一种分布式系统的低成本跟随者崩溃恢复方法
本发明涉及分布式系统,尤其涉及分布式系统的低成本跟随者崩溃恢复方法。
背景技术:
1、随着物联网、电子商务、社会化网络的快速发展,全球大数据储量迅猛增长,成为大数据产业发展的基础,分布式系统是由一组通过网络进行通信、为了完成共同的任务而协调工作的计算机节点组成的系统,目前许多大型平台都采用raft算法,现有许多工作也从不同方面优化raft。
2、经检索,申请号cn111586110a的中国专利,公开了一种raft在出现点对点故障时的优化处理方法,其指出了分布式系统重点对点的通信故障问题;
3、申请号cn116708460a的中国专利,公开了一种基于跟随者子群划分的raft共识优化方法,其指出了raft算法因而领导者节点必须处理比其他副本更多的消息,这样就会造成领导者节点负载过高,且在系统内部无法充分利用现有集群中其他节点的空闲资源的问题,并公开了公式优化授权,
4、然而,在一个实际的分布式存储系统中,不可能让节点中的日志无限增加,现有raft在处理写入请求时,需要两次写盘才能返回客户端,尽管相同键在相邻时间写入,raft中跟随者崩溃或失联会对领导者资源的无效消耗,跟随者重新加入集群中,领导者需要短时间消耗大量资源帮助跟随者恢复数据,以保证状态机间数据一致性,因此继续一种分布式系统的低成本跟随者崩溃恢复方法。
技术实现思路
1、本发明的目的是为了解决现有技术中存在的缺陷,而提出的分布式系统的低成本跟随者崩溃恢复方法。
2、为了实现上述目的,本发明采用了如下技术方案:
3、一种分布式系统的低成本跟随者崩溃恢复方法,包括以下步骤:
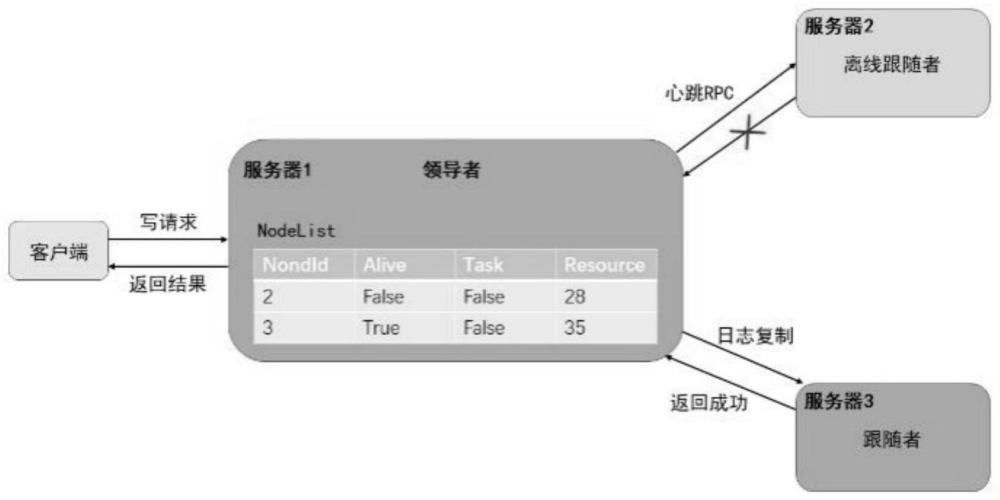
4、步骤1:基于raft协议构建nodelist结构,并修改重试机制;
5、步骤2:修改数据发送方式,建立恢复卸载机制,保证系统的稳定性;
6、步骤3:结合触发式重试和恢复卸载机制,构建有序的节点通信流程,优化raft协议。
7、进一步地,在步骤1中,修改的重试机制具体为:
8、步骤101:当新请求到达时,raft会尝试一次appendentries rpc,如果失败了并不会继续尝试;
9、步骤102:当心跳记录到节点上线后开始触发第二次尝试。
10、进一步地,步骤102中,触发式重试的具体流程为:
11、当领导者调用日志追加rpc或心跳rpc时,如果返回错误跟随者不可达,领导者则更新nodelist中的数据,更新对应节点的alive变量为false;
12、当跟随者节点非正常离线后,领导者不会无限期重试,而是当有新请求到达领导者时,领导者选择发送一次心跳rpc。
13、进一步地,恢复卸载机制的步骤流程为:
14、领导者通过nodelist选择状态最好的未执行任务的跟随者,将数据发送任务分发给它;
15、在接收到跟随者完成任务之前,领导者不会对缺失数据的跟随者发送数据;
16、跟随者接收到领导者的任务之后,通过核对身份确认是否接受任务,并返回给领导者;
17、跟随者将快照批量发送给指定跟随者节点,当完成了快照数12据的发送之后,跟随者会发送消息给领导者,告知其完成任务和最后一条日志的信息;
18、领导者能够开始正常的日志复制。
19、进一步地,nodelist的空间为预先分配,大小和节点数量相匹配,其中,nodelist中存储的节点基本信息,包括nodeid、alive、task和resource。
20、相比于现有技术,本发明的有益效果在于:
21、通过引入触发式重试机制,从而利用新请求到达触发心跳来实现跟随者节点监听,减少在跟随者节点崩溃时领导者无限期重试的代价;
22、通过引入恢复卸载机制,在过时跟随者节点上线时,领导者通过将数据恢复任务分发给强跟随者减少领导者压力,帮助跟随者快速恢复数据;
23、在有跟随者崩溃时依然可以提供高吞吐的服务,并且在多跟随者上线时可以更快的恢复数据。
技术特征:
1.一种分布式系统的低成本跟随者崩溃恢复方法,其特征在于,包括以下步骤:
2.根据权利要求1所述的分布式系统的低成本跟随者崩溃恢复方法,其特征在于,在步骤1中,修改的重试机制具体为:
3.根据权利要求2所述的分布式系统的低成本跟随者崩溃恢复方法,其特征在于,步骤102中,触发式重试的具体流程为:
4.根据权利要求3所述的分布式系统的低成本跟随者崩溃恢复方法,其特征在于,恢复卸载机制的步骤流程为:
5.根据权利要求4所述的分布式系统的低成本跟随者崩溃恢复方法,其特征在于,nodelist的空间为预先分配,大小和节点数量相匹配,其中,nodelist中存储的节点基本信息,包括nodeid、alive、task和resource。
技术总结
本发明公开了一种分布式系统的低成本跟随者崩溃恢复方法,包括以下步骤:步骤1:基于Raft协议构建NodeList结构,并修改重试机制;步骤2:修改数据发送方式,建立恢复卸载机制,保证系统的稳定性;步骤3:结合触发式重试和恢复卸载机制,构建有序的节点通信流程,优化Raft协议。通过引入触发式重试机制,从而利用新请求到达触发心跳来实现跟随者节点监听,减少在跟随者节点崩溃时领导者无限期重试的代价;通过引入恢复卸载机制,在过时跟随者节点上线时,领导者通过将数据恢复任务分发给强跟随者减少领导者压力,帮助跟随者快速恢复数据;在有跟随者崩溃时依然可以提供高吞吐的服务,并且在多跟随者上线时可以更快的恢复数据。
技术研发人员:周凤林,林子雨
受保护的技术使用者:厦门大学
技术研发日:
技术公布日:2024/3/27
- 还没有人留言评论。精彩留言会获得点赞!