基于逆强化学习的多小区网络功率分配方法及系统
本发明涉及网络优化设计,具体为基于逆强化学习的多小区网络功率分配方法及系统。
背景技术:
1、近来,无线网络发展迅速,用户设备和传输数据量也急剧增加。为保证多小区网络中用户的服务质量(quality of service,qos),通过优化基站(bs)的发射功率来进行干扰抑制备受关注。
2、一般来说,传统的优化方法可以用于多小区网络的功率分配问题,然而,当网络规模较大时,传统优化方法的求解时间复杂度较高,难以部署在实际环境中。因此,如何实时地求解该问题对功率分配至关重要。
技术实现思路
1、(一)解决的技术问题
2、针对现有技术的不足,本发明提供了基于逆强化学习的多小区网络功率分配方法及系统,能在用户设备(ues)的最小数据速率要求的约束下找到最优的功率分配策略。
3、(二)技术方案
4、为实现以上目的,本发明通过以下技术方案予以实现:
5、第一方面,提供了一种基于逆强化学习的多小区网络功率分配方法,所述方法包括:
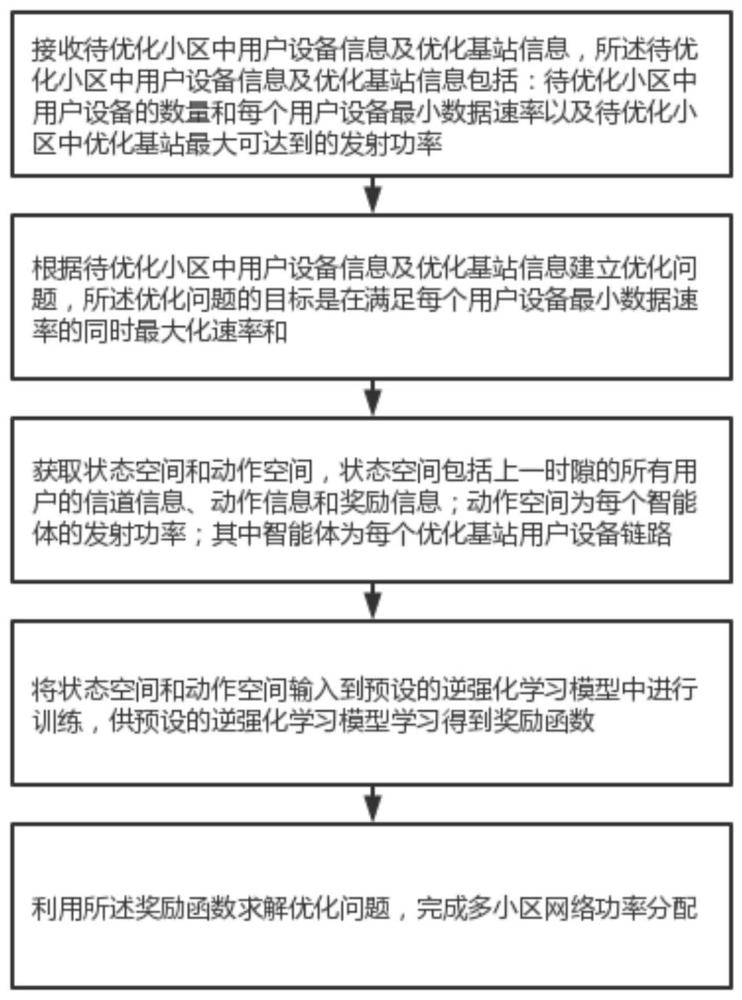
6、接收待优化小区中用户设备信息及优化基站信息,所述待优化小区中用户设备信息及优化基站信息包括:待优化小区中用户设备的数量和每个用户设备最小数据速率以及待优化小区中优化基站最大可达到的发射功率;
7、根据待优化小区中用户设备信息及优化基站信息建立优化问题,所述优化问题目标是在满足每个用户设备最小数据速率的同时最大化速率和;
8、获取状态空间和动作空间,所述状态空间包括上一时隙的所有用户的信道信息、动作信息和奖励信息;所述动作空间为每个智能体的发射功率;其中所述智能体为每个优化基站用户设备链路;
9、将状态空间和动作空间输入到预设的逆强化学习模型中进行训练,供预设的逆强化学习模型学习得到奖励函数;
10、利用所述奖励函数求解优化问题,完成多小区网络功率分配。
11、优选的,所述优化问题表示为:
12、
13、其中:n={1,2,…,n},k={1,2,…,k};pn,k代表第n个bs对其服务的第k个用户的发射功率;rn,k为第n个小区中第k个用户的速率;在p0中,约束rn,k≥r0表示每个用户的速率大于r0;约束0≤pn,k≤pmax意味着发射功率不小于0且不大于最大可达到的功率pmax。
14、优选的,每个用户的速率rn,k的计算公式如下:
15、
16、其中,hn,n,k代表第n个bs到第n个小区中第k个用户的信道增益,σ是噪声功率。
17、优选的,在将状态空间和动作空间输入到预设的逆强化学习模型中进行训练前,进行设置处理,所述设置处理包括设置最大训练轮数tmax、最大时隙数tslot和更新轮数tupdate。
18、优选的,在将状态空间和动作空间输入到预设的逆强化学习模型中进行训练前,进行初始化处理,所述初始化处理包括:初始化策略经验池、判别器网络参数θ、生成器网络参数ω和初始状态step=0。
19、优选的,在将状态空间和动作空间输入到预设的逆强化学习模型中进行训练的过程中,训练步骤包括:
20、步骤s1、初始化t=0,其中t表示时隙,进行如下步骤:
21、步骤s11、对每个智能体,利用生成器网络,输入智能体在时隙t的状态得到智能体的动作
22、步骤s12、与环境交互生成下一时隙的状态
23、步骤s13、将存储到策略经验池中;
24、步骤s14、t=t+1,若t<tslot,则重复步骤s12-s14,直至t>tslot;
25、步骤s2、如果则对神经网络进行更新;
26、步骤s3、step=step+1,若step<tmax,则重复步骤s1-s3,直至step>tmax;
27、训练周期结束后,得到生成器网络即功率分配策略,生成器网络的输出即为优化基站用户设备链路的发射功率。
28、优选的,所述对神经网络进行更新的步骤如下:
29、在专家经验池中随机取出专家轨迹其中,专家经验池中放入了状态空间和动作空间;
30、在策略经验池中随机取出策略轨迹τπ;
31、更新判别器网络参数,使用如下梯度:
32、
33、其中:dω为判别器网络,其输入为状态-动作对(s,a),输出为原始奖励;
34、更新生成器网络参数,使用如下梯度:
35、
36、其中:表示使用判别器网络计算的状态-动作价值,表示策略πθ的交叉熵。
37、第二方面,提供了一种基于逆强化学习的多小区网络功率分配系统,所述系统包括以下模块:
38、接收模块,用于接收待优化小区中用户设备信息及优化基站信息,所述待优化小区中用户设备信息及优化基站信息包括:待优化小区中用户设备的数量和每个用户设备最小数据速率以及待优化小区中优化基站最大可达到的发射功率;
39、建立模块,用于根据待优化小区中用户设备信息及优化基站信息建立优化问题,所述优化问题目标是在满足每个用户设备最小数据速率的同时最大化速率和;
40、获取模块,用于获取状态空间和动作空间,所述状态空间包括上一时隙的所有用户的信道信息、动作信息和奖励信息;所述动作空间为每个智能体的发射功率;其中所述智能体为每个优化基站用户设备链路;
41、训练模块,用于将状态空间和动作空间输入到预设的逆强化学习模型中进行训练,供预设的逆强化学习模型学习得到奖励函数;
42、求解模块,用于利用所述奖励函数求解优化问题,完成多小区网络功率分配。
43、第三方面,提供了一种存储一个或多个程序的计算机可读存储介质,所述一个或多个程序包括指令,所述指令当由计算设备执行时,使得所述计算设备执行所述的方法中的任一方法。
44、第四方面,提供了基于逆强化学习的多小区网络功率分配方法的一种计算设备,包括:
45、一个或多个处理器、存储器以及一个或多个程序,其中一个或多个程序存储在所述存储器中并被配置为由所述一个或多个处理器执行,所述一个或多个程序包括用于执行所述的方法中的任一方法的指令。
46、(三)有益效果
47、本发明基于逆强化学习的多小区网络功率分配方法及系统,存在qos约束的最大化和速率问题,并使用逆强化学习(irl)方法来学习神经网络形式的奖励函数并得到功率分配策略。首先使用传统优化方法作为专家策略得到专家数据,然后利用专家数据使用irl方法反推出隐藏的奖励函数,最后使用rl方法得到功率分配策略,从而充分考虑优化目标和约束,确保ue的最小瞬时数据速率的同时最大化速率和。
技术特征:
1.一种基于逆强化学习的多小区网络功率分配方法,其特征在于,所述方法包括:
2.根据权利要求1所述的一种基于逆强化学习的多小区网络功率分配方法,其特征在于:所述优化问题表示为:
3.根据权利要求2所述的一种基于逆强化学习的多小区网络功率分配方法,其特征在于:每个用户的速率rn,k的计算公式如下:
4.根据权利要求3所述的一种基于逆强化学习的多小区网络功率分配方法,其特征在于:在将状态空间和动作空间输入到预设的逆强化学习模型中进行训练前,进行设置处理,所述设置处理包括设置最大训练轮数tmax、最大时隙数tslot和更新轮数tupdate。
5.根据权利要求4所述的一种基于逆强化学习的多小区网络功率分配方法,其特征在于:在将状态空间和动作空间输入到预设的逆强化学习模型中进行训练前,进行初始化处理,所述初始化处理包括:初始化策略经验池、判别器网络参数θ、生成器网络参数ω和初始状态step=0。
6.根据权利要求5所述的一种基于逆强化学习的多小区网络功率分配方法,其特征在于:在将状态空间和动作空间输入到预设的逆强化学习模型中进行训练的过程中,训练步骤包括:
7.根据权利要求6所述的一种基于逆强化学习的多小区网络功率分配方法,其特征在于:所述对神经网络进行更新的步骤如下:
8.一种基于逆强化学习的多小区网络功率分配系统,其特征在于,所述系统包括以下模块:
9.一种存储一个或多个程序的计算机可读存储介质,其特征在于,所述一个或多个程序包括指令,所述指令当由计算设备执行时,使得所述计算设备执行根据权利要求1-7所述的方法中的任一方法。
10.一种基于逆强化学习的多小区网络功率分配方法的计算设备,其特征在于,包括:
技术总结
本发明提供基于逆强化学习的多小区网络功率分配方法及系统,涉及网络优化设计领域。该基于逆强化学习的多小区网络功率分配方法,包括:接收待优化小区中用户设备信息及优化基站信息;根据待优化小区中用户设备信息及优化基站信息建立优化问题,所述优化问题目标是在满足每个用户设备最小数据速率的同时最大化速率和;获取状态空间和动作空间,所述状态空间包括上一时隙的所有用户的信道信息、动作信息和奖励信息;将状态空间和动作空间输入到预设的逆强化学习模型中进行训练,供预设的逆强化学习模型学习得到奖励函数;利用所述奖励函数求解优化问题。该方法能在用户设备(UEs)的最小数据速率要求的约束下找到最优的功率分配策略。
技术研发人员:董瑞,熊轲,田兴聪,张锐晨
受保护的技术使用者:北京交通大学
技术研发日:
技术公布日:2024/2/21
- 还没有人留言评论。精彩留言会获得点赞!