基于非线性动力学的睡眠阶段分期方法与流程
本发明属于音频领域,特别是一种基于非线性动力学的睡眠阶段分期方法。
背景技术:
睡眠是人体恢复精力的最好休息方式,良好的睡眠有利于提高人的生活质量、工作效率和生活幸福感。目前国际上采用的睡眠监测多为多导睡眠图监测(psg),它记录并分析多种睡眠呼吸参数,能够准确地判断睡眠结构和睡眠分期。但是psg也有很多不足之处,其中它操作复杂,需要专业人员进行电极粘贴,只能在实验室或者医院使用。而且所接电极繁多,粘贴在身体各个部位,并不适用于皮肤敏感者,这也影响了被监测者的自然睡眠,对测试实验产生干扰。此外,psg检测费用高,不能作为日常监护。
现有的临床睡眠分析方法主要是穿戴式的,北京怡和嘉业医疗科技有限公司的专利《电磁式胸腹带及多导睡眠监测仪》中,提供了一种电磁式胸腹带,包括胸带和腹带,其中胸带和腹带上均固定有磁性件和感应设备,通过监测胸呼吸和腹呼吸的参数来实现睡眠监测。中国人民解放军第二军医大学的专利《一种睡眠监测系统》中,提出了一种包含了脑电波收集帽及手套的睡眠监测系统,它通过监测睡眠脑电波、指氧饱和度、肌电及体动这四项指标来对睡眠进行检测。这两篇专利中的电磁式胸腹带或脑电波收集帽及手套都需固定在被监测者的身体上,增加了被监测者在睡眠监测时的异物感,产生了心理和生理负荷,从而影响了测试结果。
技术实现要素:
本发明的目的在于提供一种基于非线性动力学的睡眠阶段分期方法。
实现该目的的技术解决方案为:一种基于非线性动力学的睡眠阶段分期方法,包括以下步骤:
步骤1:用音频设备采集监护者整夜的睡眠音频信号,同时用标准psg仪对实验者进行睡眠监测,得到睡眠阶段标签;
步骤2:将步骤1采集到的音频信号与标准psg仪采集到的睡眠阶段标签按照对应法则一一对应;
步骤3:对步骤1采集到的音频信号进行预处理,具体为:对录取的音频信号进行降噪处理,得到降噪处理后的睡眠音频,对降噪后的睡眠音频信号进行声音事件检测,得到声音事件,其中所述声音事件具体为人体一呼一吸产生的音频;
步骤4:采用非线性动力学分析方法对检测到的声音事件进行特征提取,所述特征具体为:时间延迟
步骤5:将提取得到的特征参数与对应的标签输入到机器学习中,通过机器学习方法来确定睡眠阶段与特征参数之间的映射模型;
步骤6:根据步骤5得到的映射模型,对音频设备录取的音频信号进行睡眠阶段分期。
本发明与现有技术相比,其显著优点在于:1)本发明利用音频设备实现睡眠的非接触式监测,与传统的接触式监测相比,设备简单易操作,能减少人体的不适感,并且可以克服很多的局限性。2)本发明选择了合适的特征参数来表征多种睡眠阶段,通过机器学习方法训练出可以区分不同睡眠阶段的模型。因此,能够通过睡眠音频的特征参数判决它的睡眠阶段。3)本发明的方法简单有效,设备简单易实现,低成本,易操作,性能可靠。
下面结合说明书附图对本发明做进一步描述。
附图说明
图1为本发明实现睡眠阶段判决的步骤框图。
图2为本发明机器学习结构图。
图3为原始睡眠音频波形图。
图4为降噪后的睡眠音频波形图。
图5为声音事件检测后的睡眠音频波形图。
图6为机器学习分类的混淆矩阵图。
具体实施方式
结合附图,本发明的一种基于非线性动力学的睡眠阶段分期方法,包括以下步骤:
步骤1:用音频设备采集监护者整夜的睡眠音频信号,同时用标准psg仪对实验者进行睡眠监测,得到睡眠阶段标签;
步骤2:将步骤1采集到的音频信号与标准psg仪采集到的睡眠阶段标签按照对应法则一一对应;
所述对应法则为:音频标签a为清醒期即入睡前的准备阶段,对应psg结果的入睡期n1,音频标签b为nrem期即包括轻度睡眠、中度睡眠、深度睡眠的阶段,对应psg结果的浅睡期n2和深睡期n3,标签c为rem期即快速眼球运动阶段,对应psg结果的快速眼球运动rem。
步骤3:对步骤1采集到的音频信号进行预处理,具体为:对录取的音频信号进行降噪处理,得到降噪处理后的睡眠音频,对降噪后的睡眠音频信号进行声音事件检测,得到声音事件,其中所述声音事件具体为人体一呼一吸产生的音频;其步骤为:
步骤3-1:对音频信号se(n)进行加窗分帧处理,计算每帧音频信号sei(m)的能量ampi和短时谱熵h(i),能熵比eefi表示为
其中sei(m)的下标i表示为第i帧;
步骤3-2:根据能熵比使用双门限检测法进行语音端点检测,检测出有效的声音事件;其中双门限检测法中的阈值t2=a1×det+eth,t1=a2×det+eth,det为能熵比eefi的最大值,eth为睡眠音频信号前置无话段的能熵比均值,a1、a2为det的权重。
步骤4:采用非线性动力学分析方法对检测到的声音事件进行特征提取,所述特征具体为:时间延迟
步骤4-1:求取时间延迟
步骤4-2:求取嵌入维数
步骤4-2-1:由相空间重构理论,根据步骤4-1得到的时间延迟τ,将一维声音事件时间序列x(n)嵌入到m维空间y中;
步骤4-2-2:改变维数m=m+1,计算虚假邻近点的个数;
步骤4-2-3:当虚假近邻点个数占全部m维空间中相矢量的比例小于自定义阈值b时,此时的维数m为声音事件时间序列x(n)的最佳嵌入维数;否则返回步骤4-2-2。
步骤4-2-4:将每个声音事件时间序列x(n)的最佳嵌入维数m取平均,得到每帧内所有声音事件的平均嵌入维数
步骤4-3:求取近似熵
步骤4-3-1:将声音事件的一维时间序列x(n)=(x1,x2,x3,…,xi,…,xk)按顺序组成v维矢量vi=[x(i),x(i+1),...,x(i+v-1)],i=1,2,...,k,
其中k为声音事件时间序列x(n)的长度;
步骤4-3-2:对每一个i值计算相矢量vi和其余矢量vj的距离
dij=max|x(i+l)-x(j+l)|,l=0,1,...,v-1;
步骤4-3-3:给定阈值r=a3×sd,其中a3的取值范围为0.1~0.25,sd为声音事件时间序列x(n)的标准差;记录每个dij小于阈值r对应的i的个数,并求出与总的v维相矢量个数(k-v+1)的比值,记为
步骤4-3-4:确定声音事件时间序列x(n)的近似熵为apen=φv(r)-φv+1(r);
步骤4-3-5:将每个声音事件时间序列x(n)的近似熵apen取平均,得到每帧内所有声音事件的平均近似熵
步骤4-4:求取高维个数n,具体为:记录步骤4-2中每帧内嵌入维数m≥4的声音事件时间序列x(n)的个数;
步骤4-5:求取最大李雅普诺夫指数
步骤4-5-1:根据步骤4-1求得的时间延迟τ和步骤4-2求得的嵌入维数m重构相空间w,对每个点wj寻找其最近邻点w′j,计算wj到w′j的距离dj(0)=|wj-w′j|;
步骤4-5-2:对每个点wj,计算其与最近邻点w′j在第i步前向演化后的距离dj(i)=|wj+i-w′j+i|=dj(0)×eλ×i;
步骤4-5-3:由下式算得最大李雅普诺夫指数,
其中p为非零的dj(i)的个数;
步骤4-5-4:将每个声音事件时间序列x(n)的最大李雅普诺夫指数λ取平均,得到每帧内所有声音事件的平均最大李雅普诺夫指数
步骤5:将提取得到的特征参数与对应的标签输入到机器学习中,通过机器学习方法来确定睡眠阶段与特征参数之间的映射模型;具体为:
步骤5-1:将睡眠音频信号的非线性特征数据随机分成两个互斥集,其中一个为训练集s,另一个为交叉检验集cv,并将这些数据的睡眠阶段进行标记,即标记为a、b或c,a为清醒期,b为nrem期,c为rem期;
步骤5-2:将训练集s={(f1,l1),(f2,l2),...(fi,li),...,(fw,lw)}的特征矩阵输入机器学习方法中,其中fi=(fi1,fi2,fi3,fi4,fi5)分别为步骤4中提取的5个非线性动力学特征
步骤5-3:随机从训练集取一个样本放入采样集中,再把该样本放回初始训练集中,使得下次采样时该样本仍有可能被选中,经过w次随机采样操作后得到w个样本的采样集,重复t次,得到t组含w个训练样本的采样集;
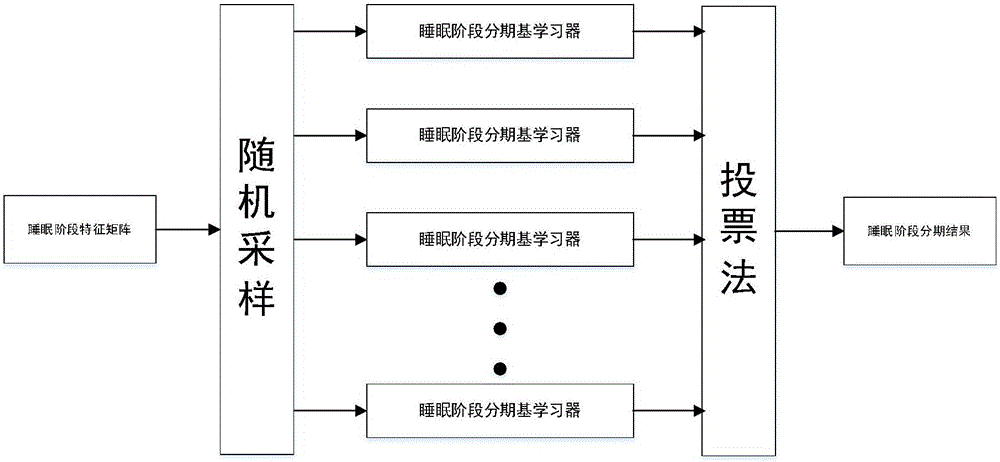
步骤5-4:基于每个采样集的特征矩阵去训练出一个睡眠阶段分期基学习器,得到t个睡眠阶段分期基学习器,映射模型m1由这t个睡眠阶段分期基学习器组成,具体采用投票法进行输出;
所训练的睡眠阶段分期基学习器为决策树,具体为:
步骤5-4-1:遍历各个特征,计算其的基尼值,其公式为:
δgini(ac)=gini(a)-giniac(a)
第一个公式中,数据集a为步骤5-3中w个训练样本的采样集,gini(a)表示的是数据集a的基尼指数,ri表示第i类样本在数据集a中的比例,pc为睡眠阶段的标签数;第二个公式中,ac为步骤4中得到的特征
步骤5-4-2:以步骤5-4-1生成的节点作为根节点,重复5-4-1的过程,选取新的材料特征作为分裂条件,数据a全部被划分完。
或者,所训练的睡眠阶段分期基学习器为多类别分类的svm,具体为:
步骤5-4-a:若含w个样本的采样集中都包含了3个睡眠阶段类别的数据,对3个睡眠阶段类别,做q次划分,这里q的取值必须大于3,每次随机划分将一部分类别划分成正类,记为(+1),另一部分类别划分为反类,记为(-1),这里每一组对应的正类和负类即为一个训练集;共产生q个训练集;
步骤5-4-b:将5-4-a生成的q个训练集分别训练svm,得到q个svm学习器,这样每一类的数据输入这q个svm学习器中得到相应的编码,组成3*q的编码矩阵;
步骤5-4-c:利用q个分类器分别对测试样本进行预测,预测标记组成一个编码,将这个编码与每个类别各自的编码进行比较,返回其中距离最小的类别作为最终预测的结果,这q个svm分类器组成了多类别分类的svm学习器。
步骤5-5:使用交叉检验集cv对睡眠阶段与特征参数之间的映射模型m1进行进一步调参优化,得到映射模型m。具体为:
步骤5-5-1、确定睡眠阶段分期基学习器的参数,当睡眠阶段分期基学习器为决策树时,参数包括决策数的分裂时参与判断的最大特征数max_feature、最大深度max_depth、分裂所需的最小样本数min_samples_split;当睡眠阶段分期基学习器为多类别分类的svm时,参数为svm的惩罚参数c、核函数参数gamma;
步骤5-5-2、对每个参数进行一次直线搜索,具体为,利用cv集对基学习器进行训练,计算模型性能与参数之间的梯度;
步骤5-5-3、根据模型性能与各个参数之间的梯度,选取梯度值最大的参数作为当前调优参数,利用梯度下降法对当前调优参数进行调优;
步骤5-5-4、重复步骤5-5-2,5-5-3,直到所有参数的梯度小于阈值threshold,这里的threshold为一个接近0的正数;
步骤5-5-5、调整睡眠阶段分期基学习器个数t,具体为:计算模型性能与t之间的梯度,利用梯度下降法对基学习器个数t进行调优,得到最终的睡眠阶段分期基学习器个数。
步骤6:根据步骤5得到的映射模型,对音频设备录取的音频信号进行睡眠阶段分期。
本发明的方法简单有效,设备简单易实现,低成本,易操作,性能可靠。
下面结合实施例,进一步阐述本发明。
实施例1
一种基于非线性动力学的睡眠阶段分期方法,包括以下步骤:
步骤1:用音频设备采集监护者整夜的睡眠音频信号,同时用标准psg仪对实验者进行睡眠监测,得到睡眠阶段标签;
步骤2:将步骤1采集到的音频信号与标准psg仪的睡眠阶段标签按照对应法则一一对应;
步骤3:对步骤1采集到的音频信号进行预处理,具体为:对录取的音频信号进行降噪处理,得到降噪处理后的睡眠音频,截取监护者从清醒到深度睡眠的一个周期的降噪后的音频信号,通过能熵比法对语音端点进行检测,从睡眠音频信号中检测出有效的声音事件,其步骤为:
步骤3-1:对睡眠音频信号x(n)进行加窗分帧处理,计算每帧音频信号xi(m)的能量ampi和短时谱熵h(i),能熵比eefi表示为
其中xi(m)的下标i表示为第i帧;
步骤3-2:根据能熵比使用双门限检测法进行语音端点检测,检测出有效的声音事件;其中双门限检测法中的阈值t2=a1×det+eth,t1=a2×det+eth,det为能熵比eefi的最大值,eth为睡眠音频信号前置无话段的能熵比均值,根据实际情况,将a1取值为0.04,a2取值为0.015。
步骤4:检测到声音事件后,对音频进行分帧,帧长为30s;
步骤5:采用非线性动力学分析方法对检测到的声音事件进行特征提取,提取的特征为:时间延迟
步骤5-1:求取时间延迟
步骤5-2:求取嵌入维数
步骤5-2-1:由相空间重构理论,根据步骤5-1得到的时间延迟τ,将一维音频时间序列x(n)嵌入到m维空间y中;
步骤5-2-2:改变维数m=m+1,计算虚假邻近点的个数;
步骤5-2-3:当虚假近邻点个数占全部m维空间中相矢量的比例小于自定义阈值b时,此时的维数m为声音事件的一维时间序列x的最佳嵌入维数;否则返回步骤5-2-2;
步骤5-2-4:将每个声音事件x(n)的最佳嵌入维数m取平均,得到每帧内所有声音事件的平均嵌入维数
步骤5-3:求取近似熵
步骤5-3-1:将声音事件的一维时间序列x(n)=(x1,x2,x3,...,xi,...,xk)按顺序组成v维矢量vi=[x(i),x(i+1),...,x(i+v-1)],i=1,2,...,k,
其中k为音频时间序列x(n)的长度,v=2;
步骤5-3-2:对每一个i值计算相矢量vi和其余矢量vj的距离dij=max|x(i+l)-x(j+l)|,l=0,1,...,v-1;
步骤5-3-3:给定阈值r=a3×sd,其中a3=0.25,sd为音频序列x的标准差。记录每个dij小于阈值r对应的i的个数,并求出与总的v维相矢量个数(k-v+1)的比值,记为
步骤5-3-4:确定声音事件x(n)的近似熵为apen=φv(r)-φv+1(r);
步骤5-3-5:将每个声音事件x(n)的近似熵apen取平均,得到每帧内所有声音事件的平均近似熵
步骤5-4:求取高维个数n,具体为:记录步骤5-2中每帧内嵌入维数m≥4的声音事件个数;
步骤5-5:求取最大李雅普诺夫指数
步骤5-5-1:根据步骤5-1求得的时间延迟τ和步骤5-2求得的嵌入维数m重构相空间w,对每个点wj寻找其最近邻点w′j,计算wj到w′j的距离dj(0)=|wj-w′j|;
步骤5-5-2:对每个点wj,计算其与最近邻点w′j在第i步前向演化后的距离dj(i)=|wj+i-w′j+i|=dj(0)×eλ×i;
步骤5-5-3:由下式算得最大李雅普诺夫指数,
其中p为非零的dj(i)的个数。
步骤5-5-4:将每个声音事件x(n)的最大李雅普诺夫指数λ取平均,得到每帧内所有声音事件的平均最大李雅普诺夫指数
步骤6:将提取得到的特征参数与对应的标签输入到机器学习中,通过机器学习方法来确定睡眠阶段与特征参数之间的映射模型,具体为:
步骤6-1:将睡眠音频信号的非线性特征数据随机分成两个互斥集,其中一个为训练集s,另一个为交叉检验集cv,并将这些数据的睡眠阶段进行标记,即标记为a、b或c,a为清醒期,b为nrem期,c为rem期;
步骤6-2:将训练集s={(f1,l1),(f2,l2),...(fi,li),...,(fw,lw)}的特征矩阵输入机器学习方法中,其中fi=(fi1,fi2,fi3,fi4,fi5)分别为步骤5中提取的5个非线性动力学特征
步骤6-3:随机从训练集取一个样本放入采样集中,再把该样本放回初始训练集中,使得下次采样时该样本仍有可能被选中,经过w次随机采样操作后得到w个样本的采样集,重复t次,得到t组含w个训练样本的采样集;
步骤6-4:基于每个采样集的特征矩阵去训练出一个睡眠阶段分期基学习器,得到t个睡眠阶段分期基学习器,映射模型m1由这t个睡眠阶段分期基学习器组成,它采用投票法进行输出;这里的基学习器可以是决策树,具体为:
步骤6-4-1:遍历各个特征,计算其的基尼值,其公式为:
δgini(a)=gini(a)-ginia(a)
第一个公式中,数据集a为步骤6-3中w个训练样本的采样集,gini(a)表示的是数据集a的基尼指数,ri表示第i类样本在数据集a中的比例;第二个公式中,a是步骤5中得到的特征
步骤6-4-2、以步骤6-4-1生成的节点作为根节点,重复6-4-1的过程,选取新的姿态特征作为分裂条件,直至数据集a全部被划分完;
这里的基学习器也可以是多类别分类的svm,具体构建方法为:
步骤6-4-a:若含w个样本的采样集中都包含了3个睡眠阶段类别的数据,对3个睡眠阶段类别,做q次划分,这里q的取值必须大于3,每次随机划分将一部分类别划分成正类,记为(+1),另一部分类别划分为反类,记为(-1),这里每一组对应的正类和负类即为一个训练集;共产生q个训练集;
步骤6-4-b:将6-4-a生成的q个训练集分别训练svm,得到q个svm学习器,这样每一类的数据输入这q个svm学习器中得到相应的编码,组成3*q的编码矩阵;
步骤6-4-c:利用q个分类器分别对测试样本进行预测,预测标记组成一个编码,将这个编码与每个类别各自的编码进行比较,返回其中距离最小的类别作为最终预测的结果,这q个svm分类器组成了多类别分类的svm学习器;
步骤6-5:使用交叉检验集cv对睡眠阶段与特征参数之间的映射模型m1进行进一步调参优化,得到映射模型m,具体为;
步骤6-5-1、根据具体情况,确定睡眠阶段分期基学习器的参数,当睡眠阶段分期基学习器为决策树时,参数包括决策数的分裂时参与判断的最大特征数max_feature、最大深度max_depth、分裂所需的最小样本数min_samples_split;当睡眠阶段分期基学习器为多类别分类的svm时,参数为svm的惩罚参数c、核函数参数gamma。
步骤6-5-2、对每个参数进行一次直线搜索,具体为,利用cv集对基学习器进行训练,计算模型性能与参数之间的梯度;
步骤6-5-3、根据模型性能与各个参数之间的梯度,选取梯度值最大的参数作为当前调优参数,利用梯度下降法对当前调优参数进行调优;
步骤6-5-4、重复步骤6-5-2,6-5-3,直到所有参数的梯度小于阈值threshold,阈值threshold取值为0.001;
步骤6-5-5、调整睡眠阶段分期基学习器个数t,具体为:计算模型性能与t之间的梯度,利用梯度下降法对基学习器个数t进行调优,得到最终的睡眠阶段分期基学习器个数。
步骤7:根据机器学习确定的睡眠阶段与特征参数之间的映射模型m,对音频设备获取的睡眠音频信号进行睡眠阶段的分期。
实施例2
结合图1,基于非线性动力学的睡眠阶段分期的步骤如下:
步骤1:用音频设备采集监护者两整夜共841分钟的睡眠音频信号,同时记录psg仪所记录的睡眠阶段。将录取的音频信号进行降噪处理,提取较为纯净的音频信号。其中图3为整夜睡眠音频信号中的164s的音频波形图,图4为将这164s睡眠音频信号进行降噪处理后的音频波形图;
步骤2:将音频与psg的睡眠阶段标签按照对应法则一一对应;
步骤3:截取监护者从清醒到深度睡眠的一个周期的降噪后的音频信号,进行声音事件检测,周期为90min;
步骤4:检测到声音事件后,对音频进行分帧,帧长为30s,图5为将步骤1中降噪后的睡眠音频信号进行声音事件检测后的音频波形图;
步骤5:提取声音事件的非线性动力学参数,具体为:时间延迟
步骤6:将提取得到的特征参数与对应的标签输入到机器学习中,通过机器学习方法来确定睡眠阶段与特征参数之间的映射模型m1:
将五整夜2101分钟,每分钟2帧的睡眠音频信号通过步骤4进行特征提取后,组成4202个{(fi1,fi2,fi3,fi4,fi5),li}的特征矩阵,li为以psg结果作对比得到的标签。其中将2520个特征矩阵作为训练集s,1682个特征矩阵作为交叉检验集cv。将训练集s的特征矩阵输入机器学习算法中,从特征矩阵中随机取一个样本放入采样矩阵中,经过2520次随机采样操作得到含2520个样本的采样矩阵,重复20次,得20个含2520个样本的采样矩阵,然后基于每个采样矩阵去训练出一个睡眠阶段分期基学习器,这里基学习器使用的是决策树,得到20个睡眠阶段分期基学习器,利用投票法将20个基学习器所得到的结果进行结合,当预测出睡眠阶段收到同样的票数时,随机选择一个睡眠阶段,最后得到睡眠阶段与特征参数之间的映射模型m1;
步骤7、将交叉检验集cv中的1682个特征矩阵输入姿态识别映射模型m1中通过其他基学习器参数修改t的值和进一步优化姿态识别映射模型的识别精度,得到姿态识别映射模型m,其中最大特征数max_feature为12,最大深度max_depth为none,分裂所需的最小样本数min_samples_split为2。
步骤8:根据步骤7得到的映射模型m,对音频设备录取的音频信号进行睡眠阶段分期。
其中图3为机器学习分类的混淆矩阵。根据所训练的睡眠阶段与特征参数之间的映射模型,分类准确度能达到86.3%。
由此可知,基于非线性动力学的睡眠阶段分期有很高的可实施性。
- 还没有人留言评论。精彩留言会获得点赞!