基于联邦深度学习的边缘缓存优化方法与流程
本发明涉及深度强化学习算法,具体而言,涉及一种基于联邦深度学习的边缘缓存优化方法。
背景技术:
1、在现代计算机系统技术环境中,联邦学习和深度强化学习在处理大规模分布式数据时发挥着重要作用。联邦学习,作为一种分布式机器学习方法,允许多个设备共同训练一个模型,同时保证数据的本地化处理和数据隐私的保护。深度强化学习,结合了深度学习的特征提取能力和强化学习的决策优化能力,是解决复杂决策问题的关键技术。边缘缓存是一种新兴的技术,是一种分布式网络框架,其中数据和应用服务提供商将服务器的处理能力转移到尽可能靠近最终用户的地方,旨在通过在网络边缘存储内容来减轻中心服务器的负载和降低延迟,这在需要快速响应和大量数据交换的场景中尤其重要。在实现本发明的过程中,申请人发现:传统的边缘缓存机制局限于为同构内容类型设计缓存算法,主要关注单模态数据,忽略了对多种模态数据处理的现实需求,无法对其进行有效处理,这些传统策略无法充分捕捉多模态数据的细微差别,导致性能和用户体验不理想。
技术实现思路
1、本发明旨在至少解决现有技术或相关技术中存在的技术问题之一,公开了一种基于联邦深度学习的边缘缓存优化方法,通过多模态数据特征融合,进行边缘缓存,减少网络资源消耗。
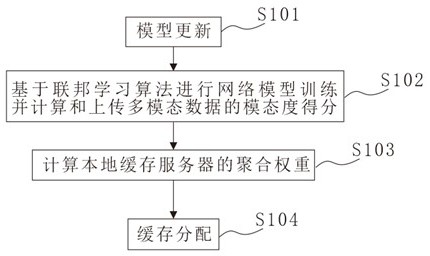
2、本发明的第一方面公开了一种基于联邦深度学习的边缘缓存优化方法,包括:本地缓存服务器接收基站发送的深度强化学习模型参数进行模型更新,以便本地深度强化学习模型与所述基站和云服务器共同进行多轮次的联邦深度强化训练,期间,本地缓存服务器接收终端设备的请求内容,计算请求内容的模态度得分,以便基站收集并上传模态度得分和通过多轮次训练后得到的深度学习网络模型参数至云服务器;云服务器根据模态度得分计算每一个本地缓存服务器的聚合权重;云服务器根据聚合权重进行内容的缓存分配;其中,计算请求内容的模态度得分的步骤具体包括:接收请求内容,请求内容为多模态数据,至少包括图片数据和文本数据;根据多模态数据生成嵌入向量;通过快速卷积模型对输入的多个文本向量和图片向量进行一维最大池化卷积,分别得到图片张量和文本张量;将图片张量数据和文本张量数据输入至神经网络模型,以获取图片特征和文本特征;将文本向量和图片向量通过一个与leakyrelu耦合的共享全连接层投射到同一语义空间内,得到图片向量的对齐表示以及文本向量的对齐表示;根据图片向量的对齐表示以及文本向量的对齐表示得到变分后验的表示,之后通过学习kullback-leibler散度来计算歧义评分,将平均kullback-leibler散度作为不同模态的模态度评分;通过计算文本对图片的交互向量以及图片对文本的交互向量,最终将单模态特征和多模态特征在模态度的引导下自适应链接,以形成模态度得分。
3、在该技术方案中,对多模态数据进行多模态融合从而形成模态度得分,进而指导服务器的缓存分配策略。多模态数据融合主要包括如下步骤:模态对齐:利用leakyrelu把不同模态下的特征嵌入表达到一个统一的语义空间中;模态融合:利用kullback-leibler(kl)散度进行相似度度量,然后从系统的角度进行求和平均,最终利用平均kl散度求得系统内任意内容的模态度得分。具体地,模态对齐是通过使用leakyrelu激活函数来实现的,该函数用于将不同模态的特征嵌入和表达到统一的语义空间中。这种嵌入过程可确保特征(无论其原始模态如何)以保留其语义意义的方式表示,同时促进模态间兼容性。对齐后,利用kl散度进行模态融合,以定量评估对齐特征之间的相似性。融合过程涉及通过求和与平均对特征进行系统聚合,特别关注系统的整体视角。此过程的最终结果是计算平均kl散度,从而得出系统内任何给定内容的模态度得分。
4、根据本发明公开的基于联邦深度学习的边缘缓存优化方法,优选地,生成嵌入向量的步骤,具体包括:采用google发布的bert模型以及resnet模型对多模态数据进行处理,以获取嵌入向量。
5、根据本发明公开的基于联邦深度学习的边缘缓存优化方法,优选地,还包括:基站将深度强化学习模型参数传递给本地缓存服务器后,本地缓存服务器使用收到的参数对自身的深度强化学习模型和数据进行训练,然后进行联邦学习对终端设备的深度强化学习模型和基站内的深度强化学习模型进行升级。
6、根据本发明公开的基于联邦深度学习的边缘缓存优化方法,优选地,联邦深度强化训练基于fedavg联邦学习算法进行训练。
7、根据本发明公开的基于联邦深度学习的边缘缓存优化方法,优选地,深度强化学习模型为dqn深度强化学习模型。
8、根据本发明公开的基于联邦深度学习的边缘缓存优化方法,优选地,终端设备为用户设备,包括可穿戴设备、手机、平板电脑和个人计算机。
9、本发明的有益效果至少包括:通过本发明可以在边缘缓存场景中,应用多模态特征融合结合联邦深度强化学习提供了一个高度先进和有效的解决方案。通过多模态特征融合,系统能够综合不同类型的数据(如图像、音频、文本等),从而获得更丰富、更准确的环境理解和用户行为预测。联邦学习确保这些数据在本地处理,保护用户隐私,而深度强化学习则用于优化边缘缓存策略,如智能决定哪些数据应被缓存或移除,以提高缓存效率和降低访问延迟。这种集成方法使得边缘缓存系统不仅更加智能和响应迅速,同时也对用户数据的隐私性和系统的整体安全性更加敏感和尊重。
技术特征:
1.一种基于联邦深度学习的边缘缓存优化方法,其特征在于,包括:
2.根据权利要求1所述的基于联邦深度学习的边缘缓存优化方法,其特征在于,生成所述嵌入向量的步骤,具体包括:
3.根据权利要求1所述的基于联邦深度学习的边缘缓存优化方法,其特征在于,还包括:所述基站将深度强化学习模型参数传递给所述本地缓存服务器后,所述本地缓存服务器使用收到的参数对自身的深度强化学习模型和数据进行训练,然后进行联邦学习对终端设备的深度强化学习模型和基站内的深度强化学习模型进行升级。
4.根据权利要求1所述的基于联邦深度学习的边缘缓存优化方法,其特征在于,所述联邦深度强化训练基于fedavg联邦学习算法进行训练。
5.根据权利要求1所述的基于联邦深度学习的边缘缓存优化方法,其特征在于,所述深度强化学习模型为dqn深度强化学习模型。
6.根据权利要求1所述的基于联邦深度学习的边缘缓存优化方法,其特征在于,所述终端设备为用户设备,包括穿戴式设备、手机、平板电脑和个人计算机。
技术总结
本发明提供了一种基于联邦深度学习的边缘缓存优化方法,涉及深度强化学习算法,包括:本地缓存服务器接收基站发送的深度强化学习模型参数进行模型更新,以便本地深度强化学习模型与基站和云服务器共同进行多轮次的联邦深度强化训练,期间,本地缓存服务器接收终端设备的请求内容,计算请求内容的模态度得分,以便基站收集并上传模态度得分和通过多轮次训练后得到的深度学习网络模型参数至云服务器;云服务器根据模态度得分计算每一个本地缓存服务器的聚合权重;云服务器根据聚合权重进行内容的缓存分配。本发明通过对多模态数据进行特征融合,进而进行边缘缓存,减少网络资源消耗。
技术研发人员:冯为嘉,左心宇,田怡,张偌嘉,朱逸宸,樊越
受保护的技术使用者:精为技术(天津)有限公司
技术研发日:
技术公布日:2024/4/29
- 还没有人留言评论。精彩留言会获得点赞!