基于联邦知识蒸馏学习的知识解耦反演攻击方法及装置
本发明涉及网络安全,尤其涉及一种联邦知识蒸馏学习的知识解耦反演攻击方法及装置。
背景技术:
1、联邦学习是一种分布式学习范式,其中每个参与方将其本地训练模型的梯度或参数发送到一个集中的服务器,该服务器使用聚合的梯度/参数来学习一个全局模型。尽管这一过程允许客户隐藏其私有数据,但仍存在潜在的隐私风险,即恶意服务器可以通过共享的梯度/参数来重构私有数据(仅对个别客户可见),从而暴露严重的隐私问题。
2、对此,现有技术提出了基于知识蒸馏的联邦学习(以下称联邦知识蒸馏学习),以作为上述问题的有效解决方案之一。
3、在联邦知识蒸馏学习中,每个参与方在本地训练中使用其私有数据和公共数据集,并将其在公共数据集上的预测值(称为公共知识)发送给服务器,然后服务器进行聚合,并将聚合后的预测值发送回每个参与方以进行下一轮迭代。
4、由此可知,在联邦知识蒸馏学习中,服务器只能访问公共数据集上的预测值,从而防止了梯度或参数泄漏,并且在低通信成本下保留了数据和模型的异质性。
5、目前的研究表明,联邦知识蒸馏学习是对传统联邦学习框架面临安全风险的可行防御策略,并且许多研究将联邦知识蒸馏视为解决现实问题的合适方案,这促使知识蒸馏与联邦学习结合的方案在工业场景中得到广泛应用。
6、然而,尽管联邦知识蒸馏学习很受欢迎,但目前很少针对联邦知识蒸馏学习中共享的公共知识的安全性进行分析研究。
7、在联邦知识蒸馏学习的框架下,现有技术提供了一些反演攻击方法,但这些反演攻击方法并不能够仅从公共知识中恢复出相应客户端的私有数据,无法为联邦知识蒸馏学习算法的安全性提供进一步的指导。
8、因此,如何解决现有反演攻击方法无法仅从公共知识中恢复目标客户端的私有数据的问题,是网络安全技术领域亟待解决的重要课题。
技术实现思路
1、本发明提供一种联邦知识蒸馏学习的知识解耦反演攻击方法及装置,用以克服现有反演攻击方法无法仅从公共知识中恢复目标客户端的私有数据的缺陷,实现客户端私有信息与仅在公共数据上学习的知识“解耦”,为联邦知识蒸馏学习算法的安全性提供进一步的指导。
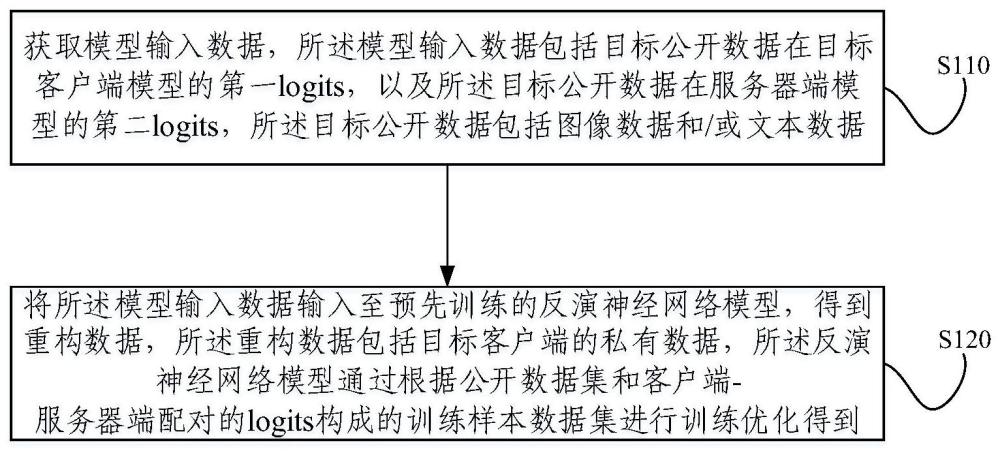
2、一方面,本发明提供一种基于联邦知识蒸馏学习的知识解耦反演攻击方法,包括:获取模型输入数据,所述模型输入数据包括目标公开数据在目标客户端模型的第一logits,以及所述目标公开数据在服务器端模型的第二logits,所述目标公开数据包括图像数据或文本数据;将所述模型输入数据输入至预先训练的反演神经网络模型,得到重构数据,所述重构数据包括目标客户端的私有数据,所述反演神经网络模型通过根据公开数据集和客户端-服务器端配对的logits构成的训练样本数据集进行训练优化得到。
3、进一步地,训练所述反演神经网络模型,具体包括:基于置信度优化算法和先验估计算法,通过目标函数对所述反演神经网络模型进行训练优化。
4、进一步地,所述基于置信度优化算法和先验估计算法,通过目标函数对所述反演神经网络模型进行训练优化,包括:在训练所述反演神经网络模型的过程中,采用置信度优化公式对所述反演神经网络模型的模型输入进行优化调整,以获取所述反演神经网络模型的最优模型输入。
5、进一步地,所述置信度优化公式如下:
6、
7、
8、其中,表示所述反演神经网络模型的预测输出的质量,表示第k个客户端拥有的任意目标标签j的重构类表示,和分别表示和的第j个元素,τ表示计算softmax函数时使用的温度,表示公开数据i在客户端模型的客户端logits,表示公开数据i在服务器端模型的服务器端logits,α表示权重因子,h(·)表示熵函数。
9、进一步地,所述基于置信度优化算法和先验估计算法,通过目标函数对所述反演神经网络模型进行训练优化,包括:在训练所述反演神经网络模型的过程中,采用先验估计公式对先验数据进行估计,以使所述反演神经网络模型的预测输出更接近真实数据;
10、其中,所述先验数据为与所述目标公开数据相同领域的公开数据集的样本均值。
11、进一步地,所述先验估计公式如下:
12、
13、其中,da表示公开数据集子集,aφ表示先验估计模型,i表示公开数据样本标签,表示公开数据样本。
14、进一步地,所述目标函数如下:
15、
16、
17、其中,gθ表示所述反演神经网络模型的转置卷积层,表示公开数据i在服务器端模型的预测输出,表示公开数据i在客户端模型的预测输出,表示公开数据样本,γ是超参数,为先验数据的可调权重,表示先验数据,softmax(·,τ)表示使用温度τ的归一化指数函数,表示公开数据i在服务器端模型的服务器端logits,表示公开数据i在客户端模型的客户端logits,‖·‖2表示l2范数。
18、第二方面,本发明还提供一种基于联邦知识蒸馏学习的知识解耦反演攻击装置,包括:模型输入数据获取模块,用于获取模型输入数据,所述模型输入数据包括目标公开数据在目标客户端模型的第一logits,以及所述目标公开数据在服务器端模型的第二logits,所述目标公开数据包括图像数据和/或文本数据;客户端私有数据重构模块,用于将所述模型输入数据输入至预先训练的反演神经网络模型,得到重构数据,所述重构数据包括目标客户端的私有数据,所述反演神经网络模型通过根据公开数据集和客户端-服务器端配对的logits构成的训练样本数据集进行训练优化得到。
19、第三方面,本发明还提供一种电子设备,包括存储器、处理器及存储在存储器上并可在处理器上运行的计算机程序,所述处理器执行所述程序时实现如上述任一种所述的基于联邦知识蒸馏学习的知识解耦反演攻击方法。
20、第四方面,本发明还提供一种非暂态计算机可读存储介质,其上存储有计算机程序,该计算机程序被处理器执行时实现如上述任一种所述的基于联邦知识蒸馏学习的知识解耦反演攻击方法。
21、本发明提供的一种针对联邦知识蒸馏学习的知识解耦反演攻击方法,通过获取模型输入数据,模型输入数据包括目标公开数据在目标客户端模型的第一logits,以及目标公开数据在服务器端模型的第二logits,目标公开数据包括图像数据和/或文本数据,并将模型输入数据输入至预先训练的反演神经网络模型,得到重构数据,重构数据包括目标客户端的私有数据,反演神经网络模型通过根据公开数据集和客户端-服务器端配对的logits构成的训练样本数据集进行训练优化得到。该方法通过根据公开数据集和客户端-服务器端配对的logits构成的训练样本数据集训练优化得到的反演神经网络模型,目标客户端的私有数据进行重构,此过程无需梯度,且将私有数据与公共知识完全解耦,克服了现有反演攻击方法无法仅从公共知识中恢复目标客户端的私有数据的缺陷,实现了客户端私有信息与仅在公共数据上学习的知识的“解耦”,可以为联邦知识蒸馏学习算法的安全性提供进一步的指导。
技术特征:
1.一种基于联邦知识蒸馏学习的知识解耦反演攻击方法,其特征在于,包括:
2.根据权利要求1所述的基于联邦知识蒸馏学习的知识解耦反演攻击方法,其特征在于,训练所述反演神经网络模型,具体包括:
3.根据权利要求2所述的基于联邦知识蒸馏学习的知识解耦反演攻击方法,其特征在于,所述基于置信度优化算法和先验估计算法,通过目标函数对所述反演神经网络模型进行训练优化,包括:
4.根据权利要求3所述的基于联邦知识蒸馏学习的知识解耦反演攻击方法,其特征在于,所述置信度优化公式如下:
5.根据权利要求2所述的基于联邦知识蒸馏学习的知识解耦反演攻击方法,其特征在于,所述基于置信度优化算法和先验估计算法,通过目标函数对所述反演神经网络模型进行训练优化,包括:
6.根据权利要求5所述的基于联邦知识蒸馏学习的知识解耦反演攻击方法,其特征在于,所述先验估计公式如下:
7.根据权利要求2-6中任一项所述的基于联邦知识蒸馏学习的知识解耦反演攻击方法,其特征在于,所述目标函数如下:
8.一种基于联邦知识蒸馏学习的知识解耦反演攻击装置,其特征在于,包括:
9.一种电子设备,包括存储器、处理器及存储在所述存储器上并可在所述处理器上运行的计算机程序,其特征在于,所述处理器执行所述程序时实现如权利要求1至7中任一项所述的基于联邦知识蒸馏学习的知识解耦反演攻击方法。
10.一种非暂态计算机可读存储介质,其上存储有计算机程序,其特征在于,所述计算机程序被处理器执行时实现如权利要求1至7中任一项所述的基于联邦知识蒸馏学习的知识解耦反演攻击方法。
技术总结
本发明提供一种联邦知识蒸馏学习的知识解耦反演攻击方法及装置,其中的方法包括:获取模型输入数据,模型输入数据包括目标公开数据在目标客户端模型的第一logits和目标公开数据在服务器端模型的第二logits;将模型输入数据输入至预先训练的反演神经网络模型,得到目标客户端的私有数据,反演神经网络模型通过公开数据集和客户端‑服务器端配对的logits构成的训练样本数据集进行训练优化得到。该方法通过预先训练的反演神经网络模型重构目标客户端的私有数据,此过程无需梯度,且将私有数据与公共知识完全解耦,实现了客户端私有信息与仅在公共数据上学习的知识的“解耦”,可为联邦知识蒸馏学习算法的安全性提供进一步的指导。
技术研发人员:刘洋,普艳红
受保护的技术使用者:清华大学
技术研发日:
技术公布日:2024/2/29
- 还没有人留言评论。精彩留言会获得点赞!