一种基于演唱场景的实现方法及系统
本发明涉及视频播放优化,具体涉及一种基于演唱场景的实现方法及系统。
背景技术:
1、对于实际生活来说,经常会举行晚会、演唱会和音乐会等各种类型的演唱活动,而对于一些感兴趣却无法到达现场的观众来说,通过电视、网络等渠道观看实时转播是最为常见的方式。
2、现有的转播技术通常是将演唱场景的图像流和音频流传入到云数据服务器中,再由云数据服务器向用户进行视频流分发传输,其中,视频流传输需要占用大量的网络带宽,当用户的网络状况变差时,会出现转播画面卡顿、停顿的现象。
3、目前,现有技术在面对转播画面卡顿、停顿时,解决方法是音视频完全卡住,待网络正常后再继续播放,但这样的后果通常会丢失中间一段时间的音视频数据,使用户不能得到完整的内容,有的改进方案是优先保证音频传输,让用户能听到,但视频中断,待网络状况好的时候再传输视频,但这样仍然在这段时间无法让用户看到视频图像,破坏了用户的观看体验,导致用户实际体验感极低。
技术实现思路
1、本发明的目的在于提供一种基于演唱场景的实现方法及系统,解决以下技术问题:
2、现有技术在面对转播画面卡顿、停顿时,解决方法是音视频完全卡住,待网络正常后再继续播放,但这样的后果通常会丢失中间一段时间的音视频数据,使用户不能得到完整的内容,有的改进方案是优先保证音频传输,让用户能听到,但视频中断,待网络状况好的时候再传输视频,但这样仍然在这段时间无法让用户看到视频图像,破坏了用户的观看体验,导致用户实际体验感极低。
3、本发明的目的可以通过以下技术方案实现:
4、一种基于演唱场景的实现方法,包括以下步骤:
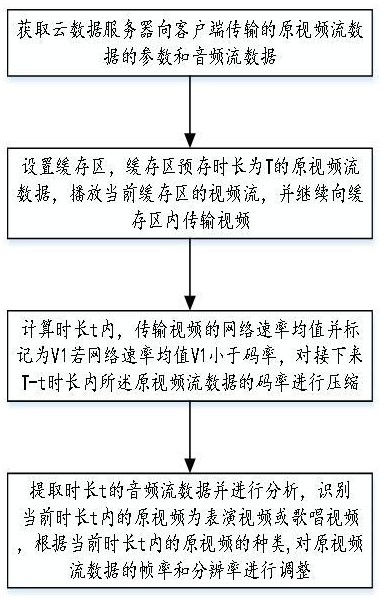
5、s1,获取云数据服务器向客户端传输的原视频流数据的参数和音频流数据;所述参数包括码率、帧率和分辨率;
6、s2,设置缓存区,缓存区预存时长为t的原视频流数据,播放当前缓存区内预存的视频流数据,并继续向缓存区内传输视频,计算时长t内,传输视频的网络速率均值并标记为v1;所述时长t小于预存时长t;
7、s3,若网络速率均值v1小于码率,对接下来t-t时长内所述原视频流数据的码率进行压缩,预设网络余量,将压缩后码率的值设置为当前网络速率均值与所设网络余量的差值;
8、s4,提取时长t的音频流数据并进行分析,预测识别当前时长t内的原视频为表演视频或歌唱视频,并根据当前时长t内的原视频的种类,分别对接下来t-t时长内原视频流数据的帧率和分辨率进行调整。
9、作为本发明进一步的方案:对音频流数据的分析过程为:
10、提取时长t的音频流数据并标记为待测音频流数据,将所述待测音频流按预设帧长进行分帧处理得到若干音频帧并标记为y1,y2,...,yn,n为正整数,采用线性预测编码分析处理后的每一帧音频流数据并提取音频特征,所述音频特征包括短时过零率、lpc预测系数和lpc预测残差幅度谱的偏度和峰度,根据所述音频特征形成特征向量,将所述特征向量带入预设识别支持向量模型,识别所述每一帧音频流数据中是否含有人声,若含有人声则将该音频帧标记为特殊音频帧并标记为q1,q2,...,qm,m为正整数,若m/n大于预设阈值,则判定时长t内的原视频为歌唱视频,若m/n小于预设阈值,则判定时长t内的原视频为表演视频。
11、作为本发明进一步的方案:若当前时长t内的原视频种类为歌唱视频,则优先对接下来t-t时长内原视频流数据的分辨率进行降低。
12、作为本发明进一步的方案:若当前时长t内的原视频种类为表演视频,则优先对接下来t-t时长内原视频流数据的帧率进行降低。
13、作为本发明进一步的方案:若网络速率均值v1大于码率,则保持接下来t-t时长内所述原视频流数据的码率,并对下一t时长内的原视频流数据的码率进行增大。
14、作为本发明进一步的方案:具体调整过程为:
15、计算压缩后的视频流数据码率与原视频流数据码率的比值,并标记为压缩比值,若当前时长t内的原视频为表演视频,则根据所述压缩比值对接下来t-t时长内原视频流数据的帧率进行相应压缩,若当前时长t内的原视频为歌唱视频,则根据所述压缩比值对接下来t-t时长内原视频流数据的分辨率进行相应压缩。
16、作为本发明进一步的方案:所述增加原视频流数据的码率的过程为:
17、获取当前网络传输速率vi和视频流数据的码率ki,计算网络传输速率均值vi与视频流数据的码率ki的差值并标记为p,在t时长内将当前视频流数据码率逐渐增加为ki+p。
18、一种基于演唱场景的实现系统,包括:
19、数据获取模块,用于获取云数据服务器向客户端传输的原视频流数据的参数和音频流数据;所述参数包括码率、帧率和分辨率;
20、数据处理模块,用于设置缓存区,缓存区预存时长为t的原视频流数据,播放当前缓存区的视频流,并继续向缓存区内传输视频,计算时长t内,传输视频的网络速率均值并标记为v1;所述时长t小于预存时长t;
21、结果生成模块,用于判断是否对当前视频码率进行修正,若网络速率均值v1小于码率,对接下来t-t时长内所述原视频流数据的码率进行压缩,预设网络余量,将压缩后码率的值设置为当前网络速率均值与所设网络余量的差值;
22、参数调整模块,用于提取时长t的音频流数据并进行分析,识别时长t内的原视频为表演视频或歌唱视频,并根据当前时长t内的原视频的种类,分别对接下来t-t时长内原视频数据的帧率和分辨率进行调整。
23、本发明的有益效果:本发明通过设置缓存区,提前获取并缓存一定时长的原视频流数据,得到缓存播放时间t,并计算时长t内的网络速率均值与当前视频流数据码率进行比较,若当前网络速率小于码率,则用户网络速率不足以支持当前直播视频流数据码率,则降低视频数据的码率,并根据提取的音频流数据进行分析,并识别当前时长t内的原视频是否为表演视频或歌唱视频,并根据预测结果,可以对接下来t-t时长内的原视频数据的帧率和分辨率进行调整,既确保了视频的流畅播放,又能够根据视频内容的特点,优化视频的展示效果,提升用户观看体验。
技术特征:
1.一种基于演唱场景的实现方法,其特征在于,包括以下步骤:
2.根据权利要求1所述的一种基于演唱场景的实现方法,其特征在于,若当前时长t内的原视频种类为歌唱视频,则优先对接下来t-t时长内原视频流数据的分辨率进行降低。
3.根据权利要求2所述的一种基于演唱场景的实现方法,其特征在于,若当前时长t内的原视频种类为表演视频,则优先对接下来t-t时长内原视频流数据的帧率进行降低。
4.根据权利要求1所述的一种基于演唱场景的实现方法,其特征在于,若网络速率均值v1大于码率,则保持接下来t-t时长内所述原视频流数据的码率,并对下一t时长内的原视频流数据的码率进行增大。
5.根据权利要求1所述的一种基于演唱场景的实现方法,其特征在于,具体压缩调整过程为:
6.根据权利要求4所述的一种基于演唱场景的实现方法,其特征在于,增大原视频流数据的码率的过程为:
7.一种基于演唱场景的实现系统,其特征在于,包括:
技术总结
本发明公开了一种基于演唱场景的实现方法及系统,属于视频播放优化技术领域,具体包括:获取云数据服务器向客户端传输的原视频流数据的参数和音频流数据;设置缓存区,缓存区预存时长为T的原视频流数据,播放当前缓存区的视频并继续向缓存区内传输视频,计算时长t内,传输视频的网络速率均值并标记为V1;若网络速率均值V1小于码率,对接下来T‑t时长内所述原视频流数据的码率进行压缩;识别时长t内的原视频为表演视频或歌唱视频,并根据原视频的种类分别对原视频数据的帧率和分辨率进行调整,本发明通过根据网速变化动态调整传输视频码率并根据视频类型分别制定不同的优化策略,实现了视频的流畅播放,提升播放体验。
技术研发人员:尹茂源,王天颖,潘栗,田野,杨睿,孙非,李心竹
受保护的技术使用者:牡丹江师范学院
技术研发日:
技术公布日:2024/1/25
- 还没有人留言评论。精彩留言会获得点赞!