一种基于机器学习的光信道误码率预测方法
本发明涉及ai监督学习领域及预测性运维领域,具体为一种基于机器学习的光信道误码率预测方法。
背景技术:
1、光传送网(otn)技术是电网络与全光网折衷的产物,指在光域内实现业务信号的传送、复用、路由选择、监控,并且保证其性能指标和生存性的传送网络;因此光信道och层具备了类似sdh/sonet网络中基于单波长的omap功能,目前业界针对光信道误码率的预测主要采用基于深度学习的循环神经网络rnn算法,其中arima模型是时间序列预测分析最主要的机器学习方法之一。
2、现有技术中,光信道误码率数据存在较多的突变“数据段”,且突变是跨数量级的,这就导致即便用n阶差分,都不可能消除这样数据的不平稳性;但是“数据段”内的数据又是“平稳的”,所以从理论上来说,即便数据段突变处可能无法预测准确,但是突变后的“数据段”内的数据又基本上是“平稳的”,另一方面光信道误码率数据存在较多的突变“数据点”(噪声),噪声达到一定数量,将会对机器学习造成严重的影响。
技术实现思路
1、针对现有技术存在的不足,本发明目的是提供一种基于机器学习的光信道误码率预测方法,以解决上述背景技术中提出的问题,本发明解决了光信道误码率数据平稳性问题,实现利用arima这样的“小型”机器学习模型对对光网络的光信道误码率进行建模、学习、训练和预测。
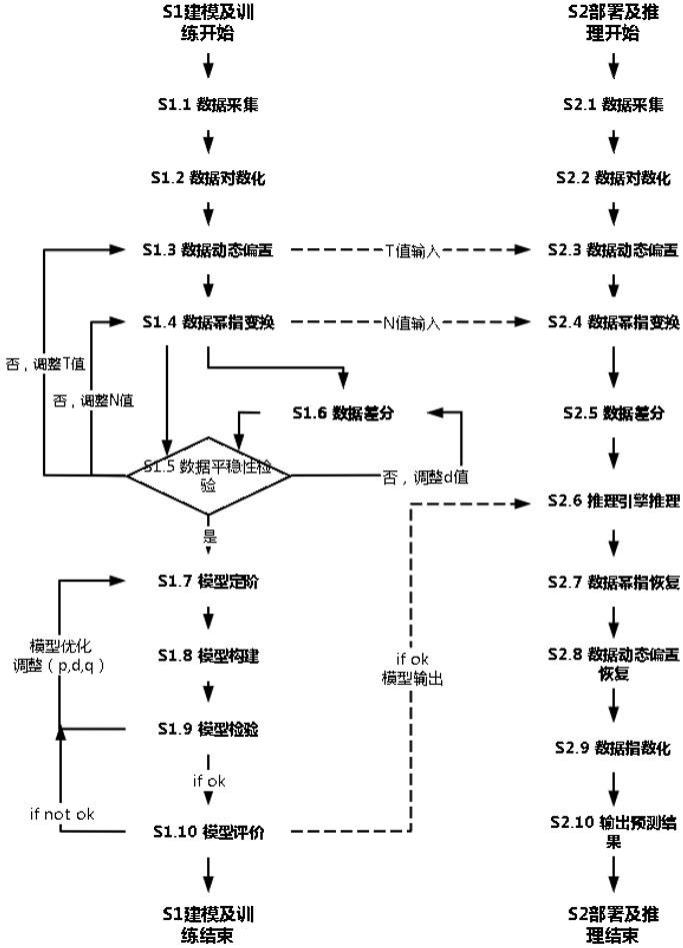
2、为了实现上述目的,本发明是通过如下的技术方案来实现:一种基于机器学习的光信道误码率预测方法,包括建模及训练阶段和部署推理阶段,所述建模及训练阶段包括数据采集、数据对数化、数据动态偏置、数据幂指变换、数据平稳性检验、数据差分、模型定阶、模型构建、模型检验、模型评价,所述部署推理阶段包括数据采集、数据对数化、数据动态偏置、数据幂指变换、数据差分、推理引擎推力、数据幂指恢复、数据动态偏置恢复、数据指数化、输出预测结果,通过上述过程并用arima模型来对光网络的光域光信道误码率进行建模、学习、训练和预测。
3、进一步的,该预测方法包含“数据对数变换可差分化方法”:降低数据数量级将数据范围缩小至(约-10,0)范围内,解决误码率数量级变化导致的不可“差分”问题。
4、进一步的,所述该预测方法包含“基于幂指函数动态偏置的arima模型”方法,解决光信道误码数据中“突变数据”“不平稳数据”导致无法进行自回归问题。
5、进一步的,在arima模型中首先通过“幂指函数动态偏置”其中将其数据变的更加“平稳”,然后再利用arima模型针对y'数据进行机器学习得到模型
6、进一步的,所述“幂指函数动态偏置”的过程中,动态偏置将其数据变换至以“0”为中心附近波动;且幂指函数将数据向+1,-1附近拉伸;所述部署推理阶段在推理过程中将上数据逆向变换,得到所需预测的光信道误码率。
7、进一步的,所述建模及训练阶段的数据采集中,针对每一个光信道建立一套模型,通过网络管控系统按照光信道id采集读取和采集光信道历史ber。
8、进一步的,所述数据平稳性检验包括以下三种方法:直接观察数据序列图、观察自相关图,平稳的序列的自相关图(acf)和偏相关图(pacf)以及单位根检验。
9、进一步的,所述模型检验主要包括模型的显著性检验:检验整个模型对信息的提取是否充分,该过程主要是利用qq图检验残差是否满足正态分布;参数显著性检验:检验模型是否最简,主要检测对象是残差序列,该过程主要利用d-w检验残差的自相关性。
10、进一步的,所述部署推理阶段中的数据差分根据建模及训练阶段中“学习、训练、优化”好的d值来进行差分,d=0无需进行差分;d等于其它数值,则按照对应阶数进行差分。
11、进一步的,所述部署推理阶段中推理引擎推力包括可运行的脚本或者特定功能应用程序或者大型的网络管控系统中的ai引擎。
12、本发明的有益效果:
13、该基于机器学习的光信道误码率预测方法提出“数据对数变换可差分化方法”,解决了误码率数量级变化导致的不可“差分”问题;
14、该基于机器学习的光信道误码率预测方法提出了“基于动态偏置的arima算法”,解决光信道误码数据中“突变数据”“不平稳数据”导致无法进行自回归的问题,以此实现了基于arima模型的光信道误码率预测。
技术特征:
1.一种基于机器学习的光信道误码率预测方法,其特征在于:包括建模及训练阶段和部署推理阶段,所述建模及训练阶段包括数据采集、数据对数化、数据动态偏置、数据幂指变换、数据平稳性检验、数据差分、模型定阶、模型构建、模型检验、模型评价,所述部署推理阶段包括数据采集、数据对数化、数据动态偏置、数据幂指变换、数据差分、推理引擎推力、数据幂指恢复、数据动态偏置恢复、数据指数化、输出预测结果,通过上述过程并用arima模型来对光网络的光域光信道误码率进行建模、学习、训练和预测,该预测方法包含数据对数变换可差分化方法:降低数据数量级将数据范围缩小至-10~0范围内,解决误码率数量级变化导致的不可差分问题,所述该预测方法包含基于幂指函数动态偏置的arima模型方法,解决光信道误码数据中“突变数据”“不平稳数据”导致无法进行自回归问题,在arima模型中首先通过幂指函数动态偏置,其中将其数据变的更加平稳,然后再利用arima模型针对y'数据进行机器学习得到模型,所述幂指函数动态偏置的过程中,动态偏置将其数据变换至以“0”为中心附近波动;且幂指函数将数据向+1,-1附近拉伸;所述部署推理阶段在推理过程中将上数据逆向变换,得到所需预测的光信道误码率。
2.根据权利要求1所述的一种基于机器学习的光信道误码率预测方法,其特征在于:所述建模及训练阶段的数据采集中,针对每一个光信道建立一套模型,通过网络管控系统按照光信道id采集读取和采集光信道历史ber。
3.根据权利要求1所述的一种基于机器学习的光信道误码率预测方法,其特征在于:所述数据平稳性检验包括以下三种方法:直接观察数据序列图、观察自相关图,平稳的序列的自相关图acf和 偏相关图pacf以及单位根检验。
4.根据权利要求3所述的一种基于机器学习的光信道误码率预测方法,其特征在于:所述模型检验主要包括模型的显著性检验:检验整个模型对信息的提取是否充分,该过程主要是利用qq图检验残差是否满足正态分布;参数显著性检验:检验模型是否最简,主要检测对象是残差序列,该过程主要利用d-w检验残差的自相关性。
5.根据权利要求1所述的一种基于机器学习的光信道误码率预测方法,其特征在于:所述部署推理阶段中的数据差分根据建模及训练阶段中学习、训练、优化好的d值来进行差分,d=0无需进行差分;d等于其它数值,则按照对应阶数进行差分。
6.根据权利要求5所述的一种基于机器学习的光信道误码率预测方法,其特征在于:所述部署推理阶段中推理引擎推力包括可运行的脚本或者特定功能应用程序或者大型的网络管控系统中的ai引擎。
技术总结
本发明提供一种基于机器学习的光信道误码率预测方法,包括建模及训练阶段和部署推理阶段,所述建模及训练阶段包括数据采集、数据对数化、数据动态偏置、数据幂指变换、数据平稳性检验、数据差分、模型定阶、模型构建、模型检验、模型评价,所述部署推理阶段包括数据采集、数据对数化、数据动态偏置、数据幂指变换、数据差分、推理引擎推力、数据幂指恢复、数据动态偏置恢复、数据指数化、输出预测结果,该预测方法提出“数据对数变换可差分化方法”,解决了误码率数量级变化导致的不可“差分”问题,解决光信道误码数据中“突变数据”“不平稳数据”导致无法进行自回归的问题,以此实现了基于ARIMA模型的光信道误码率预测。
技术研发人员:何舟,张鹏,肖泳,胡昱,李莹玉,陈晓辉
受保护的技术使用者:湖北经济学院
技术研发日:
技术公布日:2024/1/16
- 还没有人留言评论。精彩留言会获得点赞!