一种基于人工智能引擎的频谱监测系统的加速方法
本发明属于通信和计算机领域,具体涉及一种基于人工智能引擎的频谱监测系统的加速方法。
背景技术:
1、随着无线电技术的发展,通信规模呈现海陆空一体化的发展趋势,设备也呈几何式增长。这使得频谱资源更加紧张拥挤,对频谱监测提出更大的挑战。而软件无线电可以结合不同的硬件与软件来实现不同功能,具有扩充性强,系统升级方便等特点,对频谱监测具有重要意义。
2、频谱监测的信号分析过程需要大量的并行计算。较于cpu而言,fpga具有高度并行化,低延迟,低功耗等特点,因此fpga被广泛应用于信号分析中。而对于软件开发者而言,在fpga上部署网络并非一件易事,而赛灵思推出的自适应计算加速平台为以高性能与低功耗为特点的计算与通信需求提供了解决方案。
3、人工智能引擎是推出为解决日益复杂的计算密集型应用(如5g蜂窝系统、机器学习dnn/cnn)的一种方案。人工智能引擎是基于自适应计算加速平台上开发的,该平台包含标量引擎(cpu)、可编程引擎(pl)、人工智能引擎(aie),并包含大量的工具、软件、库、框架等,降低了软件工程师的开发难度。
4、传统使用fpga进行频谱监测时,尽管其具有卓越的灵活性,却常常面临一些重要的技术挑战。一项主要挑战是在实施频谱检测算法时,需要大规模地使用快速傅里叶变换(fft)硬件ip核,这不仅占用了宝贵的硬件资源,还对系统性能造成了不小的负担。此外,对于fpga中可编程逻辑(pl)部分而言,频率限制也是一个极具挑战性的问题。当需要在不同的工作频率下运行时,就需要制定精确的定时约束,确保系统的各个部分能够协同工作。这不仅需要对fpga架构和设计有深刻的理解,还需要耗费大量时间和精力来重新约束系统,尤其是在系统参数发生变化时,这一工作显得尤为繁琐。
5、然而,当转向使用中央处理单元(cpu)来执行频谱监测任务时,虽然编程的门槛相对较低,但这种方法却存在着一系列显著的挑战。首先,cpu架构的本质使其在处理实时信号和高速数据流方面受到限制。这导致了监测速度相对较慢,难以满足复杂系统对于快速数据处理和实时性的迫切需求。
6、在人工智能引擎的开发模式中,采用了c/c++编程语言,这使开发者门槛较低。此外,人工智能引擎的硬件设计也具备显著的性能优势。其主频约为fpga主流器件的4倍,这意味着它能够以更高的时钟速度运行,实现更快的数据处理和计算。
技术实现思路
1、技术问题:针对日益复杂的通信环境,使用人工智能引擎方案进行频谱监测以满足低功耗、低延迟的要求。本发明提供一种基于人工智能引擎的频谱监测系统的加速方法,通过利用人工智能引擎的计算速度优势,实现了约5倍的加速效果,在时间上可以实现超过20倍的加速效果。
2、技术方案:本发明的目的是提供一种基于人工智能引擎的频谱监测系统的加速方法。该方法包括以下步骤:
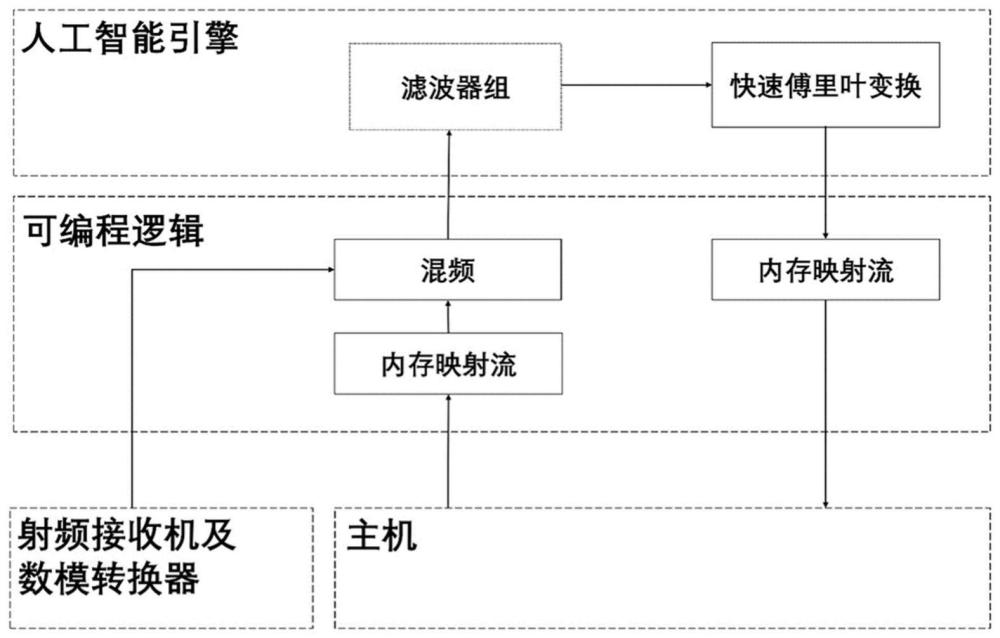
3、步骤1、对可编程逻辑内核进行开发;利用fpga工具从主机中提取模拟的数字中频信号作为输入信号并进行预处理,即实现内存映射流内核及混频,编译生成生成pl内核文件(.xo),输出信号为混频后的数字信号;
4、步骤2、对人工智能引擎进行开发;利用vitis工具对人工智能引擎进行核心算法的开发,即实现快速傅里叶变换功能,编译生成人工智能引擎计算图应用文件(libadf.a),输入的是步骤1输出的混频后的数字信号,其输出的是数字中频信号的频谱信息;
5、步骤3、将步骤1编译生成生成pl内核文件、步骤2编译生成人工智能引擎计算图应用文件进行链接并包装生成器件能够识别的二进制文件(.xclbin);
6、步骤4、编写主机程序并运行主机程序,编写主机程序,使得能够读取步骤3生成的二进制文件,并传入数据即模拟待处理的中频信号至器件中。
7、其中,
8、将步骤1中的pl内核文件、步骤2中的人工智能引擎计算图应用文件、以及包含pl内核接口与人工智能引擎接口连接的配置文件(.cfg),生成器件能够识别的二进制文件。
9、所述步骤2中输入的混频后的数字信号精度为8位实部+8位虚部的cint16,输入点数为2n,n从9到14。
10、所述步骤1对可编程逻辑内核进行开发;具体为使用高层次综合工具即hls,将c/c++代码转换为rtl设计,对内存映射流进行开发,并生成可编程逻辑pl内核对象文件,使用硬件描述语言hdl开发混频模块即直接数字合成模块以及复数乘数器模块,并生成可编程逻辑pl内核对象文件。
11、所述步骤2,对人工智能引擎进行开发;具体为使用c/c++语言对人工智能引擎内核进行开发,生成人工智能引擎计算图应用文件(libadf.a)。
12、所述步骤3,具体为指定配置文件用于连接各个pl内核对象文件以及人工智能引擎计算图应用,以及指定内核的名称,连接生成器件能够识别的二进制文件。
13、所述步骤4,编写主机程序并运行主机程序,具体为用c/c++语言编写驱动内核并从主机中导入数据至器件的全局存储器中。
14、有益效果:本项发明采用了人工智能引擎,与使用可编程逻辑进行频谱监测相比带来显著的性能提升。通过利用人工智能引擎的计算速度优势,实现了约5倍的加速效果,随着频率增加,传统可编程逻辑设计在处理高频信号时面临较大的设计难度,而人工智能引擎却能够轻松胜任。事实上,当人工智能引擎的运行主频约为pl主频的5倍时,在时间上可以实现超过20倍的加速效果,而快速傅里叶变换算法为频谱监测的核心算法,因此对频谱监测具有较好的加速效果。可以看出,随着信号规模的增大,系统在运行周期和处理时间方面都表现出明显的提升,这将大大提高频谱监测性能和效率。
技术特征:
1.一种基于人工智能引擎的频谱监测系统的加速方法,其特征在于,该方法包括以下步骤:
2.根据权利要求1所述的一种基于人工智能引擎的频谱监测系统的加速方法,其特征在于,将步骤1中的pl内核文件、步骤2中的人工智能引擎计算图应用文件、以及包含pl内核接口与人工智能引擎接口连接的配置文件(.cfg),生成器件能够识别的二进制文件。
3.根据权利要求1所述的一种基于人工智能引擎的频谱监测系统的加速方法,其特征在于,所述步骤2中输入的混频后的数字信号精度为8位实部+8位虚部的cint16,输入点数为2n,n从9到14。
4.根据权利要求1所述的一种基于人工智能引擎的频谱监测系统的加速方法,其特征在于,所述步骤1对可编程逻辑内核进行开发;具体为使用高层次综合工具即hls,将c/c++代码转换为rtl设计,对内存映射流进行开发,并生成可编程逻辑pl内核对象文件,使用硬件描述语言hdl开发混频模块即直接数字合成模块以及复数乘数器模块,并生成可编程逻辑pl内核对象文件。
5.根据权利要求1所述的一种基于人工智能引擎的频谱监测系统的加速方法,其特征在于,所述步骤2,对人工智能引擎进行开发;具体为使用c/c++语言对人工智能引擎内核进行开发,生成人工智能引擎计算图应用文件(libadf.a)。
6.根据权利要求1所述的一种基于人工智能引擎的频谱监测系统的加速方法,其特征在于,所述步骤3,具体为指定配置文件用于连接各个pl内核对象文件以及人工智能引擎计算图应用和指定内核的名称,连接生成器件能够识别的二进制文件。
7.根据权利要求1所述的一种基于人工智能引擎的频谱监测系统的加速方法,其特征在于,所述步骤4,编写主机程序并运行主机程序,具体为用c/c++语言编写驱动内核并从主机中导入数据至器件的全局存储器中。
技术总结
本发明公开了一种基于人工智能引擎的频谱监测系统的加速方法,包括人工智能引擎模块,可编程逻辑模块以及主机应用模块。该系统使用数字中频信号作为输入,通过可编程逻辑模块进行混频,进一步通过人工智能引擎进行滤波降采样率(可选)以及快速傅里叶变换算法模块。本发明通过合理结合人工智能引擎以及可编程逻辑模块,为应对不同算法需求的用户提升了使用空间。与传统的基于FPGA实现频谱监测方法相比,随着信号规模的增大,本发明可实现约二十倍的加速效果,具有很高的工程价值。
技术研发人员:张念祖,黄刚,高懿婷,陈程,薛心阳,洪伟
受保护的技术使用者:东南大学
技术研发日:
技术公布日:2024/2/29
- 还没有人留言评论。精彩留言会获得点赞!