一种基于多模态AI手语生成系统、方法与流程
本发明涉及视频,尤其涉及一种基于多模态ai手语生成系统、方法。
背景技术:
1、随着科技的发展,电视机丰富了人们的业余生活的同时也给人们带来了各种信息,对于大多数人来说电视机的常规功能可满足用户的大部分需求,但是对于特殊人群来说,例如听力受阻的人来说,这类特殊人群仅能通过字幕的方式获取电视节目、电影的信息,但是对于一些年龄较小的小朋友,可能还不能完全认识全部的字,因而无法体会到看电视视频的乐趣,而手语是通过手势比量动作,根据手势的变化模拟形象或音节构成的一定意思或词语,是听力受损人士的一种交际工具。为了满足听力损人群看电视的乐趣,电视视频播放时与手语视频同步的展现出来,供视力受损人群观看。
2、现有技术中的将手语视频与电视视频何为一路视频的方式是在视频拍摄是,同时进行手语翻译并进行拍摄,在视频内容制作时,将视频内容和手语视频整合在一起,将含有手语的内容嵌入到视频实体文件中。然而,这种方式具有诸多的不便之处。首先,手语翻译视频拍摄工作量大,需要大量手语翻译工作人员,很难推广普及。因此现有视频中带手语翻译的内容量很少。其次,手语视频只支持标准手语词目,不支持手语方言,对听障人群来说不够友好。
技术实现思路
1、本发明为了克服现有技术的不足,提供一种基于多模态ai手语生成系统、方法。
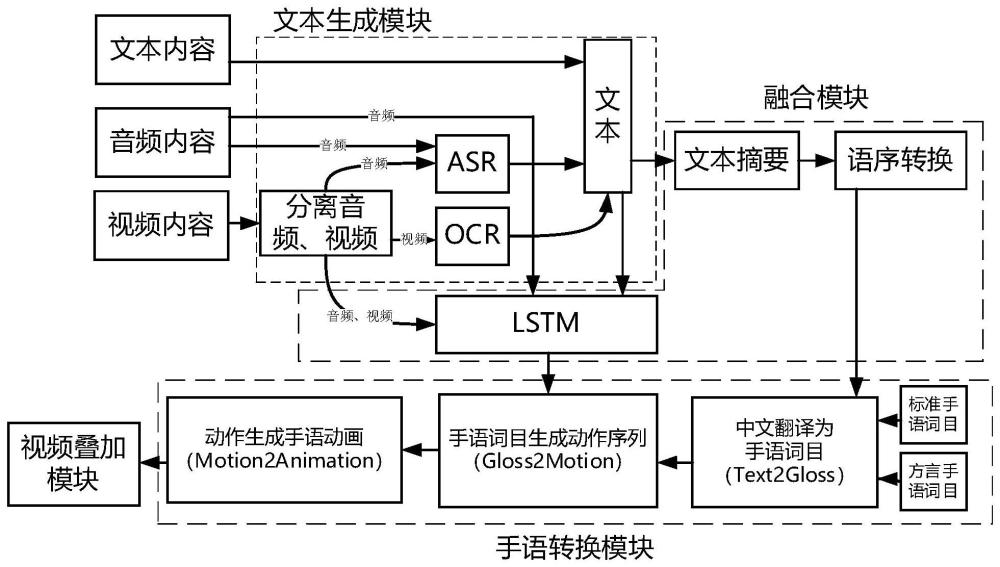
2、为了实现上述目的,本发明提供了一种基于多模态ai手语生成系统,其特征在于,包括:文本生成模块、融合模块、手语转换模块和视频叠加模块。
3、文本生成模块,通过ai技术获取输入的多模态内容,多模态内容包括:文本、音频或视频;将获取的视频字幕或音频转换为文本,与输入的音频、视频或文本共同输出;
4、融合模块,将文本生成模块输出的文本通过llm模型生成文本摘要,将文本摘要的自然语序转换为手语语序,分离出的音频、视频或文本和转换的文本通过情感计算进行情感融合;
5、手语转换模块,将手语语句按照词语查询动作库,生成手语动作序列;手语语句按照时间线查找对应的情感计算结果,生成头部表情动作;结合头部表情动作和生成的手语动作序列,生成虚拟数字人手语视频;动作库包括标准手语词目和方言手词目;
6、视频叠加模块,将虚拟数字人手语视频与原视频通过ffmpeg编码生成带有手语的视频。
7、优选的,文本生成模块的输入包括:文本输入、音频输入、视频输入、文本和音频输入、文本和视频输入;输入的视频包括:电影、电视剧、直播回放、短视频。
8、优选的,文本生成模块中,对输入的视频进行分离,分离后的音频或输入的音频采用asr将音频转换为文本;对分离后的视频采用ocr将视频中的字幕转换为文本。
9、优选的,融合模块中,文本转化为文本摘要时,将文本通过jieba分词,分词过程中先对句子进行分割,构成句子列表;根据句子列表对每个句子进行分词和标注后,对字母、时间用正则表达式进行分割;通过查询停止词库对停止词和修饰词进行过滤,以获得句子的摘要。
10、优选的,融合模块中,进行情感计算时,将文本进行向量变换和情感分类;将音频信息转换为频谱信息后通过卷积神经网络提取情感特征;将视频拆分为图像,关注人脸和肢体动作,再用含有时序的三维卷积神经网络提取情感特征。
11、优选的,文本、音频、视频提取的情感特征,采用多注意力机制的神经网络,进行情感模态的融合,融合后通过长短期记忆循环神经网络进行情感计算。
12、优选的,融合模块中,自然语序转换为手语语序时,先识别自然语序中句子的主谓宾和修饰词,按照虚词表省略虚词后,根据语序规则表进行语序转换。
13、优选的,ffmpeg进行编码时,需根据虚拟数字人手语视频和原视频的配置信息进行视频叠加,其配置信息包括:手语视频的时间线、手语视频的位置、手语视频窗大小、识别原视频码率、格式。
14、本发明还提供了一种基于多模态ai手语生成方法,具体生成步骤包括:
15、s1:文本生成步骤,通过ai技术获取输入的多模态内容,多模态内容包括:文本、音频或视频;将获取的视频字幕或音频转换为文本,与输入的音频、视频或文本共同输出;
16、s2:融合步骤,将文本生成步骤输出的文本通过llm模型生成文本摘要,并将文本摘要的自然语序转换为手语语序;同时将分离出的音频、视频或文本和转换的文本通过情感计算进行情感融合;
17、s3:手语转换步骤,将手语语句按照词语查询动作库,生成手语动作序列;且手语语句按照时间线查找对应的情感计算结果,生成头部表情动作;结合头部表情动作和生成的手语动作序列,生成虚拟数字人手语视频;动作库包括标准手语词目和方言手词目;
18、s4:视频叠加步骤,将虚拟数字人手语视频与原视频通过ffmpeg编码生成带有手语的视频。
19、优选的,文本生成步骤中输入的多模态内容为文本或文本和语音时,该手语生成方法中不包括步骤s4:视频叠加步骤。
20、本发明提供的一种基于多模态ai手语生成系统、方法的有益效果在于;通过ai技术生成数字虚拟人手语视频的方法,简化了制作手语视频的步骤,且也无需再拍摄和手语翻译的人员,降低了前期内容制作的成本,使手语视频的推广普及成为可能。本发明支持多模态内容输入,即包括文本、音频或视频作为手语视频生成的输入对象,扩展了手语视频生成的输入源。此外,本发明通过llm模型生成文本摘要的方式,抓住了内容制作对象的主要内容,还可通过视频主要内容使手语视频的速度适中,便于用户看清动作,同时使手语时间和语音时间基本相同,达到同步的效果。其次,本发明通过对将自然语序转换为手语语序,使最终生成的手语视频更贴合听障人士的表达习惯,为听障人士提供便利。除此之外,本发明对文本、音频和视频进行整合时,通过情感计算的方式使虚拟数字人还原原视频的情感,进一步增强手语的可理解度。同时,本发明将文本转换为手语的过程中,将方言形成的词目加入动作库中,与标准词目一起作为手语动作序列查询词语的依据,使手语更贴近听障人群的可理解的词目范围,增强亲和感和可理解度。
技术特征:
1.一种基于多模态ai手语生成系统,其特征在于,包括:
2.根据权利要求1所述的基于多模态ai手语生成系统,其特征在于,所述文本生成模块的输入包括:文本输入、音频输入、视频输入、文本和音频输入、文本和视频输入;所述输入的视频包括:电影、电视剧、直播回放、短视频。
3.根据权利要求2所述的基于多模态ai手语生成系统,其特征在于,所述文本生成模块中,对输入的视频进行分离,分离后的音频或输入的音频采用asr将音频转换为文本;对分离后的视频采用ocr将视频中的字幕转换为文本。
4.根据权利要求1所述的基于多模态ai手语生成系统,其特征在于,所述融合模块中,文本转化为文本摘要时,将文本通过jieba分词,分词过程中先对句子进行分割,构成句子列表;根据句子列表对每个句子进行分词和标注后,对字母、时间用正则表达式进行分割;通过查询停止词库对停止词和修饰词进行过滤,以获得句子的摘要。
5.根据权利要求4所述的基于多模态ai手语生成系统,其特征在于,所述融合模块中,进行情感计算时,将文本进行向量变换和情感分类;将音频信息转换为频谱信息后通过卷积神经网络提取情感特征;将视频拆分为图像,关注人脸和肢体动作,再用含有时序的三维卷积神经网络提取情感特征。
6.根据权利要求5所述的基于多模态ai手语生成系统,其特征在于,所述文本、音频、视频提取的情感特征,采用多注意力机制的神经网络,进行情感模态的融合,融合后通过长短期记忆循环神经网络进行情感计算。
7.根据权利要求1所述的基于多模态ai手语生成系统,其特征在于,所述融合模块中,自然语序转换为手语语序时,先识别自然语序中句子的主谓宾和修饰词,按照虚词表省略虚词后,根据语序规则表进行语序转换。
8.根据权利要求1所述的基于多模态ai手语生成系统,其特征在于,所述ffmpeg进行编码时,需根据虚拟数字人手语视频和原视频的配置信息进行视频叠加,其配置信息包括:手语视频的时间线、手语视频的位置、手语视频窗大小、识别原视频码率、格式。
9.一种根据权利要求1~8任一项所述的基于多模态ai手语生成方法,其特征在于,具体生成步骤包括:
10.根据权利要求9所述的基于多模态ai手语生成方法,其特征在于,所述文本生成步骤中输入的多模态内容为文本或文本和语音时,该手语生成方法中不包括步骤s4:视频叠加步骤。
技术总结
本发明提供的一种基于多模态AI手语生成系统、方法,其通过AI技术获取输入的多模态内容,将获取的视频字幕或音频转换为文本,与输入的音频、视频或文本共同输出;生成的文本通过LLM模型生成文本摘要,并将文本摘要的自然语序转换为手语语句;将分离出的音频、视频、文本和转换的文本通过情感计算进行情感融合,还原原视频情感;将手语语句按照词语查询动作库,动作库包括方言词目,增强了视频的亲和感和可理解度,生成手语动作序列;且按时间线查找对应的情感计算结果,生成头部表情动作;结合头部表情动作和手语动作序列,生成虚拟数字人手语视频,并对其进行渲染;最后将虚拟数字人手语视频与原视频通过FFmpeg编码生成带有手语的视频。
技术研发人员:沈子强,陆忠强,文太益,张佳仁,余龙,虞国祥
受保护的技术使用者:华数传媒网络有限公司
技术研发日:
技术公布日:2024/3/24
- 还没有人留言评论。精彩留言会获得点赞!