一种基于声学信息的梅山猪发情监测方法与流程
本发明属于动物发情监测技术领域,具体涉及一种基于声学信息的梅山猪发情监测方法。
背景技术:
近年来,随着生猪和母猪产业结构调整,养殖业向着规模化、高效化、智能化、集约化的方向快速迈进,对母猪发情的及时监测提出了更高的要求。发情监测在猪场管理中具有重要地位,在母猪发情时进行授精可以大幅度提升其受孕几率,从而发挥动物的繁殖潜力,提高经济效益。母猪发情监测一般可分为两大类。一类是传统方法,主要有外部观察法、阴道黏膜黏液检查法、静立反射检查法、公猪试情法。目前我国大部分猪场仍采用传统方式进行发情监测,这种监测方法存在耗时长、耗力大且很难鉴定隐性发情问题,已经不适应大规模、集约化的养殖方式。另一类为针对母猪发情期行为和温度变化的数字化监测技术。汪开英等在一家母猪试验场中运用红外传感器实时监测母猪的发情行为,根据母猪的日平均活动量进行发情鉴定,准确率为84.2%;ostersen等采用rfid技术监测6h内母猪与公猪互相亲近持续时间及频率,实现母猪发情的自动监测;v.g.simes等利用红外热成像技术来研究母猪发情前与发情期的外阴部温度与排卵之间的关系,发现母猪发情前外阴部温度开始升高,达到峰值后逐渐降低,发情后6~12h达到最低,而发情前后臀部温度差异不显著,并提出根据阴部温度来判断排卵时间具有一定的可行性,但存在监测步骤繁琐、准确率低等问题。
动物声音能反映出动物的生理状况,如饥饿、疼痛等,以及外部因素对动物机体所造成的应激。有经验的养殖人员可以通过动物的叫声了解动物当时的生理及健康状况。随着语音信号处理与识别技术的发展,基于声音信息的动物发情监测技术得到了发展。潘载扬通过研究发情期大熊猫的7种叫声类型和幼体大熊猫的3种叫声类型,分析了大熊猫声音通讯在配偶判别和亲代哺育过程中的作用;ghung等提出一种数据挖掘算法从奶牛叫声中提取梅尔频率倒谱系数用于奶牛发情监测,准确性大于94%,且系统成本低,可实现无接触、实时监测。目前基于声音信息的母猪发情监测方面的研究还很薄弱,对猪声音的研究主要集中在关系猪健康状态和福利化养殖评价的猪咳嗽声、哺乳声上,在猪发情监测上的应用鲜有报道。1958年,grauvogla最早对猪发声进行了研究,并区分了23种不同的猪发声类别。张俊辉等研究了猪听觉的形成原理、声音的特征、母猪与仔猪间声音的联系及声音对断奶仔猪生产性能和行为的影响,为进一步缓解断奶应激、提高猪的生产性能寻找新的路径。徐亚妮利用模糊c均值聚类算法进行待产梅山猪咳嗽声与尖叫声识别,识别率分别达到83.4%和83.1%;闫丽等以小梅山母猪的哺乳声、饮水声、采食声及无食咀嚼声为对象,采用偏度聚类的方法对特征参数降维,构建支持向量机的声音分类识别器,识别率达96.61%以上,实现了对哺乳母猪的母性能力及其健康状况的无应激、实时监测;德国的dummerstorf家畜生物学研究所,将其所进行的监测与识别猪发声信息技术方面的研究成果应用到其研发的应用软件中,使用该软件及配套设备可以判断猪的应激反应,甚至可以准确预告母猪的发情期。因此,采用基于声音信号的母猪发情监测是可行的。
梅山猪属于中国优良地方品种太湖猪中的一个主要品系,以产仔多、繁殖性能优良而为国内外所重视,是经济杂交或培育新品种的最大优良亲本,被誉为“世界级产仔冠军。本发明以梅山猪为研究对象,采集梅山猪发情声及猪场环境中的打喷嚏、吃食、尖叫、哼哼和甩耳朵声5种非发情声数据,利用时频分析方法分析梅山猪发情声的时频域特征,寻找能够代表梅山猪发情声特点的特征参数;将深度信念网络(deepbeliefnets,dbn)引入猪发情声识别领域,构建猪场环境中梅山猪的发情声识别模型,为母猪发情检测提供了一种新的方法。
技术实现要素:
为了实现对母猪发情时间的准确判断,并克服现有发情监测方法的缺点,本发明提出了一种基于声音的梅山猪发情监测方法。
本发明技术方案:
一种基于声学信息的梅山猪发情监测方法,所述方法包括以下步骤:
步骤1:通过放置在猪栏处的录音设备,采集梅山猪发情时产生的声音信号,同时采集猪场环境中梅山猪和长白猪的打喷嚏、吃食、尖叫、哼哼、甩耳朵声音信号;
步骤2:基于小波阈值多窗谱的维纳语音增强对步骤1采集的猪声音信号进行预处理,实现猪声音信号的去噪,得到去噪后的猪声信号;
步骤3:利用基于短时能量的双门限端点检测方法对步骤2去噪后的猪声信号进行有效信号的提取,得到有效的猪声信号;
步骤4:对步骤3的有效的猪声信号进行时频特征分析,确定声音信号的持续时长、能量分布和频率分布;
步骤5:在步骤4的时频特征分析基础上,对有效猪声信号进行声音特征提取,声音特征指标包括短时能量、短时过零率、基于6层小波包分解的子带频段能量比、梅尔频率倒谱系数;
步骤6:对所述步骤5中提取的声音特征参数,采用深度信念网络建立梅山猪发情声识别模型;
步骤7:按训练集和测试集4:1的比例,利用步骤6中建立的梅山猪发情声识别模型进行识别验证,并进行5折交叉验证,确定识别效果;
完成梅山猪发情声的识别。
优选地,所述步骤4梅山猪发情时的嚎叫声单次时间持续1.8-2.2s,打喷嚏和甩耳朵声时间持续0.38-0.42s,尖叫、哼哼时间持续0.6~1.4s,单脉冲吃食声时间持续0.09-0.11s;
所述梅山猪发情声在时域和频域上呈现两段分布,能量集中分布于500~1500hz和2500~5500hz这两个频段,且两个频段之间能量有一个较大的回落;单脉冲吃食声时间较短,频谱分布于1000~10000hz的较宽频段;打喷嚏、尖叫声、甩耳朵和哼哼声频率主峰均位于3000~4000hz频段,其中哼哼声频率分布于2000~3500hz的较窄频带。
优选地,所述步骤5声音特征提取前采用时间规整算法将声音信号规整为相同维数的特征向量后再进行特征提取。
优选地,所述步骤5中,短时能量和短时过零率均为300维,梅尔倒谱系数为720维,基于6层小波包分解的子带频段能量比提取时,选取32维子带频段能量比。
优选地,所述步骤6深度信念网络建立了一个5层的深度信念网络梅山猪发情声识别模型,采用非监督贪婪算法逐层预训练多层受限玻尔兹曼机(rbm)的网络结构并采用误差反向传播算法(bp)进行整体微调的方式调整权值;设定了50个样本的小批量数据包的训练模式,学习率为0.1,权损失系数为0.0002,能够获取收敛较优的梅山猪发情声识别模型。
优选地,所述步骤7中,采用5折交叉验证法来对识别效果进行验证,即将梅山猪发情声与非发情声样本平均分成5等份,然后按照训练集与测试集4:1的比例分成5组,轮流去做训练和测试,循环5次。
优选地,所述步骤7,单个参数识别效果由高到低依次为梅尔倒谱系数、子带频段能量比、短时能量、短时过零率;组合参数识别效果最优为梅尔倒谱系数和子带频段能量比的特征组合。
本发明有益效果如下:
1、本发明通过对猪声音信号的时频分析,确定了梅山猪发情声的特征参数,建立的深度信念网络识别模型,实现了梅山猪发情声的自动无损监测,提高了监测效率,降低了劳动成本;
2、应用本发明建立的梅山猪发情声识别方法,可以实现母猪发情监测过程中母猪的在线发情监测,总识别率最高为97.50%,因此,本发明可以帮助猪场管理者提高猪场管理的信息化水平,也为母猪发情监测提供了一种新的自动无应激的方法。
3、所述步骤5中,基于6层小波包分解的子带频段能量比提取时,选取32维子带频段能量比,梅尔倒谱系数为720维。采集声音信号样本的采样频率为48000hz,则奈奎斯特频率为24000hz,而梅山猪的各类生理声音信号的主要频率成分为12000hz以下的频率部分。由小波包分解树节点与信号子空间频段的对应关系知,0~12000hz对应频段1~32。梅山猪发情声音信号能量主要集中在低频段,计算选取的32个频段能量占总能量的95.15%;舍弃高频部分的频段使特征维数由64降为32,减少了运算量,同时也起到了一定的低通滤波效果。对于一个300帧的猪发情声样本,24维的mfcc数据量是比较大的,因此采用时间规整算法将300帧的mfcc参数规整到30帧组成720维的mfcc特征向量。数据量大大减少,同时,也保留了在时序上的动态变化特性。
附图说明
图1猪场环境噪声分析:(a)环境噪声波形图、(b)环境噪声频谱图、(c)猪发情叫声波形图(d)猪发情叫声频谱图;
图2猪发情声音样本滤波后波形图:(a)梅山猪发情声波形、(b)梅山猪发情声频谱;
图3猪发情声样本端点检测:(a)猪发情声样本端点检测示意图、(b)端点检测后猪发情声样本波形;
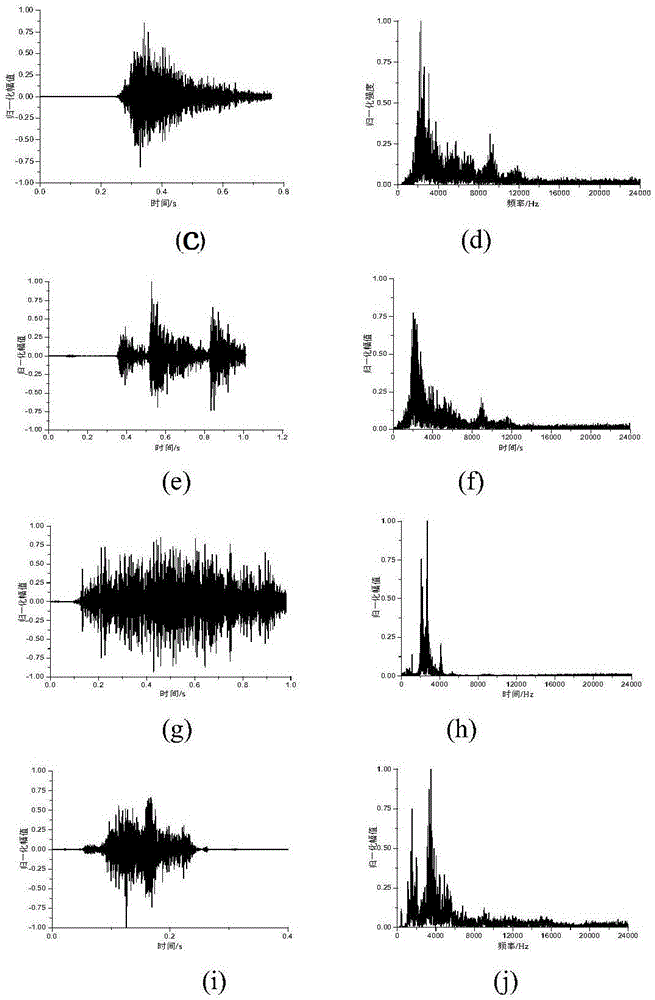
图4猪声音样本时域、频域图:(a)猪吃食声波形图、(b)猪吃食声频谱图、(c)猪打喷嚏声波形图(d)猪打喷嚏声频谱图、(e)猪甩耳朵声波形图、(f)猪甩耳朵声频谱图、(g)猪哼哼声波形图、(h)猪哼哼声频谱图、(i)猪尖叫声波形图(j)猪尖叫声频谱图;
图5六层小波包分解结构图;
图6梅山猪发情声子带频段能量比分布;
图7mel频率倒谱特征参数提取流程图;
图8梅山猪发情声的mfcc:(a)时间规整前的mfcc、(b)时间规整后的mfcc、
图9受限玻尔兹曼机网络结构
图10深度信念网络梅山猪发情声识别模型
具体实施方式
实施例1
一种基于声学信息的梅山猪发情监测方法,所述方法包括以下步骤:
步骤1:通过放置在猪栏处的录音设备,采集梅山猪发情时产生的声音信号,同时采集猪场环境中梅山猪和长白猪的打喷嚏、吃食、尖叫、哼哼、甩耳朵声音信号;
步骤2:基于小波阈值多窗谱的维纳语音增强算法对步骤1采集的猪声音信号进行预处理,实现猪声音信号的去噪,得到去噪后的猪声信号;
步骤3:利用基于短时能量的双门限端点检测方法对步骤2去噪后的猪声信号进行有效信号的提取,得到有效的猪声信号;
步骤4:对步骤3的有效的猪声信号进行时频特征分析,确定声音信号的持续时长、能量分布和频率分布;
步骤5:在步骤4的时频特征分析基础上,对有效猪声信号进行声音特征提取,声音特征指标包括短时能量、短时过零率、基于6层小波包分解的子带频段能量比、梅尔频率倒谱系数;
步骤6:对所述步骤5中提取的声音特征参数,采用深度信念网络建立梅山猪发情声识别模型;
步骤7:按训练集和测试集4:1的比例,利用步骤6中建立的梅山猪发情声识别模型进行识别验证,并进行5折交叉验证,确定识别效果;
完成梅山猪发情声的识别。
优选地,所述步骤4梅山猪发情时的嚎叫声单次时间持续1.8-2.2s,打喷嚏和甩耳朵声时间持续0.38-0.42s,尖叫、哼哼时间持续0.6~1.4s,单脉冲吃食声时间持续0.09-0.11s;
所述梅山猪发情声在时域和频域上呈现两段分布,能量集中分布于500~1500hz和2500~5500hz这两个频段,且两个频段之间能量有一个较大的回落;单脉冲吃食声时间较短,频谱分布于1000~10000hz的较宽频段;打喷嚏、尖叫声、甩耳朵和哼哼声频率主峰均位于3000~4000hz频段,其中哼哼声频率分布于2000~3500hz的较窄频带。
优选地,所述步骤5声音特征提取前采用时间规整算法将声音信号规整为相同维数的特征向量后再进行特征提取。
优选地,所述步骤5中,短时能量和短时过零率均为300维,梅尔倒谱系数为720维,基于6层小波包分解的子带频段能量比提取时,选取32维子带频段能量比。
优选地,所述步骤6深度信念网络建立了一个5层的深度信念网络梅山猪发情声识别模型,采用非监督贪婪算法逐层预训练多层受限玻尔兹曼机(rbm)的网络结构并采用误差反向传播算法(bp)进行整体微调的方式调整权值;设定了50个样本的小批量数据包的训练模式,学习率为0.1,权损失系数为0.0002,能够获取收敛较优的梅山猪发情声识别模型。
优选地,所述步骤7中,采用5折交叉验证法来对识别效果进行验证,即将梅山猪发情声与非发情声样本平均分成5等份,然后按照训练集与测试集4:1的比例分成5组,轮流去做训练和测试,循环5次。
优选地,所述步骤7,单个参数识别效果由高到低依次为由高到低依次为梅尔倒谱系数、子带频段能量比、短时能量、短时过零率;组合参数识别效果最优为梅尔倒谱系数和子带频段能量比的特征组合。
实施例2
1猪声音采集与预处理
1.1猪声音采集
猪声音采集在华中农业大学校属精品种猪场完成。采集设备为美博-m66录音笔,采样频率为48khz,采样精度为16位,双声道连续采集,最大工作时长24h。猪分布于相邻三栏,中间一栏为5头梅山猪,另两栏为5头长白猪。经猪场有经验的管理员确认发情梅山猪只为3头。猪场环境内声音信号复杂多样,夹杂着多种噪声和多种多头猪只的声音。对采集的猪声音进行分类标记和筛选,选取500个梅山猪发情声样本和500个非发情声样本,其中非发情声样本包括打喷嚏样本100个,吃食样本110个,尖叫样本105个,哼哼样本85个,甩耳朵样本100个。采集的信号以wav格式保存。
1.2猪声音预处理
猪场环境下采集的声音数据样本包含很多噪音和无效信号,为提高猪发情声与非发情声的识别率,在特征提取之前需要进行去噪和端点检测,以提高声音信号样本的信噪比。预处理后的猪声音信号噪声干扰较小,信号较纯净,特征参数较稳定,利于后续的识别模型的建立。
1.2.1基于小波阈值多窗谱的维纳语音增强
采集到的声音信号为非纯净信号,信噪比较低,分析信号的噪声成分对有效提取猪只声音信号特征至关重要。如图1a、1b所示分别表示猪场环境噪声波形图和频谱图,图1c、1d分别为猪发情叫声波形图和频谱图。从图1b和1d可以看出猪场环境噪声频段主要集中在12000hz以下,猪发情叫声频段主要集中在6000hz以下,两者重叠部分较大,传统数字信号滤波器难以对猪声音样本有效去噪。
为了极大的减少预处理中有效信息的损失,采用基于小波阈值多窗谱的维纳语音增强算法对猪声音样本进行去噪处理。小波变换通过伸缩平移运算对信号进行多尺度细分,聚焦到信号的任意细节,根据语音与噪声本身的差异性得到抑制噪声水平的阈值。多窗谱即对待估计猪声音样本序列加多个相互正交的窗分别计算频谱然后平均的非参数谱估计方法。
基于小波阈值多窗谱的维纳算法计算步骤为:(1)利用多窗谱法计算带噪语音的多窗功率谱;(2)利用小波阈值平滑带噪语音的多窗功率谱;(3)基于无语音帧的带噪语音功率谱计算出噪声的功率谱;(4)计算带噪语音功率谱与噪声功率谱之比得到先验信噪比;(5)借助先验信噪比得到维纳滤波器传递函数,计算得到滤波后的猪声音信号。
图2所示为基于小波阈值多窗谱的维纳语音增强算法处理后猪发情声音样本波形图,对比图1c语音增强前波形图可知,语音增强后猪声音样本噪声明显减少,声音信号波形几乎没有发生失真。
1.2.2基于短时能量的双门限端点检测
语音信号端点检测是指从包含语音的一段信号中找出语音的起止点,把起止点之间的信号定义为有效信号。有效的端点检测不仅可以清除无声段的噪声干扰,而且可以缩短猪声音信号的处理时间减少识别过程中对声学模型训练时的计算量,还对猪发情声识别正确率有着积极的影响。在经过语音增强后,信噪比极大提高,选用基于短时能量的方法进行猪声音样本端点检测。对猪声音样本x(n),分帧后第v帧表示为xv(n),此帧猪声音信号的短时能量ev计算公式为
式中n——帧长,根据声音信号的短时平稳特性取为200个采样点
n——猪声音样本第n个采样点序号
为了避免语音端点检测过程中受到绝对能量带来的影响,把短时能量的幅值进行归一化处理。幅值归一化后的短时能量eev的计算公式如下
式中v——猪声音样本总帧数
根据如下阈值计算公式设定2个阈值t1和t2
式中fins——猪声音样本前导无话段帧长
由式(3)和式(4)计算得到t1、t2为0.035、0.002。当高于t1时判定为语音帧低于或高于t2时确定为猪声音样本起止点。图3所示为单参数双门限端点检测对应的猪发情声样本检测效果,由图可知基于短时能量的端点检测可以较好地检测并保留有效信号。
1.2.3时间规整算法
语音信号具有很强的随机性,同一个发声单元提取到的特征参数的帧数也不一定相同,不同类型的猪声音信号持续时间长短不一,但一个确定结构的神经网络具有固定的输入神经元。因此需要运用时间规整算法将猪声音样本规整为同一长度再进行特征参数提取。
具体的规整算法描述如下:设
i=0,1,…,n-n;k=1,2,…,n-i。特别地,当i=0时有
a)计算
b)计算
c)计算
对于一个有v帧的猪声音样本,通过时间规整算法对距离最近的2个特征矢量进行加权合并,经过v-n步合并,最终网络输出层具有n个特征矢量。通过规整网络,可以将任意帧的特征矢量规整到指定的帧数。
2特征分析与提取
2.1时频分析
不同类型的猪声音信号具有不同的时长特性和频谱分布,同种母猪声音持续时间也不完全相等。猪声音样本时域波形和频谱图如图4所示。
由图2知,梅山猪发情声在时间和频率上都呈现两段分布,单次发情嚎叫声单次持续2s左右,响度由低升高再缓慢降低然后升高后急速回落,后半程较前半程响度更大更刺耳,频率范围为300~7000hz,后者幅值较前者大,且频带较宽,能量集中分布于500~1500hz和2500~5500hz这两个频段,且两个频段之间能量有一个较大的回落;由图4可知,打喷嚏和甩耳朵声一般在0.4s左右,尖叫、哼哼持续时间在0.6~1.4s不等,打喷嚏、尖叫声、甩耳朵和哼哼声频率主峰均位于3000~4000hz频段,其中哼哼声频率分布于2000~3500hz,而单脉冲吃食声时间为0.1s左右,频谱范围较宽,即分布于1000~10000hz。
2.2特征提取
2.2.1短时能量
短时能量是一种反应信号幅度变化的有效描述方法,其在端点检测中可用于判定有声段和无声段,也作为表示语音信号能量大小的特征参数。短时能量ee由公式(1)计算可得。由图4可以看出,不同声音信号在时间维度上波形差异显著,信号在对应时间的能量也具有显著差异。
2.2.2短时过零率
在时域上,一般利用过零率(zero-crossingrate,zcr)描述动物声音波动的激烈程度。短时过零率是指声音振动方向持续变化的信号在一个短时帧长内通过横坐标轴的次数。由过零率的定义可知,信号高频率段具有高过零率,低频率段具有低过零率,因此,过零率可以在一定程度上反映信号的频率特性。
短时过零率计算公式为
zn为该帧的短时过零率,sgn[*]是符号函数,即:
式中x(n)——离散采样后的猪声音信号
对短时过零率的幅值进行归一化处理。幅值归一化后的短时过零率zcrv的计算公式如下
式中v——猪声音样本总帧数
2.2.3基于小波包分解的子带频段能量比
猪声音是一种持续时间较短的、突变的、非平稳随机信号。传统的信号分析和处理方法一般都是采用傅立叶分析,它是一个窗口函数固定不变的分析方法,无法反映信号的非平稳、持时短、时域和频域局部化等特性。而小波包分解能获取信号时频局部特征的分析,能根据信号特性和分析要求自适应地选择相应频带与信号频谱相匹配,是一种比小波分解更为精细的分解方法。小波包分解是将信号整个频带进行多层次的划分,同时对低频和高频成分进行分解。
本发明采用6层小波包对梅山猪声音信号进行分解,选取db1小波作为小波包基函数。其小波包分解树如图5所示。图中,每个节点都代表了一定的特征,节点(0,0)代表原始猪声音信号p,节点(a,b)代表第a层小波包分解第b个节点的系数,其中a=1,2,3,…,6;b=0,1,2,3…63。利用分解的节点系数对分解尺度上的信号进行单尺度重构,得到各频段内的小波包重构信号pab,pab表示节点(a,b)的小波包重构信号。
最后,频段内重构信号的能量e6b的计算公式为:
式中m——重构信号p6b的离散采样点数
p6b(i)——重构信号p6b的第i个采样值
基于小波包分解提取多尺度空间能量特征的原理是把不同分解尺度上的信号能量求解出来,将这些能量值按尺度顺序排列成特征向量供识别使用。子带频段能量比(se)定义为各子带能量与频域总能量的比值,不同类型的语音信号,其能量在各个子带区间的分布有所不同。根据各子带能量e6b系数可以构建一特征向量sen=[λ1,λ2…,λ64],其中:
λb代表了各子带频段能量在总能量中所占的比例。
本发明采集声音信号样本的采样频率为48000hz,则奈奎斯特频率为24000hz,而梅山猪的各类生理声音信号的主要频率成分为12000以下的频率部分。由小波包分解树节点与信号子空间频段的对应关系知,0~12000hz对应频段1~32。由图6可以看出,梅山猪发情声音信号能量主要集中在低频段,计算选取的32个频段能量占总能量的95.15%。舍弃高频部分的频段使特征维数由64降为32,减少了运算量,同时也起到了一定的低通滤波效果。
2.2.4梅尔频率倒谱系数
梅尔频率倒谱系数(melfrequencycepstralcoefficients,mfcc)的分析是基于人耳听觉原理,依据人的听觉实验结果来分析声音的频谱特性。
在1khz以下时,人耳对声音的感知能力与频率成线性关系,大于1khz时,感知能力与频率成对数关系,且频率越高感知能力越差,而在mel频域内,人对声音的感知能力与mel频率呈线性关系。基于人对声音的感知规律,先将线性频谱映射到基于听觉感知的mel非线性频谱中,然后转换到倒谱上,最终得到的mfcc为原始声音信号对应的mel频率上的倒谱系数。其中mel频率与赫兹频率的对应关系为:
mel(f)=2595lg(1+f/700)(10)
式中f——为实际语音频率。
本发明选择24个梅尔频率滤波器组,mfcc特征参数提取流程如图7所示。
图8a所示为猪发情样本mfcc三维图,对于一个300帧的猪发情声样本,24维的mfcc数据量是比较大的,因此采用时间规整算法将300帧的mfcc参数规整到30帧组成720维的mfcc特征向量。图8b为猪发情声mfcc经时间规整后的三维图。由猪发情声样本mfcc时间规整前后三维图可知,图8b相对图8a帧数从300帧减少到30帧,数据量大大减少,同时,图8b也保留了图8a在时序上的动态变化特性。
3梅山猪发情声识别
3.1深度信念网络梅山猪发情声识别模型建立
深度信念网络是由多层受限玻尔兹曼机(restrictedboltzmannmachine,rbm)堆叠而成的网络模型。rbm是一类由两层神经元组成的层间全连接、层内无连接,对称且无自反馈的随机神经网络模型。显层为输入层,表示观测数据,隐层可视为特征提取器,其结构如图9所示。rbm中的神经元只有激活、未激活两种输出状态,用0、1表示,即对任意i,j,vi∈{0,1},hj∈{0,1}。
假设一个rbm由n个显层神经元和m个隐层神经元,向量v和h分别表示显层和隐层的状态,vi表示第i个显层神经元的状态,hj表示第j个隐层神经元的状态。给定一组{v,h},rbm能量计算公式为
式中θ={wij,ai,bj}是rbm的参数,均为实数。
wij表示显层神经元i与隐层神经元j之间的连接权重,ai表示显层神经元i的偏置,bj表示隐层神经元j的偏置。当参数确定时,基于该能量函数,我们可得(v,h)的联合概率分布计算公式为
采用3层rbm堆叠形成的dbn作为梅山猪发情声识别模型,网络结构如图10所示。将经过时间规整算法提取的l0维特征参数(由于不同的特征及组合维度不一样,故设为未知)作为dbn的输入。根据识别对象为猪发情声与非发情声,顶层输出层神经元个数选为2个。隐层神经元个数选择不合理会导致dbn识别能力和网络容错性降低,设隐层神经元个数分别为l1、l2、l3,则dbn模型可表示为l0-l1-l2-l3-2。隐层神经元个数经验公式为
式中lh——隐层神经元个数
lh-——前一层神经元个数
lh+——后一层神经元个数
δ——平衡参数,取0~10之间的常数
选取合适的δ值,根据经验公式(13)先设置一个隐层神经元个数初始值,然后采用逐步试验法,比较每次网络的识别性能,选择识别性能最好时所对应的隐层神经元个数作为模型参数。
3.2深度信念网络梅山猪发情声识别模型训练
本发明采用非监督贪婪算法逐层预训练rbm和bp算法进行整体微调的方式来训练dbn模型。预训练的过程即逐层训练rbm的过程。将每一个猪声音样本特征参数作为一个状态向量r,rbm训练的目的是通过式(11)最小化玻尔兹曼机的能量,同时通过式(12)最大化状态向量r出现的概率,进而得到对应的rbm权值wij、显层神经元的偏置ai和隐层神经元的偏置bj。此过程用对比散度(contrastivedivergence,cd)算法来实现。
由rbm的网络结构可得由隐层计算显层和显层计算隐层的条件概率分别为
由cd算法原理,对于每一个猪声音样本v,首先根据式(15)计算出隐层神经元的状态分布,然后由此概率分布通过吉布斯采样得到h;接着根据式(14)从h产生v',最后根据式(15)产生h';于是得到rbm权值更新公式为
wt+1=wt+η(vht-v'h')(16)
式中η——学习率,本文设置为0.1
v'——v经过吉布斯采样结果
h'——h经过吉布斯采样结果
wt——第t次训练得到的权值
wt+1——第t+1次训练得到的权值
为了提高dbn训练效率,本文采用小批量数据(每批量20个样本)的方式进行数据训练。为防止dbn训练时陷入过拟合,在权值更新过程中引入权衰减(weightdecay)进行修正,其中权损失(weightcost)系数λ取值范围为0.0001~0.01。将式(16)修改为(17),表示为
wt+1=wt+η(vht-v'h'+λwt)(17)
式中λ——权损失系数,设置为0.0002。
3.3梅山猪发情声识别结果分析
本发明采用短时分析技术,对声音信号的时域和频域进行特征分析,选取能够表征信号的特征作为识别的参数,提取了经时间规整算法规整后的300维短时能量、300维短时过零率、32维基于6层小波包分解的子带频段能量比和720维梅尔倒谱系数共1352维梅山猪声音特征。
采用5折交叉验证法对识别效果进行验证,即将梅山猪发情声与非发情声样本平均分成5等份,然后按照训练集与测试集4:1的比例分成5组。采用5个指标来衡量试验结果:梅山猪发情声识别率(正确识别的梅山猪发情声样本占测试集梅山猪发情样本总数百分比)、梅山猪发情声误识别率(被误识别为梅山猪发情声的非发情声样本占测试集梅山猪非发情样本总数百分比)、总识别率(正确识别出的梅山猪发情声和非发情声占测试样本总数的百分比)、发情声识别率标准差(5折交叉验证发情声识别率的标准偏差,反应5次识别率的离散程度)和发情声误识别率标准差(5折交叉验证发情声误识别率的标准偏差)。
对4类特征进行5折交叉验证,得到识别率的平均值,其特征参数组合的发情声和非发情声识别效果如表1所示。
表1基于单参数的梅山猪发情声识别5折交叉验证结果
注:梅尔频率倒谱系数mfcc,子带频段能量比se,短时能量ee,短时过零率zcr。
通过表1的交叉验证实验识别结果可知:识别效果由高到低依次为梅尔倒谱系数、子带频段能量比、短时能量、短时过零率;基于短时能量和短时过零率特征的识别率高于80%但低于90%,且误识别率高于10%;子带频段能量比参数识别效果较好,其发情声识别率为95.60%,但误识别率达到了9.40%;梅尔倒谱系数为最优参数,其基于dbn模型的梅山猪发情声识别率、误识别率和总识别率分别为99.00%、5.00%和97.00%,且其识别率和误识别率标准差最小,具有很好的稳定性。
本发明将不同的特征参数进行组合,进一步探讨不同的特征组合对识别效果的影响。
对4类特征的11种不同的特征组合分别进行5折交叉验证,其不同特征组合的发情声和非发情声识别效果如表2所示。
表2梅山猪发情声特征组合的dbn模型识别效果
通过对4类特征的11种特征组合进行识别验证综合分析可得:短时能量和短时过零率特征组合的识别效果相对单参数有所提高,发情声识别率分别提高了2.2%和6.6%,总识别率分别提高了1.2%和6%;与短时能量、短时过零率组合的子带频段能量比特征的识别率反而降低;含有梅尔倒谱系数的特征组合具有稳定且较好的识别效果;最优组合为梅尔倒谱系数和子带频段能量比的特征组合,识别效果及识别稳定性均为最佳,其中梅山猪发情声识别率、误识别率和总识别率分别为99.00%、4.00%和97.50%,与单参数相比,识别率和总识别率均显著提高、误识别率显著降低、识别率标准差减小。
通过本实施例可知:
(1)通过对猪声音信号进行时域分析,可知:梅山猪单次发情叫声持续1.8-2.2s,打喷嚏和甩耳朵声时间持续0.38-0.42s,尖叫、哼哼时间持续0.6~1.4s,单脉冲吃食声时间持续0.09-0.11s,不同类型声音具有不同的波形变现,信号能量在时域上分布不同。
(2)通过观察猪声音信号的频谱,可知:梅山猪发情声频谱的频率范围为300~7000hz,能量集中分布于500~1500hz和2500~5500hz这两个频段,后者频带较宽,且两个频段之间能量有一个较大的回落;单脉冲吃食声时间较短,频谱范围较大,打喷嚏、尖叫声、甩耳朵和哼哼声频率主峰均位于3000~4000hz频段,其中哼哼声频率分布频带较窄。
(3)将深度信念网络引入梅山猪发情声识别领域,构建了一个5层的深度信念网络梅山猪发情声识别模型,采用非监督贪婪算法逐层预训练rbm和bp算法整体微调的方式进行训练。设定了50个样本的小批量数据包的训练模式,学习率为0.1,权损失系数为0.0002,能够获取收敛较优的梅山猪发情声识别模型。
(4)通过5折交叉验证对4类单参数特征进行识别效果验证,可得识别效果由高到低依次为梅尔倒谱系数、子带频段能量比、短时能量、短时过零率;梅尔倒谱系数为最优单参数,其基于dbn模型的梅山猪发情声识别率、误识别率和总识别率分别为99.00%、5.00%和97.00%,且其识别率和误识别率标准差最小,具有很好的稳定性;进一步研究了4类特征的11种特征组合的识别效果,最优组合为梅尔倒谱系数和子带频段能量比的特征组合,识别效果及识别稳定性均为最佳,其中梅山猪发情声识别率、误识别率和总识别率分别为99.00%、4.00%和97.50%,与单参数相比,识别率和总识别率均显著提高、误识别率显著降低、识别率标准差减小。
上述的实施例仅为本发明的优选技术方案,而不应视为对于本发明的限制,本申请中的实施例及实施例中的特征在不冲突的情况下,可以相互任意组合。本发明的保护范围应以权利要求记载的技术方案,包括权利要求记载的技术方案中技术特征的等同替换方案为保护范围。即在此范围内的等同替换改进,也在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!