过在接收端对关键帧语义信息进行联合分配控制,根据多模态信息的特征和语义内容以及关键帧之间的语义相关性和时序关系,确保视频中每个关键帧之间的语义信息连续性,实现关键帧的平滑过渡,从而实现视频的高质量还原。
技术特征:
1.一种生成式多模态互利增强视频语义通信方法,其特征在于,所述方法包括如下步骤:
2.根据权利要求1所述的一种生成式多模态互利增强视频语义通信方法,其特征在于,所述步骤1-1包括:在发送端,首先通过提取关键帧来处理视频片段,为了促进多模态信息的互补增强,确保在一定时间域内模态信息的时序一致性是至关重要的,在该模型中,通过评估交叉相关系数来确定选择的视频关键帧范围,交叉相关系数衡量了两个图像fi和fj之间的相似性,能够计算为:
3.根据权利要求1所述的一种生成式多模态互利增强视频语义通信方法,其特征在于,所述步骤1-2包括:在发送端从每个选定的关键帧中提取和处理图像和音频数据的语义信息,具体而言,分别使用visual geometry group(vgg)和transformer架构来实现图像和音频处理,并使用训练实现目标识别,由于图像和音频模态中目标检测算法依赖于不同的数据库,两种模态之间的检测结果不可避免地不完全相同,并且相同目标的置信水平也可能有所不同,因此,为了全面提取视频关键帧的语义信息,设置了超参数,在目标对象的文本语义中进行权衡,并最终输出检测结果,在这种情况下,将从每个帧模态提取的文本语义目标表示为oi,利用bert语料库,将文本谓词结合起来构建完整的描述性文本表示,表示为ei=[o1,o2,...,on],然后,将关键帧文本组合成一个文本序列,表示为e=[e1,e2,...,en]。
4.根据权利要求1所述的一种生成式多模态互利增强视频语义通信方法,其特征在于,所述步骤2包括:设计了一个多模态互利增强增强网络,消除了多模态信息中的冗余,并增强了模态之间的互补性,网络由三个模块组成:编码器、条件生成对抗网络(cgan)和信息差异处理模块;
5.根据权利要求1所述的一种生成式多模态互利增强视频语义通信方法,其特征在于,所述步骤3包括:建立通信编解码模块,发送端由语义编码器和信道编码器组成,接收端由语义解码器和信道解码器组成,其中物理信道模拟了真实的传输情况,在接收端,接收到的信号通过信道解码和语义解码进行恢复,以获得目标文本,在发送端,传输文本能够表示为s=[s1,s2,...,si,...,sl],其中l是句子长度,si表示句子中的第i个词,句子s依次经过语义编码器、信道编码器、模拟信道、信道解码器、语义编码器进行传输,由deepsc网络组成的语义通信网络集合能够表示为每个deepsc网络具有不同数量的语义符号输出。
6.根据权利要求1所述的一种生成式多模态互利增强视频语义通信方法,其特征在于,所述步骤4包括:接收端视频恢复,采用了多帧语义检测机制,涉及对象检测和跟踪算法,以识别视频中的语义对象并提取它们的位置和运动信息,具体而言,使用cgan网络生成与关键帧语义文本对应的图像和音频,共计t帧,表示为it,其中t表示帧索引,通过对象检测和跟踪算法,获得每帧的目标位置和边界框信息,表示为bt;
技术总结
本发明公开了一种生成式多模态互利增强视频语义通信方法,称为MME‑SC。该方法建立在条件生成对抗网络(CGAN)的基础上,旨在使用文本作为主要传输载体,利用不同模态之间的互利增强来实现目标语义信息的精准提取,从而完成视频传输任务。在多模态互利增强网络的帮助下,我们从视频的关键帧图像和音频中提取语义信息,并进行差值处理,以确保提取的文本以更少的比特传达准确的语义信息,从而提高系统的容量。此外,本发明设计了一个多帧语义检测模块,以督促视频生成过程中的语义过渡。仿真结果表明,本发明出的框架在复杂噪声环境中对视频的传输具有较高的鲁棒性,特别是在低信噪比条件下,显著提高了视频通信中语义传输的准确性和符号传输速率。
技术研发人员:吴伟,陈元乐,刘纯玉,熊师洵,周福辉,吴启晖
受保护的技术使用者:南京邮电大学
技术研发日:
技术公布日:2024/1/15
- 还没有人留言评论。精彩留言会获得点赞!