一种基于策略梯度优化的在线数字人动作生成方法和系统与流程
本发明属于人工智能领域,尤其涉及一种基于策略梯度优化的在线数字人动作生成方法和系统。
背景技术:
1、随着深度学习技术的飞速发展,对话系统、语音合成和视频合成能力日益进步,结合这些技术,如今已经可以实现高质量的实时2.5d数字人视频合成,合成的数字人形象和真人极为相似,一般看不出差异,而且还具备非常高的实时交互性能。因此这种2.5d数字人技术可以应用于多种场景,包括视频直播、教育、导购、客服等多种需要交互的场景中,其中一个很重要的应用场景便是交互终端上的助理或客服数字人。后面为了简单起见,将用数字人来简称2.5d数字人。
2、目前数字人的动作是通过还原模板视频中的动作来实现的,具体来讲,目前的数字人技术是通过顺序播放模板视频中的肢体动作,然后通过语音驱动生成新的人脸,替换模板中的人脸,从而得到新的数字人视频。在交互场景下,这样的方案会存在一个问题:生成的数字人视频在动作上会出现不连续。这里面存在两个原因:第一,数字人模板视频长度是有限的,当生成长度超过模板长度时,数字人的动作就需要从最后帧回到初始帧,造成画面的跳动;第二,在交互场景中,当数字人回答完一个问题后,应该进行动作的归位,这里的归位是指动作回到不说话的状态,比如自然摆放到桌面上,或者自然下垂于身前等等,做出一个等待询问的姿态,而不是回答完毕,肢体动作却依然处于回答中的姿态,这样会大大影响数字人用于交互场景真实感。
3、针对不连续和跳动的问题,目前一般采用循环播放的方法,即当数字人模板从初始帧已经前进到最后帧的时候,不采用跳回初始帧,而是通过倒序的方法,从最后帧倒退回第一帧,以此循环往复,来保证数字人动作的连续性。
4、针对不归位的方法,目前一般采用拍摄两段不同模板的方式,第一段是一直保持静止或等待问询的状态,第二段则是正常讲话的视频,两段视频的初始帧会保证一致。当不处于回答状态的时候,会一直播放静止状态的视频;当回答的时候,会利用正常讲话视频的模板进行数字人合成。但是这样的归位方案,依然存在不连续的问题,当数字人视频合成到讲话结束时,动作依然处于讲话的状态,而下一帧则要开始播放归位的模板视频,中间会出现明显的跳动。
5、综上,现有的数字人动作生成方法至少存在以下问题:
6、(1)数字人讲话完毕进行归位的过程中会出现动作不连续的问题。
7、(2)数字人被交互式打断的时候,打断的方式会和外界环境,以及与之交互的人类行为有着很强的相关性,目前的方法难以以连续的方式进行动作归位。
8、(3)部署到实际交互终端中的数字人,其动作生成方式在部署时就已经确定,无法根据实际使用场景中的交互情况,进行动作生成方案的优化。
技术实现思路
1、为了解决现有的交互式数字人动作生成中归位或者打断归位造成的动作不连续问题,本发明提供了一种基于策略梯度优化的在线数字人动作生成方法和系统,通过选择合理的模板片段长度、预测打断的可能性、自适应的持续学习等方式保证了数字人动作归位更平滑与连续,提升了数字人动作生成的效果。
2、为了实现上述目的,本发明采用的技术方案如下:
3、第一方面,本发明提供了一种基于策略梯度优化的在线数字人动作生成方法,包括:
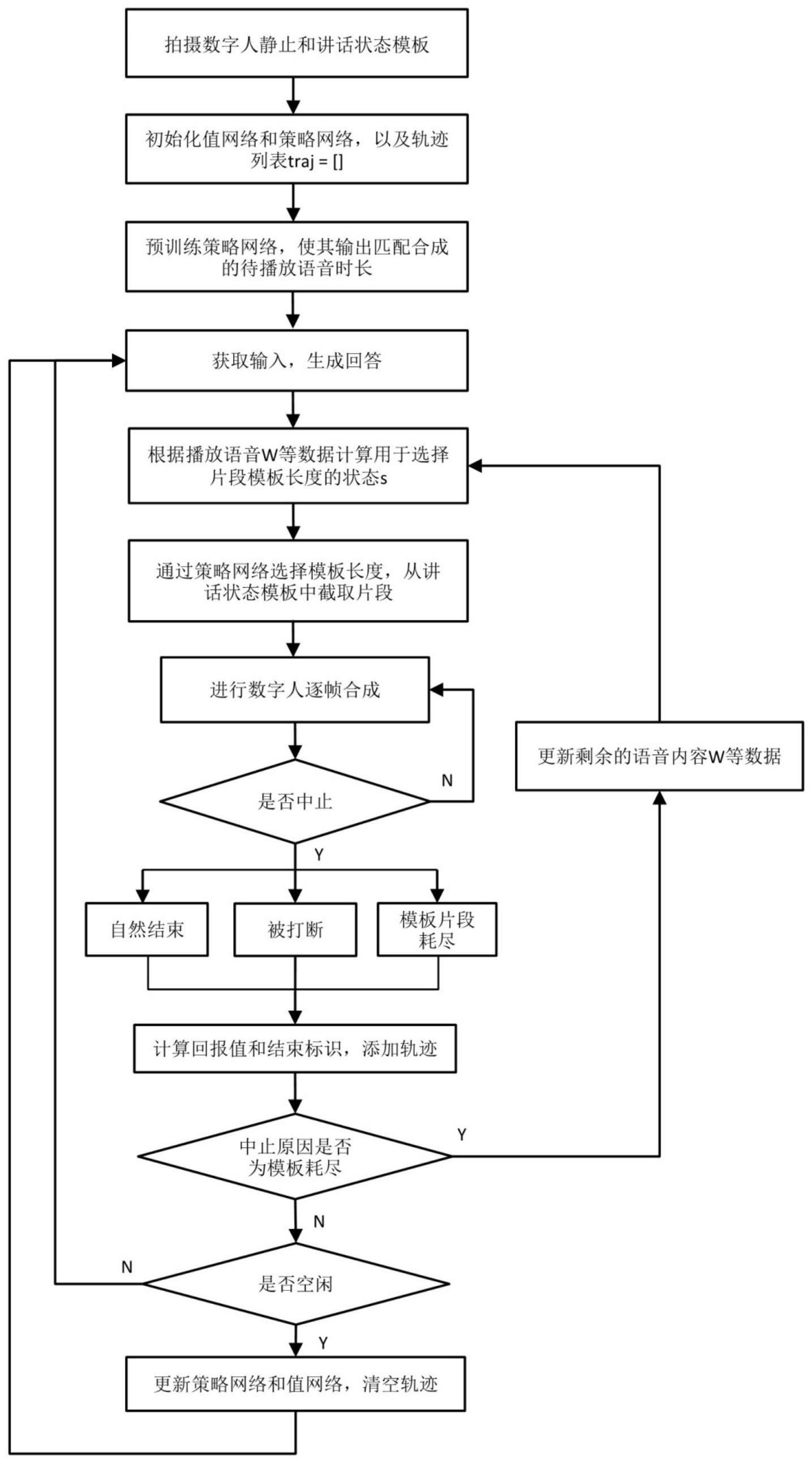
4、拍摄数字人静止状态模板和讲话状态模板,初始化轨迹列表和用于模板循环长度生成的值-策略神经网络,对值-策略神经网络中的策略网络进行预训练;
5、接收交互指令,将当前用户语音输入转换为文本问题,生成回答文本,再根据回答文本合成待播放语音,计算当前状态;
6、通过值-策略神经网络中的策略网络,生成讲话状态模板中的选定模板片段的长度,在选定的视频模板片段上进行一次往复的数字人动作生成,直至回答自然结束、被打断或者视频模板片段耗尽;记录结束标识和回报值,将当前状态、选定模板片段的长度、回报值和结束标识元组加入到轨迹列表中;
7、判断当前回答状态,若当前回答已完成,则切换到静止状态模板以让数字人动作归位或者开启新的交互,并在数字人空闲时根据轨迹列表中的数据更新值-策略神经网络的参数,更新完成后清空轨迹列表;若当前回答未完成,则根据当前所剩的待播放语音和所剩的待回答文本更新当前状态,继续完成回答。
8、第二方面,本发明提供了一种基于策略梯度优化的在线数字人动作生成系统,用于实现上述的在线数字人动作生成方法。
9、第三方面,本发明提供了一种电子设备,包括处理器和存储器,所述存储器存储有能够被所述处理器执行的机器可执行指令,所述处理器执行所述机器可执行指令以实现上述的在线数字人动作生成方法。
10、第四方面,本发明提供了一种机器可读存储介质,该机器可读存储介质存储有机器可执行指令,该机器可执行指令在被处理器调用和执行时,用于实现上述的在线数字人动作生成方法。
11、本发明具备的有益效果是:
12、(1)本发明提出的数字人动作模板选择方法,能够选择合理的模板动作播放方式,在非打断的情形下,使得数字人动作归位尽可能平滑与连续。
13、(2)在数字人回答被用户打断的情形下,本发明提出的方法可以较好地预测打断的时机,从而提前选择合适长度的模板片段,使得被打断后的数字人动作离初始状态尽可能接近,更容易归位。
14、(3)数字人部署到交互终端后,本发明的方案能够根据实际使用场景中的交互,开展自适应的持续学习,从而不断提升回答时长预测的准确性和动作生成方法的合理性,提升数字人动作归位的连续性和自然性,以适应于其实际所处的场合。
技术特征:
1.一种基于策略梯度优化的在线数字人动作生成方法,其特征在于,包括:
2.根据权利要求1所述的基于策略梯度优化的在线数字人动作生成方法,其特征在于,所述的静止状态模板和讲话状态模板长度一致。
3.根据权利要求1所述的基于策略梯度优化的在线数字人动作生成方法,其特征在于,所述的计算当前状态,包括:
4.根据权利要求3所述的基于策略梯度优化的在线数字人动作生成方法,其特征在于,所述的预测可打断时间点,包括:
5.根据权利要求1所述的基于策略梯度优化的在线数字人动作生成方法,其特征在于,所述的通过值-策略神经网络中的策略网络,生成讲话状态模板中的选定模板片段的长度,在选定的视频模板片段上进行一次往复的数字人动作生成,直至回答自然结束、被打断或者视频模板片段耗尽,包括:
6.根据权利要求1所述的基于策略梯度优化的在线数字人动作生成方法,其特征在于,所述的记录结束标识和回报值,包括:
7.根据权利要求1所述的基于策略梯度优化的在线数字人动作生成方法,其特征在于,所述的在数字人空闲时根据轨迹列表中的数据更新值-策略神经网络的参数,包括:
8.一种基于策略梯度优化的在线数字人动作生成系统,其特征在于,包括:
9.一种电子设备,其特征在于,包括处理器和存储器,所述存储器存储有能够被所述处理器执行的机器可执行指令,所述处理器执行所述机器可执行指令以实现权利要求1至7任一项所述的基于策略梯度优化的在线数字人动作生成方法。
10.一种机器可读存储介质,其特征在于,该机器可读存储介质存储有机器可执行指令,该机器可执行指令在被处理器调用和执行时,用于实现权利要求1至7任一项所述的基于策略梯度优化的在线数字人动作生成方法。
技术总结
本发明公开了一种基于策略梯度优化的在线数字人动作生成方法和系统,属于人工智能技术领域。包括初始化模板、轨迹列表和值‑策略神经网络;接收交互指令,计算当前状态;通过策略网络生成选定模板片段的长度,在模板片段上进行一次往复的数字人动作生成,直至回答自然结束、被打断或者视频模板片段耗尽,记录结束标识和回报值并和当前状态、选定模板片段的长度一起加入到轨迹列表中;其中若在回答过程中视频模板片段耗尽,则根据当前所剩的待播放语音和待回答文本更新当前状态,继续完成回答。待数字人空闲时,根据轨迹列表中的数据更新值‑策略神经网络的参数,更新完成后清空轨迹列表。本发明使得数字人动作归位更平滑与连续。
技术研发人员:薛弘扬
受保护的技术使用者:杭州一知智能科技有限公司
技术研发日:
技术公布日:2024/1/15
- 还没有人留言评论。精彩留言会获得点赞!