一种基于强化学习算法的通信拓扑优化方法
本发明涉及多智能体系统,具体涉及一种基于强化学习算法的通信拓扑优化方法。
背景技术:
1、近年来,越来越多的真实生活场景应用了多智能体系统,例如自动驾驶,传感器网络,飞行器的编队和多机器人合作控制。然而随着多智能体系统与多个领域的关系逐渐密切,用户对多智能体系统的成本和性能有着更高的要求,但是目前多智能体系统的拓扑结构为了保证系统的稳定性,通常会人为选择并固定通信拓扑。这样的行为虽然满足了系统的稳定性要求,但是往往会忽略其他可能工作效果更佳的拓扑结构,从而增加了系统的通信成本和降低系统性能。在多智能体系统中,通信拓扑可以为系统的群协作奠定基础,实现智能体之间的有效信息交互,因此选择一个好的通信拓扑结构对于降低多智能体系统的成本和提高系统的性能具有重要意义。
2、选择更好的通信拓扑首先需要一个统一的评价标准,然而随着多智能体系统的不断发展,如何设计一个统一的评价标准是一个挑战。目前国内外已经有人研究相关问题,研究的成果分别有:通过分析具有有向拓扑和通信延迟的离散多智能体系统的广义共识问题,得到有向连接下通信延迟广义共识的一个充分条件;提出用于跟踪和形成具有时变通信拓扑的多智能体系统的分布式模型预测控制;建立在任意时变通信拓扑和通信时延下多智能体系统的鲁棒稳定性并给出在任意不变通信拓扑和任意时变通信时延下鲁棒稳定性的充要条件。但是这些研究均未考虑通信拓扑对收敛时间和通信成本的影响,因此有必要提出一个评价函数来准确地评价拓扑结构,让系统选择出最优的通信拓扑。
3、基于此,本发明设计了一种基于强化学习算法的通信拓扑优化方法以解决上述问题。
技术实现思路
1、针对现有技术所存在的上述缺点,本发明提供了一种基于强化学习算法的通信拓扑优化方法。
2、为实现以上目的,本发明通过以下技术方案予以实现:
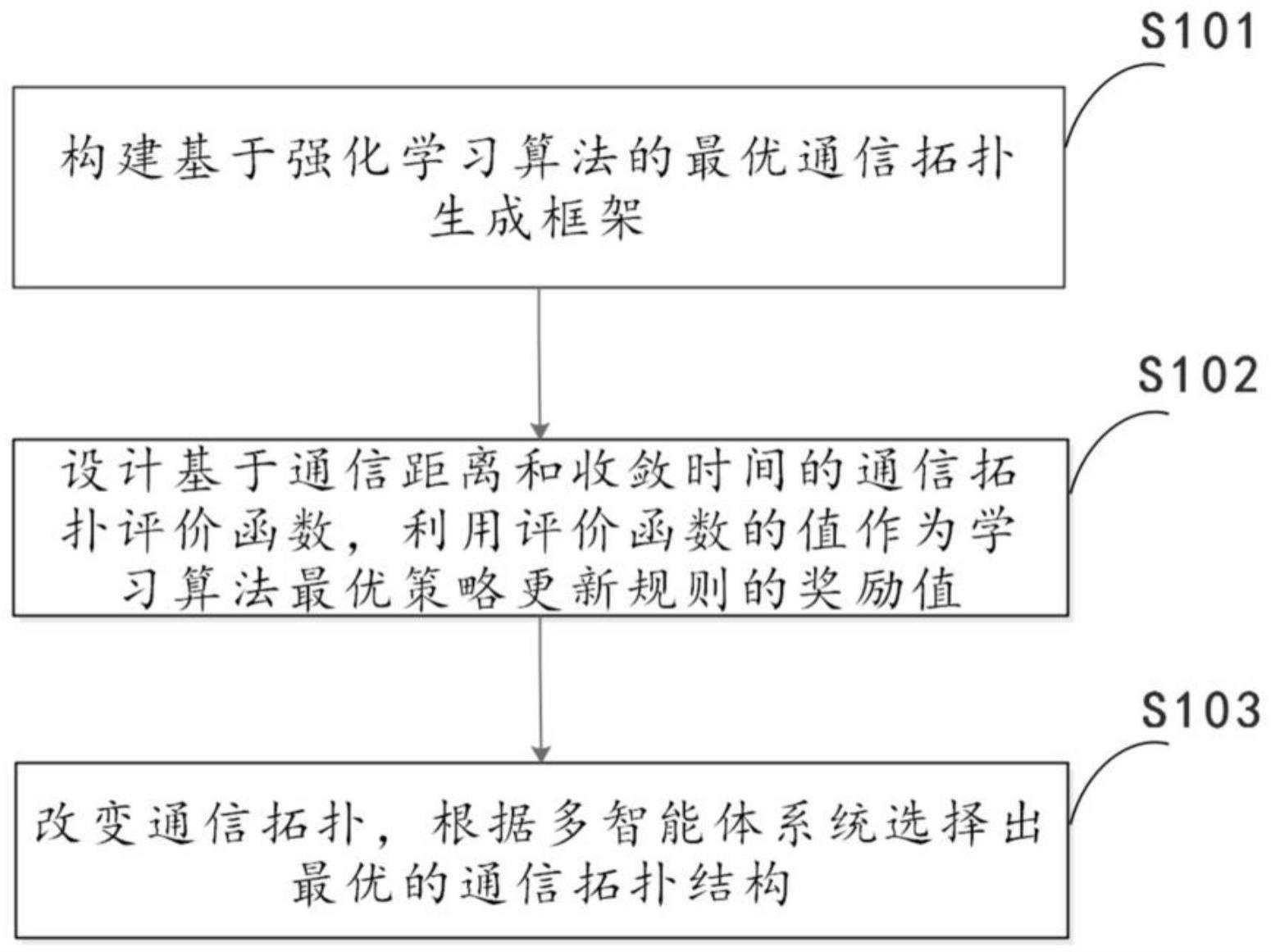
3、一种基于强化学习算法的通信拓扑优化方法,包括以下步骤:
4、s101、构建基于强化学习算法的最优通信拓扑生成框架;
5、s102、设计基于通信距离和收敛时间的通讯拓扑评价函数,利用评价函数的值作为学习最优策略更新规则的奖励值;
6、s103、改变通信拓扑,根据多智能体系统的运行结果选择出最优的通信拓扑结构,保证多智能体系统稳定并提高系统控制器的性能。
7、更进一步的,所述步骤s101具体包括:
8、状态空间:建立状态空间s,为了简化计算复杂度,将n阶多智能体系统的通信拓扑方阵转换为一维长度向量(n*n),以通信拓扑的一维向量作为状态空间;
9、动作空间:根据输出概率最大的位置w选择神经网络,将状态向量w的0变为1;
10、奖励:为保证通信拓扑结构的稳定性,对于包含n个智能体的多智能体系统,将通讯拓扑的边数设置为m=(2n-3);当∑st=m时,将st转换为通讯拓扑a并计算其对应的拉普拉斯矩阵l,设定对角矩阵b表示领导者以及与其通信的跟随者的之间的关系,如果跟随者接收到领导者的信息,对角线元素为1,否则为0;计算rank(l+b),如果rank(l+b)=n,计算相应的距离和时间,回报rt=-f,否则,认为当前状态不满足要求,回报rt=-5;当∑st≠9时,回报rt=-5;
11、策略:π在st情况下生成可行解的概率为其中pθ(πt|π1:t-1,s)是由参数θ参数化的单步分配策略;
12、回报:其中γ表示奖励折扣因子。
13、更进一步的,所述步骤s102具体包括:
14、建立通信拓扑和多智能体系统的连接,新的评价函数为:
15、
16、其中,表示通信拓扑的有向图;x0表示多智能体系统的初始状态;u表示多智能体系统的输入;ρ1,ρ2表示权系数;t表示多智能体系统收敛时间;η表示多智能体系统的总通信距离。
17、更进一步的,当控制律和系统输入已知,初始状态为常数时:
18、
19、其中,表示通信拓扑的有向图;ρ1,ρ2表示权系数;t表示多智能体系统收敛时间;η表示多智能体系统的总通信距离;
20、定义上述的评价函数所生成的结果即适应度值作为学习策略更新规则的奖励值。
21、更进一步的,在计算多智能体系统的收敛时间时,将各智能体在各时间间隔δt上的距离差定义为δj;若距离差δj满足则认为多智能体系统在时刻t收敛。
22、更进一步的,所述步骤s103具体包括以下步骤:
23、步骤一:初始化dqn算法的参数,由于代理不需要与自身交换信息,选择n阶零矩阵作为初始状态并转换为一维向量,使用随机的网络参数ω初始化当前网络q(s,α;ω)和目标网络q(s,α;ω-);初始化评价函数中的权值系数ρ1和ρ2;
24、步骤二:根据当前网络q(s,a;θ)通过ε-greed策略选择动作at,即当产生的随机数小于x∈时,选择概率值最大的动作,否则,随机选择动作;为了防止重复选择动作,采取mask机制,选取的mask=1-s,将当前网络输出的概率和log(mask)合并得到y,计算softmax(y),选择动作,其中s为已经选取的动作集合;
25、步骤三:计算状态向量st的和,当状态向量的和为m时,表示状态向量满足所对应的通讯拓扑稳定性要求,计算-f作为当前时刻奖励,否则当前时刻奖励为-5;选择动作后将所对应的元素位置更新为1,获得下一个环境状态st+1和奖励rt,存储(st,at,rt,st+1)在回放池中。
26、更进一步的,还包括步骤四:根据奖励选择新的通信拓扑结构,当出现更好的拓扑结构时,通信拓扑适应度值下降,dqn算法的奖励会随着更新次数逐渐增加,所以当奖励收敛在一个值时停止算法,否则转到步骤二。
27、有益效果
28、本发明通过新的基于通信距离和收敛时间的评价函数建立了通信拓扑和多智能体的连接,可用于评估不同通信拓扑质量,从而结合强化学习算法实现在多智能体系统各个阶段选择出最优通信拓扑结构;
29、本发明融合强化学习算法dqn生成最优通信拓扑,相较于传统方法当中人为给定的多智能体系统通信拓扑结构,本发明充分考虑了多智能体系统的控制器性能和通信成本,在保证系统的稳定性前提下,大幅提高了系统控制器的性能,减少了系统收敛的时间,有效降低了智能体之间的通信成本。
技术特征:
1.一种基于强化学习算法的通信拓扑优化方法,其特征在于,包括以下步骤:
2.根据权利要求1所述的基于强化学习算法的通信拓扑优化方法,其特征在于,所述步骤s101具体包括:
3.根据权利要求1所述的基于强化学习算法的通信拓扑优化方法,其特征在于,所述步骤s102具体包括:
4.根据权利要求3所述的基于强化学习算法的通信拓扑优化方法,其特征在于,当控制律和系统输入已知,初始状态为常数时:
5.根据权利要求4所述的基于强化学习算法的通信拓扑优化方法,其特征在于,在计算多智能体系统的收敛时间时,将各智能体在各时间间隔δt上的距离差定义为δj;若距离差δj满足则认为多智能体系统在时刻t收敛。
6.根据权利要求1所述的基于强化学习算法的通信拓扑优化方法,其特征在于,所述步骤s103具体包括以下步骤:
7.根据权利要求6所述的基于强化学习算法的通信拓扑优化方法,其特征在于,还包括步骤四:根据奖励选择新的通信拓扑结构,当出现更好的拓扑结构时,通信拓扑适应度值下降,dqn算法的奖励会随着更新次数逐渐增加,所以当奖励收敛在一个值时停止算法,否则转到步骤二。
技术总结
本发明公开了一种基于强化学习算法的通信拓扑优化方法,属于多智能体系统技术领域,包括以下步骤:S101、构建基于强化学习算法的最优通信拓扑生成框架;S102、设计基于通信距离和收敛时间的通讯拓扑评价函数,利用评价函数的值作为学习最优策略更新规则的奖励值;S103、改变通信拓扑,根据多智能体系统的运行结果选择出最优的通信拓扑结构,保证多智能体系统稳定并提高系统控制器的性能。通过上述方式,本发明融合强化学习算法DQN生成最优通信拓扑,充分考虑了多智能体系统的控制器性能和通信成本,在保证系统的稳定性前提下,大幅提高了系统控制器的性能,减少了系统收敛的时间,有效降低了智能体之间的通信成本。
技术研发人员:王震,严利,于登秀,周松博,金军委
受保护的技术使用者:西北工业大学
技术研发日:
技术公布日:2024/1/15
- 还没有人留言评论。精彩留言会获得点赞!