比对型基因测序数据压缩方法、系统及计算机可读介质与流程
本发明涉及基因测序和数据压缩技术,具体涉及一种比对型基因测序数据压缩方法、系统及计算机可读介质。
背景技术:
近年来,随着下一代测序技术(nextgenerationsequence,ngs)的持续进步,基因测序的速度更快,成本更低,基因测序技术得以在更加广泛的生物、医疗、健康、刑侦、农业等等许多领域被推广应用,从而导致基因测序产生的原始数据量以每年3到5倍、甚至更快的速度爆炸式增长。而且,每个基因测序样本数据又很大,例如一个人的55x全基因组测序数据大约是400gb。因此,海量的基因测试数据的存储、管理、检索和传输面临技术和成本的挑战。
数据压缩(datacompression)就是缓解这个挑战的技术之一。数据压缩,是为了减少存储空间而把数据转换成比原始格式更紧凑形式的过程。原始的输入数据包含我们需要压缩或减小尺寸的符号序列。这些符号被压缩器编码,输出结果是编码过的数据。通常在之后的某个时间,编码后的数据会被输入到一个解压缩器,在这里数据被解码、重建,并以符号序列的形式输出原始数据。如果输出数据和输入数据始终完全相同,那么这个压缩方案被称为无损的(lossless),也称无损编码器。否则,它就是一个有损的(lossy)压缩方案。
目前,世界各国研究人员已经开发出多种用于基因测序数据的压缩方法。基于基因测序数据的用途,其压缩后必须随时可以重建、恢复成原始数据,因此,有实际意义的基因测序数据压缩方法都是无损压缩。如果按总的技术路线分类,可以将基因测序数据压缩方法分成三大类:通用(generalpurpose)压缩算法、有参考基因组(reference-based)的压缩算法和无参考基因组(reference-free)的压缩算法。
通用压缩算法,就是不考虑基因测序数据的特点,采用通用的压缩方法进行数据压缩。
无参考基因组压缩算法,就是不使用参考基因组,只是利用基因测序数据自身的特点,采用某种压缩方法对目标样本数据直接进行数据压缩。已有的无参考基因组压缩算法常用的压缩方法有霍夫曼编码、以lz77和lz78为代表的字典方法、算术编码等基础的压缩算法及其变种和优化。
有参考基因组压缩算法,就是选取某个基因组数据作为参考基因组,利用基因测序数据自身的特点,以及目标样本数据和参考基因组数据之间的相似性,间接进行数据压缩。已有的有参考基因组压缩算法常用的相似性表示、编码和压缩方法主要还是霍夫曼编码、以lz77和lz78为代表的字典方法、算术编码等基础的压缩算法及其变种和优化。
衡量压缩算法性能或效率的2个最常用的技术指标是:压缩率(compressionratio)或压缩比;压缩/解压时间或压缩/解压速度。压缩率=(压缩后数据大小/压缩前数据大小)x100%,压缩比=(压缩前数据大小/压缩后数据大小),即压缩率和压缩比互为倒数。压缩率和压缩比只和压缩算法本身有关,多种算法间可以直接进行比较,压缩率越小或压缩比越大,表明算法性能或效率越好;压缩/解压时间,即从读取原始数据到解压完成所需的机器运行时间;压缩/解压速度,即平均每单位时间可以处理压缩的数据量。压缩/解压时间和压缩/解压速度,既和压缩算法本身有关,也和使用的机器环境(包括硬件和系统软件)有关,因此,多种算法必须基于相同的机器环境运行,压缩/解压时间或压缩/解压速度的比较才有意义,在此前提下,压缩/解压时间越短,压缩/解压速度越快,表明算法性能或效率越好。另外,还有一个参考技术指标是运行时的资源消耗,主要是机器存储的峰值。在压缩率和压缩/解压时间相当的情况下,对存储的要求越少,表明算法性能或效率越好。
根据研究人员对已有的基因测序数据压缩方法的比较研究结果,无论是通用压缩算法、无参考基因组的压缩算法,还是有参考基因组压缩算法,都存在的问题有:1、压缩率还有进一步下降的空间;2、在获得相对较好的压缩率时,算法的压缩/解压时间相对较长,时间成本成为新的问题。此外,与通用压缩算法和无参考基因组压缩算法相比,有参考基因组压缩算法通常能获得更好的压缩率。但是,对于有参考基因组的压缩算法,参考基因组的选择会导致算法性能的稳定性问题,即处理相同的目标样本数据,当选择不同的参考基因组时,压缩算法性能可能存在明显差异;而使用相同的参考基因组选择策略,当处理同种的、不同的基因测序样本数据时,压缩算法的性能同样可能存在明显差异。尤其是对于有参考基因组压缩算法而言,如何基于参考基因组提高对基因测序数据的压缩率以及压缩性能,已经成为一项亟待解决的关键技术问题。
技术实现要素:
本发明要解决的技术问题:针对现有技术的上述问题,提供一种比对型基因测序数据压缩方法、系统及计算机可读介质,本发明的基因测序数据压缩方法是一种无损的、有参考基因组的基因测序数据压缩方法,通过将短串k-mer和参考基因组进行比对生成预测字符集ps,将读序列r的后lr-k位、预测字符集ps编码后进行可逆运算后以数据流的方式压缩输出,具有压缩率低,压缩时间短,压缩性能稳定的优点,不需要对基因数据进行精准比对,有较高的计算效率,比对准确度越高,则可逆运算结果中的重复字符串就越多,从而压缩的压缩率就越低。
为了解决上述技术问题,本发明采用的技术方案为:
一方面,本发明提供一种比对型基因测序数据压缩方法,实施步骤包括:
1)从基因测序数据样本data中遍历获取读长为lr的读序列r;
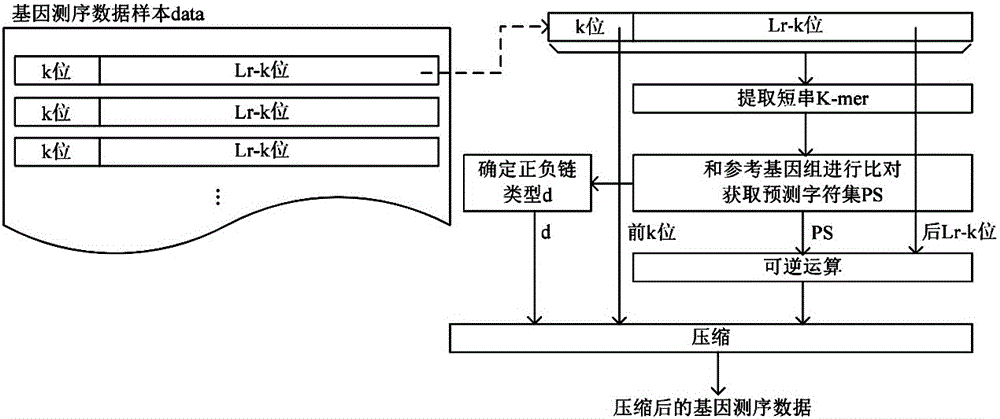
2)针对每一条读序列r,选择k位原始基因字母作为原始基因字符串cs0,从原始基因字符串cs0开始以k位长度作为滑动窗口顺序生成定长的k位字符串作为短串k-mer,依次将短串k-mer和参考基因组进行比对获取其在参考基因组的正链或负链中相邻位的预测字符c,得到由所有预测字符c构成的预测字符集ps;将读序列r中不含k位原始基因字母的lr-k位原始基因字母、预测字符集ps编码后通过可逆函数进行可逆运算,所述可逆函数将任意一对相同的字符编码的运算输出结果相同;将读序列r的正负链类型d、原始基因字符串cs0以及可逆运算结果作为三条数据流压缩输出。
优选地,步骤2)的详细步骤包括:
2.1)从基因测序数据样本data中遍历获取一条读长为lr的读序列r,针对读序列r选择k位原始基因字母作为原始基因字符串cs0,从原始基因字符串cs0开始以k位长度作为滑动窗口顺序生成长度为k的定长子字符串作为短串k-mer得到读序列短串集合kr;
2.2)针对读序列短串集合kr中的每一个短串k-mer,根据短串k-mer确定读序列r的正负链类型d,且将短串k-mer和参考基因组进行比对获取其在参考基因组的正链或负链中相邻位的预测字符c,得到由所有预测字符c构成的预测字符集ps;
2.3)将读序列r中不含k位原始基因字母的lr-k位原始基因字母、预测字符集ps编码后通过可逆函数进行可逆运算,所述可逆函数将任意一对相同的字符编码的运算输出结果相同;
2.4)将读序列r的正负链类型d、原始基因字符串cs0以及可逆运算结果作为三条数据流压缩输出;
2.5)判断基因测序数据样本data中的读序列r是否遍历完毕,如果尚未遍历完毕,则跳转执行步骤2.1);否则结束并退出。
优选地,步骤2.2)的详细步骤包括:
2.2.1)针对读序列短串集合kr顺序提取短串k-mer,通过和参考基因组的正链s1进行比对获取其在参考基因组的正链或负链中相邻位的预测字符c,所述正链s1为原始顺序的参考基因组数据本身,所述预测字符c为短串k-mer在对应的正链s1中最可能的下一个基因字符,将所有预测字符c组合得到正链预测字符序列ps1;
2.2.2)针对读序列短串集合kr顺序提取短串k-mer,通过和参考基因组的负链s2进行比对获取其在参考基因组的正链或负链中相邻位的预测字符c,所述负链s2为参考基因组数据dataref的逆序互补基因序列,所述逆序互补基因序列和参考基因组数据dataref之间碱基a和t互换、碱基c和g互换,所述预测字符c为短串k-mer在对应的负链s2中最可能的下一个基因字符,将所有预测字符c组合得到的负链预测字符序列ps2;
2.2.3)计算正链预测字符序列ps1、读序列r中不含k位原始基因字母的lr-k位原始基因字母两者之间的编辑距离l1,计算负链预测字符序列ps2、读序列r中不含k位原始基因字母的lr-k位原始基因字母两者之间的编辑距离l2;
2.2.4)判断编辑距离为l1小于l2是否成立,如果成立则判定读序列r的正负链类别d为正链、将正链预测字符序列ps1作为读序列r的预测字符集ps;否则,判定读序列r的正负链类别d为负链、将负链预测字符序列ps2作为读序列r的预测字符集ps。
优选地,步骤2)中的可逆函数具体是指xor异或函数或者位减法函数。
优选地,步骤2)中的压缩具体是指使用统计模型和熵编码进行压缩。
一方面,本发明还提供一种比对型基因测序数据压缩系统,包括计算机系统,所述计算机系统被编程以执行本发明前述的比对型基因测序数据压缩方法的步骤。
此外,本发明还提供一种计算机可读介质,所述计算机可读介质上存储有计算机程序,所述计算机程序使计算机系统执行本发明前述的比对型基因测序数据压缩方法的步骤。
本发明具有下述优点:
1、本发明的基因测序数据压缩方法是一种无损的、有参考基因组的基因测序数据压缩方法,通过将短串k-mer和参考基因组进行比对生成预测字符集ps,将读序列r的后lr-k位、预测字符集ps编码后进行可逆运算后以数据流的方式压缩输出,能够有效提升基因序列数据的压缩倍率,具有压缩率低,压缩时间短,压缩性能稳定的优点。
2、区别于现有技术使用参考序列进行基因序列精准比对后再进行数据压缩,本发明方法对通过将短串k-mer和参考基因组进行比对生成预测字符集ps时不需要对基因数据进行精准比对,有较高的计算效率,比对准确度越高,则可逆运算结果中的重复字符串就越多,从而压缩的压缩率就越低。
3、本发明方法将短串k-mer和参考基因组进行比对生成预测字符集ps时可通用各种基因测序数据比对方法,将短串k-mer和参考基因组进行比对的效率越高、精确度越高,则对应会导致压缩效率越高、压缩率越低。
附图说明
图1为本发明实施例方法的基本原理示意图。
具体实施方式
参见图1,本实施例比对型基因测序数据压缩方法的实施步骤包括:
1)从基因测序数据样本data中遍历获取读长为lr的读序列r;
2)针对每一条读序列r,选择k位原始基因字母作为原始基因字符串cs0,从原始基因字符串cs0开始以k位长度作为滑动窗口顺序生成定长的k位字符串作为短串k-mer,依次将短串k-mer和参考基因组进行比对获取其在参考基因组的正链或负链中相邻位的预测字符c,得到由所有预测字符c构成的预测字符集ps;将读序列r中不含k位原始基因字母的lr-k位原始基因字母、预测字符集ps编码后通过可逆函数进行可逆运算,所述可逆函数将任意一对相同的字符编码的运算输出结果相同;将读序列r的正负链类型d、原始基因字符串cs0以及可逆运算结果作为三条数据流压缩输出。
需要说明的是,获取相邻位的预测字符c时,相邻位的定义和选择原始基因字符串cs0的方式相关,如果选择原始基因字符串cs0为读序列r的前k位,则相邻位是指下一位;如果选择原始基因字符串cs0为读序列r的后k位,则相邻位是指上一位;如果选择原始基因字符串cs0为读序列r的中间k位,则相邻位包括上一位和下一位。参见图1,本实施例中相邻位具体指下一位,选择原始基因字符串cs0时选择前k位原始基因字母,读序列r中不含k位原始基因字母的lr-k位原始基因字母具体是指读序列r中的lr-k位原始基因字母。
本实施例中,步骤2)的详细步骤包括:
2.1)从基因测序数据样本data中遍历获取一条读长为lr的读序列r,针对读序列r选择k位原始基因字母作为原始基因字符串cs0,从原始基因字符串cs0开始以k位长度作为滑动窗口顺序生成长度为k的定长子字符串作为短串k-mer得到读序列短串集合kr;
2.2)针对读序列短串集合kr中的每一个短串k-mer,根据短串k-mer确定读序列r的正负链类型d,且将短串k-mer和参考基因组进行比对获取其在参考基因组的正链或负链中相邻位的预测字符c,得到由所有预测字符c构成的预测字符集ps;
2.3)将读序列r中不含k位原始基因字母的lr-k位原始基因字母、预测字符集ps编码后通过可逆函数进行可逆运算,所述可逆函数将任意一对相同的字符编码的运算输出结果相同;
2.4)将读序列r的正负链类型d、原始基因字符串cs0以及可逆运算结果作为三条数据流压缩输出;
2.5)判断基因测序数据样本data中的读序列r是否遍历完毕,如果尚未遍历完毕,则跳转执行步骤2.1);否则结束并退出。
本实施例中,步骤2.2)的详细步骤包括:
2.2.1)针对读序列短串集合kr顺序提取短串k-mer,通过和参考基因组的正链s1进行比对获取其在参考基因组的正链或负链中相邻位的预测字符c,所述正链s1为原始顺序的参考基因组数据本身,所述预测字符c为短串k-mer在对应的正链s1中最可能的下一个基因字符,将所有预测字符c组合得到正链预测字符序列ps1;
2.2.2)针对读序列短串集合kr顺序提取短串k-mer,通过和参考基因组的负链s2进行比对获取其在参考基因组的正链或负链中相邻位的预测字符c,所述负链s2为参考基因组数据dataref的逆序互补基因序列,所述逆序互补基因序列和参考基因组数据dataref之间碱基a和t互换、碱基c和g互换,所述预测字符c为短串k-mer在对应的负链s2中最可能的下一个基因字符,将所有预测字符c组合得到的负链预测字符序列ps2;
2.2.3)计算正链预测字符序列ps1、读序列r中不含k位原始基因字母的lr-k位原始基因字母两者之间的编辑距离l1,计算负链预测字符序列ps2、读序列r中不含k位原始基因字母的lr-k位原始基因字母两者之间的编辑距离l2;
2.2.4)判断编辑距离为l1小于l2是否成立,如果成立则判定读序列r的正负链类别d为正链、将正链预测字符序列ps1作为读序列r的预测字符集ps;否则,判定读序列r的正负链类别d为负链、将负链预测字符序列ps2作为读序列r的预测字符集ps。
本实施例中,步骤2)中的可逆函数具体是指xor异或函数。本实施例中,a、c、g、t四种基因字母分别被编码为00、01、10和11四种字符编码,例如某一位基因字母为a,而预测字符c同样为a,则该位的xor异或操作结果(可逆运算结果)为00,否则xor异或操作结果根据预测字符c不同而有所不同;在解压时,针对预测字符c的字符编码和xor异或操作结果(可逆运算结果)再进行xor异或操作(通过可逆函数的反函数进行逆向操作),即可复原得到原始的基因字母。将a、c、g、t四种基因字母分别被编码为00、01、10和11四种字符编码是一种优选的比较精简的编码方式,此外也可以根据需要采用其他的二进制编码方式,同样也可以实现基因字母、预测字符、可逆运算结果三者的可逆转换。毫无疑问,除了xor异或函数以外,可逆函数也可以采用位减法函数,此时则可逆函数的反函数为位加法函数,同样也可以实现基因字母、预测字符、可逆运算结果三者的可逆转换。
本实施例中,步骤2)中的压缩具体是指使用统计模型和熵编码进行压缩。
本实施例还提供一种比对型基因测序数据压缩系统,包括计算机系统,计算机系统被编程以执行本实施例前述基因测序数据压缩方法的步骤,在此不再赘述。此外,本实施例还提供一种计算机可读介质,计算机可读介质上存储有计算机程序,计算机程序使计算机执行本实施例前述种比对型基因测序数据压缩方法的步骤,在此不再赘述。
以上所述仅是本发明的优选实施方式,本发明的保护范围并不仅局限于上述实施例,凡属于本发明思路下的技术方案均属于本发明的保护范围。应当指出,对于本技术领域的普通技术人员来说,在不脱离本发明原理前提下的若干改进和润饰,这些改进和润饰也应视为本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!