一种基于DETR显著性目标的长短距离的视频描述的方法
本发明实施例涉及机器学习领域,特别地涉及在视频描述领域一种基于detr显著性目标的长短距离的视频描述的方法。
背景技术:
1、视频字幕具有很大的社会意义,具有很大的价值取向,它适用于许多现实世界的应用,包括字幕生成、盲人辅助和自动驾驶叙述。
2、然而,孤立的视频帧可能会受到运动模糊或遮挡的影响,这给视觉理解带来了极大的混乱字幕任务。
3、因此,迫切需要解决一个主要问题:如何利用关于跨框架一致性和单一的丰富的全局局部特征。但是为了更为准确获取句子当中的名词,对视频帧当中的对象获取有是必不可少的。因此本发明实施例把全局和局部特征结合在一起能更好的解决视频描述的生成。
技术实现思路
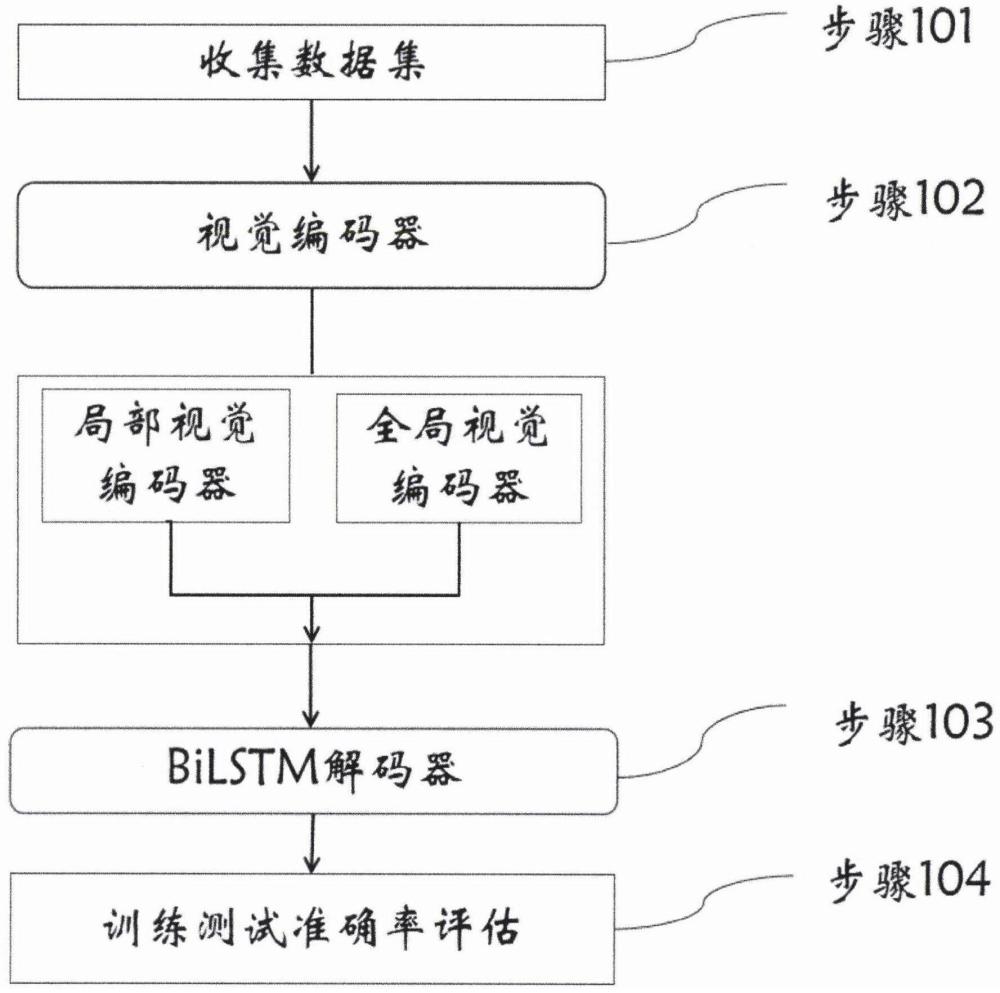
1、为了解决上述问题,试图以更灵活的方法解决视频字幕,该方法利用全局和局部视觉融合表示粒度。具体来说,本发明做出以下解决方法:
2、第一方面,在全局编码器阶段:实施了一个简单的方法架构,将其称为全局表示粒度,它对广泛的视觉表示进行建模并生成丰富的基于不同视频内容的词汇特征范围。我们对随机全局视频进行编码框架根据随机生成全局词汇表训练中的关键帧ft。请注意,本发明的训练迭代将使整个视频剪辑完全饱和,因为每次迭代都会随机选择不同的帧(总数固定)从视频中。我们的远程编码器首先执行2d输入上的卷积(即ft-n和ft+n)来识别相关的上下文特征。的输出特征第一步由3d卷积网络(cnn)处理捕获全局时间对应关系。为了增加共识,本发明实施例从基本事实句子中选择前k个单词选择(最高频率)来指导词汇生成作为k分类任务的输出。
3、第二方面,在局部视觉编码器阶段:实施了一种局部表示粒度,使用了transformer的目标检测算法detr更为准确的提取了局部对象特征,实体模块输出主要对象的特征,利用预先训练的对象检测器detr从每个对象捕获对象区域关键帧,并根据外观对这些区域进行聚类和边界框之间的并交(iou)。然后我们对这些簇应用均值池操作获得初始物体特征其中l表示视频对象的数量和大小的对象特征。由于里面有大量的对象一个视频,但字幕中只提到了一些,我们设计实体显著性对象模块来学习突出这些原理自适应的对象。其次,实施了一种短距离的视觉编码过程,短距离编码器是捕捉物体的运动和趋势。具体来说,同时取两个近邻(又名ft-10和ft+10)关键帧、2d cnn和3d-resnet18提取的分别是全景语义和运动特征表示。之后,这些表示被堆叠并输入密集其中n是大于25帧的随机范围。
4、第三方面,在解码器阶段:实施了采用lstm解码生成视频字幕,本发明实施例的字幕解码器将融合的特征翻译成序列长度为l个单词的句子s={s1,s2,...,sj},j∈(1,2,...,l)形成预测的句子。具体来说,我们使用lstm来生成第i步的隐藏状态hi和单元状态ci。
5、本发明有益效果为:
6、通过视频字幕,本发明主要实施了一个重要通用模型,能用于各种任务。在本发明中,实施了一个用于视频字幕的全局-局部框架,它利用全局-局部视觉表示,通过增量训练策略实现视频内容的细粒度字幕。评估结果表明我们方法的有效性。未来,本发明计划探索动态加权方案来捕捉偏好在不同的粒度上。还计划研究整合更多多模态信息。
技术特征:
1.一种视频字幕生成的网络模型,其特征在于,包括:
2.根据权利要求1的表述的方法,其特征在于,把准备好的视频给模型训练之前,需要把视频提取若干个视频帧,还需要把其中的每个视频帧提取特征:
3.根据权利要求2的表述方法,其特征在于,将检测的模型通过如下方式进行构建:
4.根据权利要求3的表述方法,其特征在于,使用该领域公认的字幕生成的四种评估指标cider-d,belu@4,rouge和metor,其中cider-d是视频描述最后评估性能的关键评价指标。
5.根据权利要求3的表述方法,其特征在于,该网络模型主要包括视觉编码器的对特征提取和自然语言的解码器:
6.一种训练模型的装置主要包括:
7.把数据集送入到权利要求6中的装置当中使用两种方式分别进行模型训练生成最优参数。
技术总结
本发明实例是涉及了机器学习领域,主要设计了一个视频生成标题的深度学习网络模型,该模型主要包含视觉编码器、字幕解码器和最后训练的评估方法,编码器采用了显著性对象提取特征和长短距离视频帧的特征融合的方法得到中间的主要视觉信息,解码器则采用了传统的双向LSTM进行句子当中下一个单词的预测,而训练采用两种方式,分别是播种阶段和增强阶段,本发明实例由于收集的是不同人工标注的句子,来自不同的人工标注标题可能存在偏差,在训练当中则采用了加权平均的方式求其损失函数,从而建立了该视频描述的模型框架得到最终的评估效果。
技术研发人员:何明光,刘斌
受保护的技术使用者:南京工业大学
技术研发日:
技术公布日:2024/4/8
- 还没有人留言评论。精彩留言会获得点赞!