视频生成方法、装置、设备、介质及程序产品与流程
本公开涉及计算机,尤其涉及一种视频生成方法、装置、设备、介质及程序产品。
背景技术:
1、基于多模态的视频生成技术(multi-modal-to-video generation)可以通过文字、语音等其他模态的数据来指导视频的生成。然而,现有的多模态视频生成技术中针对不同模态之间的匹配准确度不高,导致视频生成的准确性不高,降低了用户体验。
技术实现思路
1、本公开提出一种视频生成方法、装置、设备、存储介质及程序产品,以在一定程度上解决视频生成的准确性不高的技术问题。
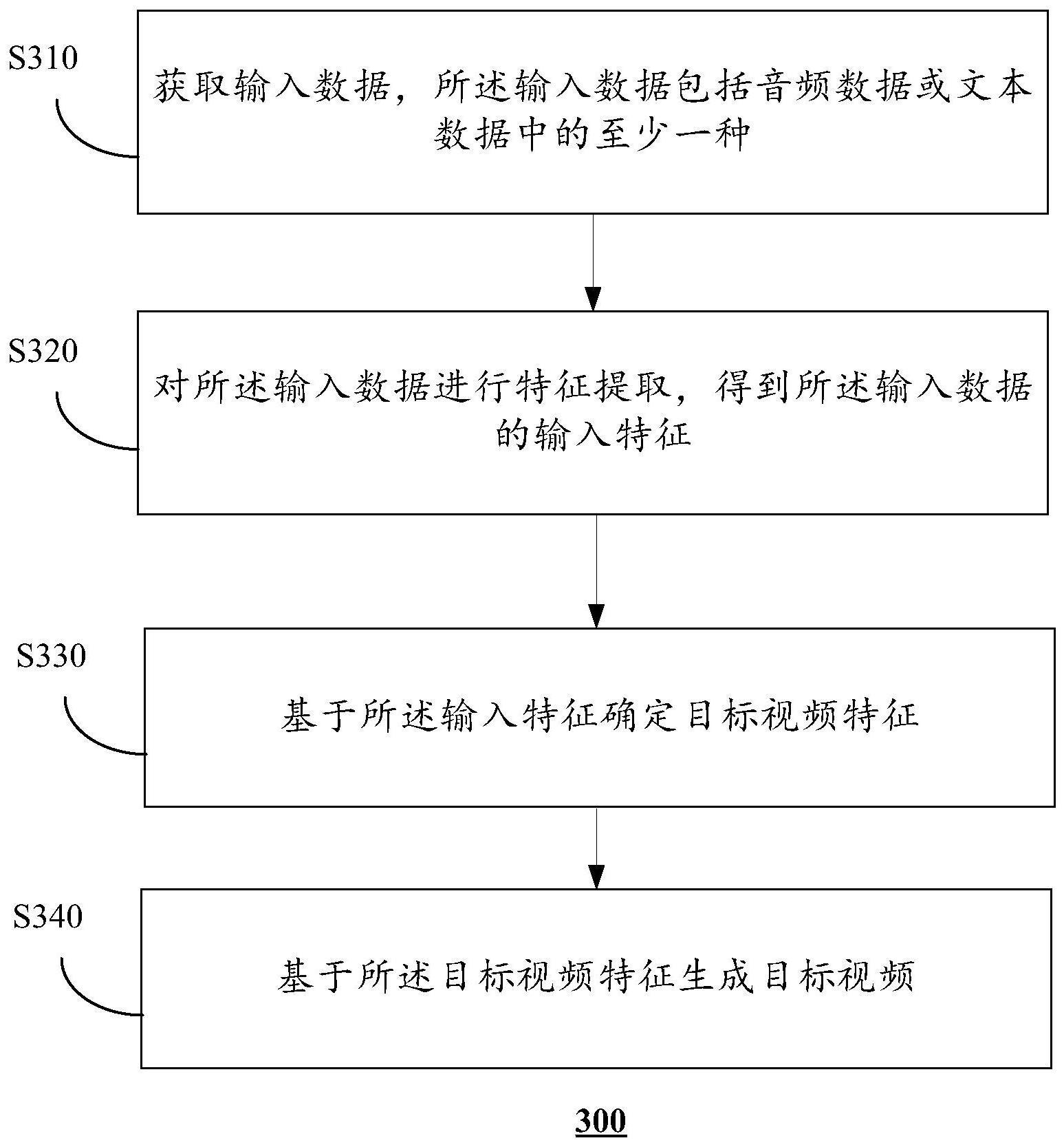
2、本公开第一方面,提供了一种视频生成方法,包括:
3、获取输入数据,所述输入数据包括音频数据或文本数据中的至少一种;
4、对所述输入数据进行特征提取,得到所述输入数据的输入特征;
5、基于所述输入特征确定目标视频特征;
6、基于所述目标视频特征生成目标视频。
7、本公开第二方面,提供了一种视频生成装置,包括:
8、获取模块,用于获取输入数据,所述输入数据包括音频数据或文本数据;
9、提取模块,用于对所述输入数据进行特征提取,得到所述输入数据的输入特征;
10、匹配模块,用于基于所述输入特征确定目标视频特征;
11、生成模块,用于基于所述目标视频特征生成目标视频。
12、本公开第三方面,提供了一种电子设备,其特征在于,包括一个或者多个处理器、存储器;和一个或多个程序,其中所述一个或多个程序被存储在所述存储器中,并且被所述一个或多个处理器执行,所述程序包括用于执行根据第一方面或第二方面所述的方法的指令。
13、本公开第四方面,提供了一种包含计算机程序的非易失性计算机可读存储介质,当所述计算机程序被一个或多个处理器执行时,使得所述处理器执行第一方面或第二方面所述的方法。
14、本公开第五方面,提供了一种计算机程序产品,包括计算机程序指令,当所述计算机程序指令在计算机上运行时,使得计算机执行第一方面所述的方法。
15、从上面所述可以看出,本公开提供的一种视频生成方法、装置、设备、介质及程序产品,通过基于输入数据的输入特征确定对应的目标视频特征,从而生成目标视频。无论输入数据是何种模态均可以实现与视频特征的匹配,准确地生成目标视频,提高了视频生成的准确性。
技术特征:
1.一种视频生成方法,包括:
2.根据权利要求1的方法,其中,对所述输入数据进行特征提取,得到所述输入数据的输入特征,包括:
3.根据权利要求1的方法,其中,所述基于所述输入特征确定目标视频特征,包括:
4.根据权利要求1的方法,其中,基于所述目标视频特征生成目标视频,包括:
5.根据权利要求4的方法,其中,所述输入数据包括至少一个单语义数据;
6.根据权利要求5的方法,其中,基于所述目标时长和所述源时长进行所述目标时间戳与所述源时间戳的对齐,得到对齐后的目标视频切片,包括:
7.根据权利要求1的方法,其中,所述输入数据还包括用于指示目标视频的属性的指示信息;
8.根据权利要求1的方法,其中,所述输入数据为文本数据,所述方法还包括:基于预设播放速度设置所述文本数据的源时间戳。
9.一种视频生成装置,包括:
10.一种电子设备,包括存储器、处理器及存储在存储器上并可在处理器上运行的计算机程序,所述处理器执行所述程序时实现如权利要求1至8任意一项所述的方法。
11.一种非暂态计算机可读存储介质,所述非暂态计算机可读存储介质存储计算机指令,所述计算机指令用于使计算机执行权利要求1至8任一所述方法。
12.一种计算机程序产品,包括计算机程序指令,当所述计算机程序指令在计算机上运行时,使得计算机执行权利要求1至8任一所述的方法。
技术总结
本公开提供一种视频生成方法、装置、设备、存储介质及程序产品。该方法包括:获取输入数据,所述输入数据包括音频数据或文本数据中的至少一种;对所述输入数据进行特征提取,得到所述输入数据的输入特征;基于所述输入特征确定目标视频特征;基于所述目标视频特征生成目标视频。
技术研发人员:张涛
受保护的技术使用者:北京字跳网络技术有限公司
技术研发日:
技术公布日:2024/1/14
- 还没有人留言评论。精彩留言会获得点赞!