一种基于Q学习的无线自组网抗干扰路由智能决策方法
本发明属于通信抗干扰,特别是涉及一种基于q学习的无线自组网抗干扰路由智能决策方法。
背景技术:
1、无线自组织网是一种重要的无线通信组网模式,广泛应用于各种场合。但随着各种无线设备的广泛运用,电磁环境日益复杂,恶意干扰层出不穷。扩展频谱技术、自适应干扰对消技术、自适应跳频技术、自适应陷波技术等常规抗干扰技术主要通过频域、时域、功率域或空域的信号处理方法来实现干扰环境下单个通信节点或单条通信链路的可靠通信。当多个通信节点组成无线自组网时,仅仅依靠单通信节点或单条通信链路的抗干扰技术已难以应对无线自组网中节点之间可靠有效传输信息的需求。另一方面,无干扰条件下无线自组网选择传输时间最短的路由(以下简称“最短路由”)的方法已经相当成熟和有效,如经典的yen’s算法等。但干扰环境下尤其是位置可移动的恶意干扰下无线自组网的最短路由选择方法还较少见。
技术实现思路
1、本发明的目的是提供一种基于q学习的无线自组网抗干扰路由智能决策方法,能够在位置可移动恶意干扰下的无线自组网中选择最短路由,实现可靠通信,以解决上述现有技术存在的问题。
2、为实现上述目的,本发明提供了一种基于q学习的无线自组网抗干扰路由智能决策方法,包括以下步骤:
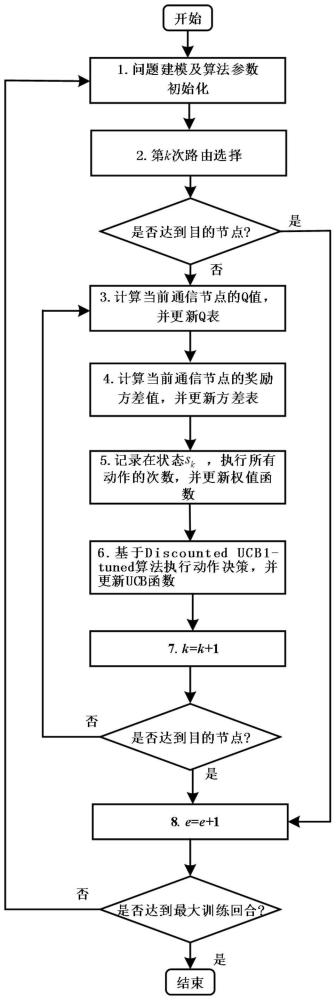
3、s1.基于马尔科夫决策过程表征位置可移动恶意干扰下的最优路由选择过程,并分别定义无线自组网的状态空间、动作空间以及奖励函数;
4、s2.基于所述状态空间、动作空间、奖励函数分别构建无线自组网中当前通信节点的q表、v表以及ucb表;
5、s3.对q表、v表以及ucb表进行初始化,并基于q学习算法进行路由选择;
6、s4.判断路由选择后获取的通讯节点是否为目的节点;
7、s5.基于步骤s4的判断结果对通信节点的q表、v表、权值函数以及ucb表进行迭代,直至达到最大迭代次数;
8、s6.基于迭代结果进行无线自组网的数据传输。
9、可选地,基于q学习算法进行路由选择的过程中,通信节点的q表、v表以及ucb表随通讯节点的改变进行更新。
10、可选地,所述步骤s5中,基于步骤s4的判断结果对通信节点的q表、v表、权值函数以及ucb表进行迭代的过程包括:
11、若路由选择后获取的通讯节点是目的节点,则增加迭代周期,并重新执行步骤s1;
12、若路由选择后获取的通讯节点不是目的节点,则对q表、v表、权值函数以及ucb表进行更新,使当前通信节点基于discounted ucb1-tuned算法选择下一跳的传输动作,并重新进行路由选择,若达到目的节点,则增加迭代周期,并重新执行步骤s1,若未达到目的节点,则重新进行路由选择,直至达到目的节点。
13、可选地,所述q表的更新过程包括:
14、基于discounted ucb1-tuned算法消除初始值的影响,并按下式进行q表的更新:
15、
16、其中,qk+1(sk,ak)是在状态sk下采取动作ak后通信节点nk+1的q值;是归一化的即时回报,qk(sk,ak)表示在状态sk下采取动作ak后通信节点nk的q值,表示在状态sk+1时,采取任意动作ak+1后所能得到的最大q值,rk表示通信节点nk在状态sk执行动作ak时得到的即时回报,α是学习率,γ是折扣因子。
17、可选地,所述v表的更新过程包括:
18、
19、其中,v(sk,ak)是当前通信节点nk在状态sk下执行动作ak的加权奖励方差,n(sk,ak)是当前通信节点nk在状态sk下执行动作ak的次数,β是阻尼因子,c′是决定探索趋势的常数。
20、可选地,所述权值函数的更新过程包括:
21、记录当前通信节点在某环境状态下执行所有动作的次数,若次数为0,则使次数加一进行更新,若次数不为0,则根据下式进行更新:
22、
23、其中,c(sk,ak)为权值函数,n(sk,ak)是当前通信节点nk在状态sk下执行动作ak的次数,是当前通信节点nk在状态sk下执行动作的次数,v(sk,ak)是当前通信节点nk在状态sk下执行动作ak的加权奖励方差,c′是决定探索趋势的常数,k2表示在状态sk下所有可选择的动作的数量。
24、可选地,所述ucb表的更新过程包括:
25、
26、其中,ucb(sk,ak)表示当前通信节点nk在状态sk下执行动作ak对应的ucb值,n(sk,ak)是当前通信节点nk在状态sk下执行动作ak的次数,是当前通信节点nk在状态sk下执行动作的次数,c(sk,ak)为权值函数,式中k2表示在状态sk下所有可选择的动作数量。
27、可选地,使当前通信节点基于discounted ucb1-tuned算法选择下一跳的传输动作的过程包括:
28、基于更新后的ucb表选择最大ucb值对应的动作,如下式:
29、
30、其中,表示在动作空间a内取最大ucb值对应的动作a,ak+1表示通信节点nk+1执行的动作。
31、本发明的技术效果为:
32、本发明在可移动恶意干扰机威胁下的多跳无线自组网中,通过采用基于改进ucb策略的q学习算法,实现了无线自组网快速抗干扰路由寻径,有利于无线自组网可靠通信,具有收敛速度快、不易陷入局部最优解的优点;其中,针对强化学习面临的探索与利用窘境,采用ucb算法进行动作选择,避免了人为预设的探索参数对收敛速度的影响,即动作的选择概率是由动作奖励及动作被选择次数共同决定的,降低了初始阶段单次随机动作带来的负面影响,使得q学习算法更容易跳出局部最优解。
技术特征:
1.一种基于q学习的无线自组网抗干扰路由智能决策方法,其特征在于,包括以下步骤:
2.根据权利要求1所述的基于q学习的无线自组网抗干扰路由智能决策方法,其特征在于,基于q学习算法进行路由选择的过程中,通信节点的q表、v表以及ucb表随通讯节点的改变进行更新。
3.根据权利要求1所述的基于q学习的无线自组网抗干扰路由智能决策方法,其特征在于,所述步骤s5中,基于步骤s4的判断结果对通信节点的q表、v表、权值函数以及ucb表进行迭代的过程包括:
4.根据权利要求3所述的基于q学习的无线自组网抗干扰路由智能决策方法,其特征在于,所述q表的更新过程包括:
5.根据权利要求3所述的基于q学习的无线自组网抗干扰路由智能决策方法,其特征在于,所述v表的更新过程包括:
6.根据权利要求3所述的基于q学习的无线自组网抗干扰路由智能决策方法,其特征在于,所述权值函数的更新过程包括:
7.根据权利要求3所述的基于q学习的无线自组网抗干扰路由智能决策方法,其特征在于,所述ucb表的更新过程包括:
8.根据权利要求7所述的基于q学习的无线自组网抗干扰路由智能决策方法,其特征在于,使当前通信节点基于discounted ucb1-tuned算法选择下一跳的传输动作的过程包括:
技术总结
本发明涉及通信抗干扰技术领域,具体公开了一种基于Q学习的无线自组网抗干扰路由智能决策方法,包括:基于马尔科夫决策过程表征位置可移动恶意干扰下的最优路由选择过程,分别定义无线自组网的状态空间、动作空间以及奖励函数;构建无线自组网中当前通信节点的Q表、V表以及UCB表并进行初始化,并基于Q学习算法进行路由选择;判断路由选择后的通讯节点是否为目的节点;基于判断结果对Q表、V表、权值函数以及UCB表进行迭代,直至达到最大迭代次数。本发明实现了无线自组网快速抗干扰路由寻径,避免了人为预设的探索参数对收敛速度的影响,降低了初始阶段单次随机动作的负面影响,使Q学习算法更容易跳出局部最优解。
技术研发人员:牛英滔,韩晨
受保护的技术使用者:中国人民解放军国防科技大学
技术研发日:
技术公布日:2024/2/6
- 还没有人留言评论。精彩留言会获得点赞!