一种网关数据智能优化方法与流程
本发明涉及数据压缩,具体涉及一种网关数据智能优化方法。
背景技术:
1、随着互联网的发展,大数据时代已经来临,无论是互联网还是本地服务器,时时刻刻需要进行数据的传输和存储,而设备接收到的原始数据的数据量巨大,在传输和保存过程中占用大量的带宽和空间,随着数据量的增大传输时间也成倍增加,因此衍生了一些数据压缩算法。
2、lz系列算法是一种能对数据进行无损压缩的算法,其原理是通过一个动态窗口对数据流进行滑动,窗口分为先行缓冲区和查找缓冲区,查找缓冲区相较于先行缓冲区大得多,在滑动过程中将先行缓冲区的字符使用查找缓冲区偏移量和匹配长度表示,以达到减少存储空间的目的。对于lz系列算法来说,窗口越大,压缩效果越好,但压缩时消耗的时间就越长,压缩效率越低,因此时间成本更高。
技术实现思路
1、为了解决现有的lz系列算法在对数据流进行压缩时存在的压缩效率较低的问题,本发明的目的在于提供一种网关数据智能优化方法,所采用的技术方案具体如下:
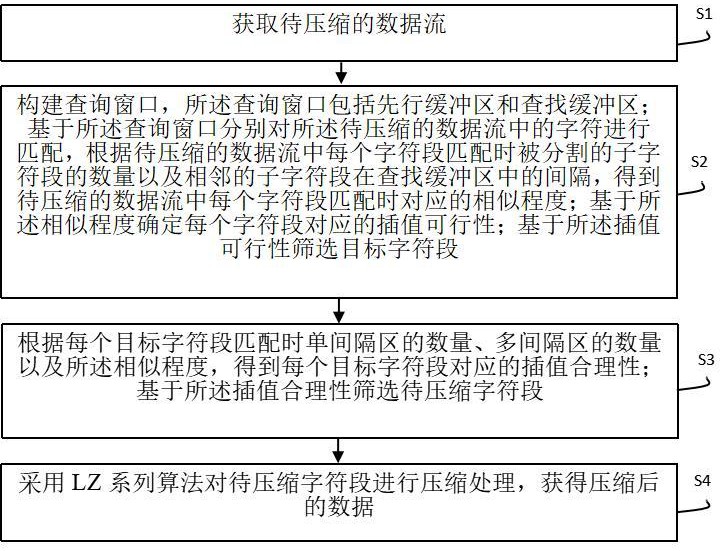
2、本发明提供了一种网关数据智能优化方法,该方法包括以下步骤:
3、获取待压缩的数据流;
4、构建查询窗口,所述查询窗口包括先行缓冲区和查找缓冲区;基于所述查询窗口分别对所述待压缩的数据流中的字符进行匹配,根据待压缩的数据流中每个字符段匹配时被分割的子字符段的数量以及相邻的子字符段在查找缓冲区中的间隔,得到待压缩的数据流中每个字符段匹配时对应的相似程度;基于所述相似程度确定每个字符段对应的插值可行性;基于所述插值可行性筛选目标字符段;
5、根据每个目标字符段匹配时单间隔区的数量、多间隔区的数量以及所述相似程度,得到每个目标字符段对应的插值合理性;基于所述插值合理性筛选待压缩字符段;
6、采用lz系列算法对待压缩字符段进行压缩处理,获得压缩后的数据。
7、优选的,所述根据待压缩的数据流中每个字符段匹配时被分割的子字符段的数量以及相邻的子字符段在查找缓冲区中的间隔,得到待压缩的数据流中每个字符段匹配时对应的相似程度,包括:
8、对于待压缩的数据流中第n个字符段:
9、对于第n个字符段匹配时相邻的子字符段在查找缓冲区中的第m个间隔:将第m个间隔的长度与第n个字符段的总长度的比值,作为第m个间隔占比;
10、根据待压缩的数据流中第n个字符段匹配时相邻的子字符段在查找缓冲区中的所有间隔占比以及被分割的子字符段的数量,得到第n个字符段匹配时对应的相似程度。
11、优选的,采用如下公式计算第n个字符段匹配时对应的相似程度:
12、;
13、其中,en为第n个字符段匹配时对应的相似程度,k为第n个字符段匹配时被分割的子字符段的数量,xi为相邻的子字符段在查找缓冲区中的第m个间隔的长度,ln为第n个字符段的总长度,e为自然常数。
14、优选的,所述基于所述相似程度确定每个字符段对应的插值可行性,包括:
15、若所述相似程度大于预设相似程度阈值,则令对应字符段对应的插值可行性为预设第一数值;
16、若所述相似程度小于或等于预设相似程度阈值,则令对应字符段对应的插值可行性为预设第二数值;
17、所述预设第一数值大于所述预设第二数值。
18、优选的,基于所述插值可行性筛选目标字符段,包括:
19、将插值可行性为预设第一数值的字符段,作为目标字符段。
20、优选的,所述根据每个目标字符段匹配时单间隔区的数量、多间隔区的数量以及所述相似程度,得到每个目标字符段对应的插值合理性,包括:
21、对于第a个目标字符段:
22、将第a个目标字符段匹配时多间隔区的数量的二倍记为第一特征值;将所述第一特征值、常数2、第a个目标字符段配时单间隔区的数量三者的和值,确定为第a个目标字符段配时确定第a个目标字符段压缩后的长度;
23、基于第a个目标字符段压缩后的长度与原长度之间的差异以及第a个目标字符段匹配时对应的相似程度,获得第a个目标字符段对应的插值合理性。
24、优选的,基于第a个目标字符段压缩后的长度与原长度之间的差异以及第a个目标字符段匹配时对应的相似程度,获得第a个目标字符段对应的插值合理性,包括:
25、计算第a个目标字符段压缩后的长度与第a个目标字符段原长度之间的比值,计算常数1与所述比值之间的差值;
26、将所述差值与第a个目标字符段匹配时对应的相似程度的乘积,确定为第a个目标字符段对应的插值合理性。
27、优选的,所述基于所述插值合理性筛选待压缩字符段,包括:
28、将插值合理性大于预设合理性阈值的目标字符段,确定为待压缩字符段。
29、优选的,所述采用lz系列算法对待压缩字符段进行压缩处理,获得压缩后的数据,包括:
30、任一待压缩字符段在采用lz系列算法进行压缩处理时,元组保存数据的格式具体为:(偏移量,单字符,匹配长度,插值量,插值长度)。
31、优选的,采用lz系列算法对所述待压缩的数据流中的字符进行匹配。
32、本发明至少具有如下有益效果:
33、本发明首先对待压缩的数据流中的字符进行匹配,根据待压缩的数据流中每个字符段匹配时被分割的子字符段的数量以及相邻的子字符段在查找缓冲区中的间隔,得到待压缩的数据流中每个字符段匹配时对应的相似程度,相似程度越小,说明需要插值的地方越多,即需要编码器计算的时长越长,因此本发明进一步基于相似程度确定每个字符段对应的插值可行性,进而筛选出目标字符段,根据每个目标字符段匹配时单间隔区的数量、多间隔区的数量以及相似程度,得到了每个目标字符段对应的插值合理性,插值合理性越大的目标字符段在进行压缩处理时,计算时间越短,压缩处理后更节省空间,因此本发明基于插值合理性筛选出了待压缩字符段,采用lz系列算法对待压缩字符段进行压缩处理,以达到将多个字符融合为一个字符的效果,保证压缩效果的同时提高了压缩效率。
技术特征:
1.一种网关数据智能优化方法,其特征在于,该方法包括以下步骤:
2.根据权利要求1所述的一种网关数据智能优化方法,其特征在于,所述根据待压缩的数据流中每个字符段匹配时被分割的子字符段的数量以及相邻的子字符段在查找缓冲区中的间隔,得到待压缩的数据流中每个字符段匹配时对应的相似程度,包括:
3.根据权利要求2所述的一种网关数据智能优化方法,其特征在于,采用如下公式计算第n个字符段匹配时对应的相似程度:
4.根据权利要求1所述的一种网关数据智能优化方法,其特征在于,所述基于所述相似程度确定每个字符段对应的插值可行性,包括:
5.根据权利要求4所述的一种网关数据智能优化方法,其特征在于,基于所述插值可行性筛选目标字符段,包括:
6.根据权利要求1所述的一种网关数据智能优化方法,其特征在于,所述根据每个目标字符段匹配时单间隔区的数量、多间隔区的数量以及所述相似程度,得到每个目标字符段对应的插值合理性,包括:
7.根据权利要求6所述的一种网关数据智能优化方法,其特征在于,基于第a个目标字符段压缩后的长度与原长度之间的差异以及第a个目标字符段匹配时对应的相似程度,获得第a个目标字符段对应的插值合理性,包括:
8.根据权利要求1所述的一种网关数据智能优化方法,其特征在于,所述基于所述插值合理性筛选待压缩字符段,包括:
9.根据权利要求1所述的一种网关数据智能优化方法,其特征在于,所述采用lz系列算法对待压缩字符段进行压缩处理,获得压缩后的数据,包括:
10.根据权利要求1所述的一种网关数据智能优化方法,其特征在于,采用lz系列算法对所述待压缩的数据流中的字符进行匹配。
技术总结
本发明涉及数据压缩技术领域,具体涉及一种网关数据智能优化方法。方法包括:获取待压缩的数据流;基于查询窗口对待压缩的数据流中的字符进行匹配,根据待压缩的数据流中每个字符段匹配时被分割的子字符段的数量以及相邻的子字符段在查找缓冲区中的间隔,得到待压缩的数据流中每个字符段匹配时对应的相似程度;基于相似程度确定每个字符段对应的插值可行性,进而筛选目标字符段;根据每个目标字符段匹配时单间隔区的数量、多间隔区的数量以及相似程度,得到每个目标字符段对应的插值合理性,进而筛选待压缩字符段;采用LZ系列算法对待压缩字符段进行压缩处理,获得压缩后的数据。本发明在保证数据流压缩效果的同时提高了压缩效率。
技术研发人员:曲宝春,王玲兰,张斌
受保护的技术使用者:苏州爱雄斯通信技术有限公司
技术研发日:
技术公布日:2024/4/24
- 还没有人留言评论。精彩留言会获得点赞!